







简介:优先级队列是Java中一种特殊的数据结构,主要用于管理有优先级的元素集合,支持高效的插入和删除操作。本文深入探讨了小根堆作为优先级队列的实现原理,包括Java内置的 PriorityQueue 类的使用和自定义小根堆的构建步骤。文章详细介绍了小根堆的基本概念、如何使用内置优先级队列类、自定义实现方法、源码分析以及在不同场景下的应用。通过理解小根堆的工作原理,开发者能够更高效地解决问题,并优化代码性能。 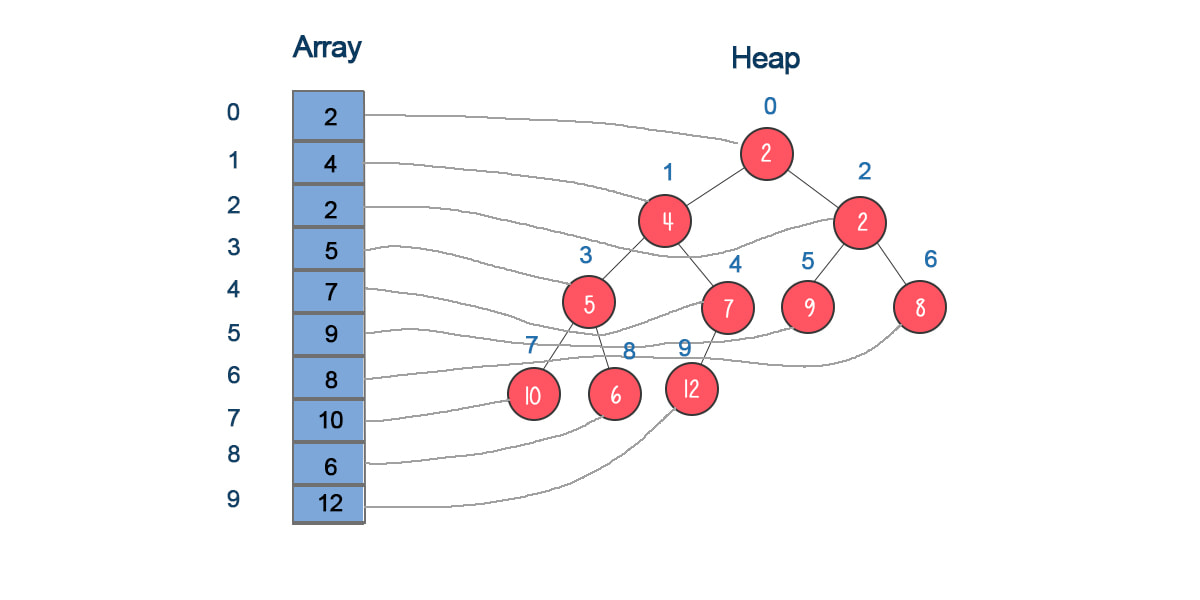
1. 小根堆的概念及在Java中的表现形式
1.1 小根堆的定义和特性
在数据结构的世界里,小根堆(Min-Heap)是一种特殊的完全二叉树,它具备以下特性:每个节点的值都小于或等于其子节点的值,保证了堆顶元素是所有节点中的最小值。小根堆用于实现优先级队列等数据结构,是算法设计中常用的构建块。
1.2 小根堆在Java中的实现
在Java中,小根堆并没有一个直接对应的类,但是可以通过自定义实现或者利用现有的 PriorityQueue 类来间接体验小根堆的功能。 PriorityQueue 默认实现是小根堆的性质,即每次从队列中取出的元素都是优先级最高的(即最小的)元素。
1.3 小根堆与PriorityQueue的联系
在实现优先级队列时,小根堆提供了强大的理论支撑。而Java中的 PriorityQueue 类就是基于堆的概念实现的。通过 PriorityQueue 的实例,开发者可以在Java中轻松实现复杂的优先级管理,而无需深入理解堆的内部工作机制。这种抽象为开发者提供了极大的便利,同时也隐藏了实现细节的复杂性。
import java.util.PriorityQueue;
public class MinHeapExample {
public static void main(String[] args) {
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
minHeap.offer(3);
minHeap.offer(1);
minHeap.offer(6);
System.out.println("Poll the smallest element: " + minHeap.poll()); // 输出: 1
}
}
在上述代码中,我们使用 PriorityQueue 模拟小根堆的行为,通过 offer 方法添加元素,并使用 poll 方法取出最小元素。这种操作模式正是小根堆在实际应用中的一个缩影。
2. Java内置 PriorityQueue 类的功能和使用方法
2.1 PriorityQueue的内部结构和基本操作
2.1.1 PriorityQueue的构造函数和数据结构
PriorityQueue 类是Java Collections Framework中的一个关键组件,它基于优先级堆实现。优先级堆是一种特殊类型的完全二叉树,其中每个父节点的值都不大于(或不小于)任何子节点的值。在小根堆中,父节点的值总是小于等于其子节点的值。
PriorityQueue 的主要构造函数如下:
-
PriorityQueue(): 创建一个初始容量为11的优先队列,使用自然顺序排序。 -
PriorityQueue(int initialCapacity): 创建一个指定容量的优先队列,使用自然顺序排序。 -
PriorityQueue(Comparator<? super E> comparator): 创建一个默认初始容量(11)的优先队列,使用指定的比较器排序。 -
PriorityQueue(int initialCapacity, Comparator<? super E> comparator): 创建一个具有指定初始容量的优先队列,并使用指定的比较器排序。
内部结构上, PriorityQueue 使用一个可调整大小的数组来实现堆结构,以保证高效的插入和删除最小元素操作。
private transient Object[] queue; // non-private to simplify nested class access
构造函数将根据提供的参数配置堆的初始状态,例如,初始化容量和比较器。
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
public PriorityQueue(int initialCapacity) {
this(initialCapacity, null);
}
public PriorityQueue(Comparator<? super E> comparator) {
this(DEFAULT_INITIAL_CAPACITY, comparator);
}
public PriorityQueue(int initialCapacity, Comparator<? super E> comparator) {
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
2.1.2 PriorityQueue的基本操作方法
PriorityQueue 提供了多个基本操作方法,包括插入元素( offer )、删除最小元素( remove 或 poll )、获取最小元素( peek 或 element )等。
-
boolean offer(E e): 将指定元素添加到此优先队列中。 -
E remove(): 删除并返回此队列的头部元素。 -
E poll(): 获取并移除此队列的头部元素,如果此队列为空,则返回null。 -
E peek(): 检索但不删除此队列的头部元素,如果此队列为空,则返回null。 -
boolean isEmpty(): 如果此队列不包含元素,则返回true。 -
boolean contains(Object o): 如果此队列包含指定的元素,则返回true。
例如, offer 方法将元素插入堆中,然后调整堆结构以维持优先级堆的性质:
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
siftUp 方法保证了新加入的元素在堆中正确的位置:
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
PriorityQueue 通过保持堆的性质来确保每次可以从队列中快速访问到最小元素,这种数据结构非常适合优先级调度场景。
2.2 PriorityQueue的高级特性
2.2.1 比较器Comparator的使用
PriorityQueue 允许通过 Comparator 接口自定义元素的比较规则,这对于不支持自然排序的对象集合特别有用。
例如,如果想要创建一个根据对象属性而不是自然顺序来排序的 PriorityQueue ,可以如下操作:
PriorityQueue<Item> pq = new PriorityQueue<>(new Comparator<Item>() {
public int compare(Item a, Item b) {
return Integer.compare(a.priority, b.priority);
}
});
这段代码中创建了一个优先队列,其中 Item 类的实例根据它们的 priority 属性排序。通过比较器,可以实现任何复杂的比较逻辑,使得优先级队列更加灵活。
2.2.2 PriorityQueue与Collection接口的交互
PriorityQueue 实现了 Collection 和 Iterable 接口,意味着它遵循Java集合框架的基本规范。因此,它支持通过迭代器来遍历队列中的元素,但是迭代器并不保证按优先级顺序返回元素。
Iterator<E> iterator() {
return new Itr();
}
迭代器的实现是必要的,因为它允许用户顺序访问队列中的元素,尽管不是按照优先级排序的。
2.3 PriorityQueue的应用实例分析
2.3.1 任务调度中的应用
在任务调度系统中,经常需要处理具有不同优先级的任务。 PriorityQueue 可以用来按照任务优先级顺序来管理这些任务。
例如,一个简单的任务调度器可以表示为:
PriorityQueue<Task> tasks = new PriorityQueue<>();
tasks.offer(new Task("任务1", 1)); // 优先级1为最高优先级
tasks.offer(new Task("任务2", 3));
tasks.offer(new Task("任务3", 2));
while (!tasks.isEmpty()) {
Task task = tasks.poll();
execute(task);
}
在这个例子中,任务按优先级顺序执行,优先级高的任务先执行。
2.3.2 事件驱动程序中的应用
在事件驱动的程序设计中,事件处理器经常需要根据事件类型或其它标准进行排序。 PriorityQueue 可以作为事件队列来存储待处理的事件。
考虑一个事件监听器:
PriorityQueue<Event> events = new PriorityQueue<>();
public void addEvent(Event event) {
events.offer(event);
}
public void processEvents() {
while (!events.isEmpty()) {
Event event = events.poll();
handle(event);
}
}
在这个场景下,事件根据优先级(或事件类型)被插入队列,并按此顺序处理。这样可以确保优先级高的事件能够被及时处理。
3. 自定义小根堆的实现方式及其操作步骤
3.1 小根堆的节点表示和堆化过程
3.1.1 节点类的定义和属性
在小根堆中,每个节点都包含一个值,该值用于与其他节点进行比较。此外,由于堆通常表示为数组,节点还应包含其在数组中的位置信息,以便快速访问其父节点和子节点。在Java中,我们可以创建一个简单的节点类来表示小根堆的节点。
class Node {
private int value;
private int index;
public Node(int value, int index) {
this.value = value;
this.index = index;
}
public int getValue() {
return value;
}
public int getIndex() {
return index;
}
// Other methods like setters and getters if needed
}
3.1.2 堆化(heapify)算法的实现步骤
堆化是小根堆中的一项关键技术,它确保堆保持堆的性质。堆化通常在添加新元素或者删除最小元素后进行。在Java中,我们可以实现一个堆化函数,它从给定的节点开始,向上或向下调整堆,直到满足小根堆的性质。
void heapify(int heap[], int size, int i) {
int smallest = i; // Initialize smallest as root
int left = 2 * i + 1; // left child
int right = 2 * i + 2; // right child
// If left child exists and is smaller than root
if (left < size && heap[left] < heap[smallest])
smallest = left;
// If right child exists and is smaller than smallest so far
if (right < size && heap[right] < heap[smallest])
smallest = right;
// If smallest is not root
if (smallest != i) {
int temp = heap[i];
heap[i] = heap[smallest];
heap[smallest] = temp;
// Recursively heapify the affected sub-tree
heapify(heap, size, smallest);
}
}
3.2 小根堆的主要操作实现
3.2.1 插入元素和调整堆的过程
当向小根堆中插入一个新元素时,我们需要先将其添加到堆的末尾,然后通过堆化过程来重新调整堆。
public void insert(int value) {
heap[size] = new Node(value, size);
int current = size;
size++;
// Heapify up
while (current != 0 && heap[current].getValue() < heap[parent(current)].getValue()) {
swap(current, parent(current));
current = parent(current);
}
}
3.2.2 删除最小元素和堆的调整
删除小根堆的最小元素(根节点)后,我们通常会将堆的最后一个元素移动到根位置,然后执行堆化操作以重新建立堆的性质。
public int deleteMin() {
if (size <= 0) return Integer.MIN_VALUE;
if (size == 1) {
size--;
return heap[0].getValue();
}
int root = heap[0].getValue();
heap[0] = heap[--size];
heapify(heap, size, 0);
return root;
}
3.3 自定义小根堆与PriorityQueue的对比
3.3.1 性能分析和应用场景的差异
小根堆和Java内置的PriorityQueue都提供了优先级队列的功能,但它们在性能和内存使用方面存在差异。自定义的小根堆通常在逻辑实现上更清晰,便于理解堆的工作原理。然而,PriorityQueue提供了一些优化,如动态扩容,以及更好地与Java的集合框架集成。
3.3.2 自定义小根堆的优势和限制
自定义小根堆的主要优势在于它提供了一个学习堆结构及其操作的良好平台。然而,它的限制在于可能不具备PriorityQueue的高级特性,如线程安全性和更复杂的优先级管理功能。
通过本节的探讨,我们已经深入了解了如何手动实现小根堆的基本操作。我们知道了节点类的设计,插入和删除操作的堆化过程,以及它与内置PriorityQueue类的对比。在下一节中,我们将分析PriorityQueue类的源码以深入理解其内部实现细节。
4. 分析 PriorityQueue 类的源码以深入理解实现细节
4.1 PriorityQueue源码的结构解析
4.1.1 源码中的关键数据结构分析
在深入到Java中 PriorityQueue 类的源码之前,了解其关键数据结构是必不可少的。 PriorityQueue 通常内部使用数组来存储元素,数组的起始位置为0。然而,它并不总是保持数组的顺序,而是根据元素的优先级来维护顺序。
private transient Object[] queue; // non-private to simplify nested class access
源码中的 queue 数组是实现优先队列的核心。为了保持堆的特性, PriorityQueue 会使用一种特殊的数据结构——二叉堆。在二叉堆中,对于任何非叶子节点 i ,其值总是小于或等于其子节点的值。在小根堆中,父节点的值小于等于其两个子节点的值。这样,当我们将元素插入队列时,我们可以通过上浮(sift-up)和下沉(sift-down)操作来调整堆,以确保堆的顺序。
4.1.2 构造函数和初始化过程的源码解读
构造函数在 PriorityQueue 的初始化中扮演着重要角色,它负责创建存储数据的数组,并根据需要初始化其他相关变量。
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
在上述代码段中,构造函数接受初始容量和一个可选的比较器。初始容量用于设置数组的大小,而比较器用于定义元素的优先级顺序。构造函数首先验证初始容量是否至少为1,然后创建一个相应大小的数组,并将比较器存储在类的实例变量中。
4.2 PriorityQueue核心操作的源码分析
4.2.1 offer和poll方法的实现原理
offer 方法用于将一个新元素添加到优先队列中。它首先检查队列是否已满,然后在数组的末尾插入该元素,并通过上浮操作调整元素位置,以维持小根堆的特性。
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
poll 方法从优先队列中移除并返回最小元素。如果队列为空,它将返回 null 。否则,它将把队列的最后一个元素移动到第一个位置,然后通过下沉操作调整剩余元素,以重新建立小根堆。
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);
return result;
}
4.2.2 peek方法和迭代器的源码探究
peek 方法返回但不移除优先队列的头部元素(即最小元素)。这个操作的实现非常简单,因为小根堆的根节点(数组的第一个元素)总是最小的元素。
public E peek() {
return (size == 0) ? null : (E) queue[0];
}
PriorityQueue 的迭代器是弱一致性的,这意味着它可以在迭代过程中进行结构性修改,但它不会抛出 ConcurrentModificationException 。迭代器需要在遍历过程中正确处理可能发生的结构性修改,例如通过引用跟踪来判断元素是否被删除。
public Iterator<E> iterator() {
return new Itr();
}
迭代器 Itr 使用 expectedModCount 字段来跟踪队列的预期修改次数。这允许迭代器在检测到结构性修改时能够抛出 ConcurrentModificationException 。
4.3 PriorityQueue源码中的异常处理和同步机制
4.3.1 并发环境下的线程安全分析
PriorityQueue 本身不是线程安全的,如果需要在多线程环境下使用,必须确保外部同步。在并发环境中,如果不进行外部同步,可能会导致数据不一致或不可预见的行为。对于线程安全的优先队列实现,可以考虑使用 PriorityBlockingQueue 或者 ConcurrentLinkedQueue 。
4.3.2 源码中的异常处理机制
PriorityQueue 的异常处理体现在多个方法中,特别是在 offer 和 poll 等核心方法中。它通过抛出合适的异常来通知调用者发生了错误情况。例如,如果尝试插入 null 值到优先队列中, offer 方法会抛出 NullPointerException 。
if (e == null)
throw new NullPointerException();
异常处理机制确保了方法的健壮性,使得在使用中能够快速定位问题,防止错误悄无声息地传播。
以上就是 PriorityQueue 类源码中的关键实现细节的深入分析,帮助理解其内部工作原理以及如何安全有效地使用Java中的优先队列。
5. 利用调试工具辅助学习小根堆的工作原理
5.1 调试工具的选择和配置
选择适合的IDE和调试工具
在学习小根堆的工作原理时,使用调试工具可以让我们更直观地理解其内部机制。对于Java开发者来说,选择一个集成开发环境(IDE)中的调试工具是十分重要的。通常,IntelliJ IDEA、Eclipse 或 NetBeans 等IDE都内置了强大的调试工具,这些工具提供了代码执行的可视性、断点设置、变量监视等功能。
选择IDE时,需考虑个人偏好、社区支持以及插件生态系统。IntelliJ IDEA是业界广受好评的IDE,其调试工具直观且功能全面,是许多Java开发者的首选。
调试环境的搭建和配置
在选择了合适的IDE后,接下来是配置调试环境。首先,需要创建一个Java项目,并将小根堆相关的类代码添加到项目中。然后,为需要观察执行流程的代码行设置断点。在IntelliJ IDEA中,可以通过点击代码行号旁边的边缘来添加断点。
设置断点后,需要配置运行/调试配置。这包括指定JVM参数、设置程序的入口点(主类和main方法)。调试时,可以通过调整调试工具栏上的选项来控制程序的执行步骤、查看和修改变量值等。
代码块演示:
// 示例代码片段,设置断点进行调试
public class SmallHeapDemo {
public static void main(String[] args) {
SmallHeap heap = new SmallHeap();
heap.insert(5);
heap.insert(3);
heap.insert(10);
heap.insert(1);
// 此处设置断点,观察堆中的元素
heap.extractMin();
}
}
5.2 调试过程中的关键点观察
插入和删除操作的断点调试
在调试小根堆的插入(insert)和删除(deleteMin)操作时,关键是要观察堆中元素的变化。通过在这些操作的关键代码行设置断点,我们可以逐步执行代码,并在每次执行后查看堆的状态。
在调试插入操作时,我们主要关注的是如何保持小根堆的性质——即任何节点的值都不大于其父节点的值。在执行删除操作时,我们则需关注如何重新组织堆,以找到新的最小元素。
堆结构变化的动态跟踪
调试过程中动态跟踪堆结构的变化是理解小根堆工作原理的关键。可以利用IDE提供的可视化工具,如变量监视窗口或特定于堆数据结构的插件,来直观地观察堆中元素的层级关系。
此外,还可以使用自定义的打印语句或日志记录功能,将堆的变化记录下来。这样,即使在没有调试器的情况下,也能追踪堆的变化。
代码块演示:
// 在插入或删除操作后,添加日志输出
public void insert(int element) {
// ... 插入元素代码逻辑
// 执行堆化操作
heapifyUp(size);
logHeapState(); // 调用记录堆状态的方法
}
public void extractMin() {
// ... 删除最小元素代码逻辑
logHeapState(); // 调用记录堆状态的方法
}
private void logHeapState() {
// 假设有一个方法可以打印堆的结构,例如递归遍历
printHeapStructure(0, -1); // 从根节点开始打印
}
5.3 调试技巧和问题诊断
常见问题的调试策略
在使用调试工具辅助学习时,了解一些常见的调试策略是很有帮助的。例如,当小根堆的某个操作没有按预期工作时,可以尝试以下步骤:
- 回溯执行:从出错的代码行开始逐步向前回溯执行,寻找错误发生的原因。
- 分而治之:将大问题分解为小问题,逐一排查,比如先检查插入操作,再检查删除操作。
- 使用打印语句或日志记录:在代码的关键位置添加打印语句,记录程序运行过程中的重要信息。
- 利用IDE的多线程调试功能:如果遇到并发问题,可以使用IDE的多线程调试功能来观察各个线程的执行状态。
调试过程中的性能考虑
在进行调试时,应注意调试过程对程序性能的影响。过多的断点和日志记录可能会导致程序运行缓慢。因此,在调试完毕后,应去掉那些仅用于调试的断点和日志代码,以避免影响程序的性能。
调试的目的是为了理解程序的运行逻辑和排查问题,并非最终的程序执行。在最终部署的代码中,应确保移除所有调试相关的代码,以保持程序的整洁和效率。
代码块演示:
// 示例:移除日志记录的调试代码
public void insert(int element) {
// ... 插入元素代码逻辑
// 执行堆化操作,无需打印操作
heapifyUp(size);
// 移除logHeapState();
}
通过本章节的介绍,我们了解了如何通过调试工具来辅助学习小根堆的工作原理。通过合理设置断点和观察变量变化,我们可以逐步揭开小根堆的神秘面纱,理解其高效的堆操作背后的秘密。
6. 探索优先级队列在不同场景下的应用案例
在本章中,我们将深入探讨优先级队列在不同领域内的具体应用案例,展示其在解决复杂问题时的强大功能和灵活性。我们将通过详细的实例分析,了解如何在操作系统、软件工程以及数据科学等多个领域中应用优先级队列,以及其在各个场景中的工作原理和优化策略。
6.1 优先级队列在操作系统中的应用
在操作系统中,优先级队列通常被用于任务调度和资源管理。它们允许系统根据任务的重要性或紧急程度来进行处理,从而更高效地分配有限的系统资源。
6.1.1 作业调度中的应用
在作业调度系统中,优先级队列可以帮助操作系统决定哪个作业应该首先获得CPU的执行时间。这通常基于作业的优先级,优先级较高的作业会更早得到处理。这在处理实时任务时尤其重要,例如,在实时操作系统中,保证关键任务的及时执行对于系统稳定性和性能至关重要。
// 示例:使用PriorityQueue进行作业调度
PriorityQueue<Job> jobQueue = new PriorityQueue<>(new Comparator<Job>() {
@Override
public int compare(Job j1, Job j2) {
// 以作业优先级为标准进行排序,优先级高的优先
return Integer.compare(j2.getPriority(), j1.getPriority());
}
});
// 添加作业到队列中
jobQueue.offer(new Job("作业1", 1));
jobQueue.offer(new Job("作业2", 3));
jobQueue.offer(new Job("作业3", 2));
// 按优先级处理作业
while (!jobQueue.isEmpty()) {
Job job = jobQueue.poll(); // 取出优先级最高的作业执行
// 执行作业...
}
通过上述示例代码,我们可以看到如何利用 PriorityQueue 的排序功能,根据自定义的比较逻辑,来模拟作业调度的场景。
6.1.2 实时系统中的消息处理
实时系统需要在限定的时间内对事件做出响应。在这种系统中,优先级队列可以用来管理事件的处理顺序。当事件到达时,它们被加入到优先级队列中,系统根据事件的紧急程度来决定处理顺序。
// 示例:使用PriorityQueue处理实时消息
PriorityQueue<Message> messageQueue = new PriorityQueue<>(new Comparator<Message>() {
@Override
public int compare(Message m1, Message m2) {
// 以消息紧急程度为标准进行排序
return Integer.compare(m2.getUrgency(), m1.getUrgency());
}
});
// 消息到达时加入队列
messageQueue.offer(new Message("紧急消息", 5));
messageQueue.offer(new Message("普通消息", 3));
messageQueue.offer(new Message("重要消息", 4));
// 处理消息
while (!messageQueue.isEmpty()) {
Message message = messageQueue.poll(); // 取出紧急程度最高的消息处理
// 处理消息...
}
在此代码段中,消息对象根据它们的紧急程度排序,保证了最紧急的消息能够被优先处理。
6.2 优先级队列在软件工程中的应用
在软件工程领域,优先级队列不仅用于任务调度,而且在设计复杂的事件驱动程序时发挥着重要作用。
6.2.1 事件驱动程序的优先级处理
在图形用户界面(GUI)或者网络服务器等事件驱动程序中,事件通常需要按照特定的优先级顺序来处理。例如,在网络服务器中,紧急的事件如连接断开、硬件故障等,可能需要立即得到处理,而不是等待普通事件的队列。
// 示例:使用PriorityQueue处理事件
PriorityQueue<Event> eventQueue = new PriorityQueue<>(new Comparator<Event>() {
@Override
public int compare(Event e1, Event e2) {
// 以事件的紧急程度为标准进行排序
return Integer.compare(e2.getUrgency(), e1.getUrgency());
}
});
// 添加事件到队列
eventQueue.offer(new Event("普通事件", 3));
eventQueue.offer(new Event("紧急事件", 5));
eventQueue.offer(new Event("重要事件", 4));
// 处理事件
while (!eventQueue.isEmpty()) {
Event event = eventQueue.poll();
// 根据事件类型和紧急程度执行相应处理...
}
通过这种机制,事件驱动程序可以根据事件的重要程度来决定处理的优先级,确保关键事件能够得到及时处理。
6.2.2 任务管理系统中的应用
任务管理系统,如项目管理软件或个人任务管理工具中,常使用优先级队列来组织和显示任务。通过这种方式,用户可以更容易地识别和处理最重要或最紧迫的任务。
graph TD
A[任务管理系统] -->|添加任务| B(任务队列)
B --> C[按优先级排序]
C --> D[展示任务列表]
D --> E[用户选择任务进行处理]
在上面的mermaid流程图中,展示了优先级队列如何被整合进任务管理系统中。首先,任务被添加到队列,然后按照优先级排序,最终用户通过展示的任务列表来选择和处理任务。
6.3 优先级队列在数据科学中的应用
在数据科学领域,优先级队列不仅用于管理任务,还可以用于优化数据处理流程和算法。
6.3.1 排序算法优化的实践
在某些排序算法中,如堆排序,优先级队列是核心数据结构。堆排序利用了小根堆或大根堆的特性,来高效地对数据进行排序。通过优先级队列,可以轻松地实现高效排序。
// 示例:使用PriorityQueue进行堆排序
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
// 将所有元素加入到队列中
for (int num : array) {
minHeap.offer(num);
}
// 排序
int[] sortedArray = new int[minHeap.size()];
for (int i = 0; i < sortedArray.length; i++) {
sortedArray[i] = minHeap.poll(); // 弹出队列中的最小元素
}
// 此时,sortedArray数组已经有序
通过这个示例,我们可以看到如何利用优先级队列来实现堆排序。这种方法在处理大量数据时尤其高效。
6.3.2 优先级队列在大数据处理中的角色
在大数据处理中,优先级队列可以帮助处理流数据,例如,在流式处理框架中,优先级队列可以用来维护窗口内的事件或者数据点。具有更高优先级的数据会被优先处理,这对于保证数据处理的实时性和准确性非常重要。
// 示例:使用PriorityQueue进行大数据流处理
PriorityQueue<DataPoint> dataPointQueue = new PriorityQueue<>(new Comparator<DataPoint>() {
@Override
public int compare(DataPoint dp1, DataPoint dp2) {
// 以数据点的权重(例如时间戳或重要性)作为比较标准
return Long.compare(dp2.getWeight(), dp1.getWeight());
}
});
// 处理流数据,根据优先级加入队列
dataPointQueue.offer(new DataPoint("数据点1", 1578239200000L, 100));
dataPointQueue.offer(new DataPoint("数据点2", 1578239201000L, 50));
dataPointQueue.offer(new DataPoint("数据点3", 1578239202000L, 150));
// 处理队列中的数据点
while (!dataPointQueue.isEmpty()) {
DataPoint dp = dataPointQueue.poll();
// 根据数据点信息进行相应处理...
}
在这个例子中, DataPoint 对象根据它们的时间戳或者重要性排序,从而保证在处理数据流时,最重要的数据点优先被处理。
通过以上案例分析,我们可以看到优先级队列在不同场景下的应用。无论是操作系统中的作业调度、软件工程中的事件处理、任务管理,还是数据科学中的排序和大数据处理,优先级队列都发挥着重要的作用。优先级队列的高效性和灵活性使得它成为IT行业中不可或缺的一部分,广泛应用于各种复杂的系统设计和数据处理中。
7. 总结与展望
7.1 小根堆和优先级队列的理论总结
7.1.1 理论知识的回顾和深化
在本系列文章中,我们首先介绍了小根堆的概念,并探讨了其在Java中的表现形式。小根堆是一种特殊的数据结构,特别适合用于实现优先级队列,它保证了在任何时候,堆顶元素都是所有元素中最小的,这为许多需要优先处理最小元素的场景提供了理论基础。紧接着,我们深入到Java内置的 PriorityQueue 类,学习了其丰富的功能和灵活的使用方法,包括如何与 Comparator 比较器结合来定制排序规则,以及 PriorityQueue 如何与Java集合框架中的其他接口交互。
在进一步理解小根堆的操作和实现方面,我们探讨了自定义小根堆的节点表示和堆化过程,以及如何实现插入、删除等主要操作。通过和 PriorityQueue 的对比,我们分析了在不同的应用场景下,自定义小根堆与Java内置优先级队列之间的性能和限制差异。
7.1.2 Java中实现优先级队列的最佳实践
Java的 PriorityQueue 类是优先级队列实现的黄金标准,通过源码的分析,我们了解到了其底层的实现细节,包括数据结构的选择、初始化过程,以及核心操作如 offer 、 poll 和 peek 等方法的原理。通过这样的分析,我们可以更加熟练地在实际开发中运用这一数据结构,并根据需要调整和优化其性能。
通过调试工具的使用,我们能够更直观地看到小根堆或 PriorityQueue 在插入、删除元素时堆结构的变化,以及如何处理异常和实现线程安全。借助调试工具,开发者可以更加细致地掌握这些数据结构的工作原理,从而提高编码和问题诊断的效率。
7.2 未来的发展趋势和潜在应用
7.2.1 优先级队列技术的未来发展方向
随着技术的不断进步,优先级队列的应用场景也在不断拓展。在传统的多任务处理、事件驱动系统等领域之外,我们看到了优先级队列在新兴技术中的身影,如在云计算、大数据处理和机器学习中管理任务和资源。可以预见,优先级队列未来的发展会更加注重性能优化,尤其是在处理大规模数据时的可伸缩性和效率。
7.2.2 探讨优先级队列在新兴领域的应用前景
当前,优先级队列在物联网、智能交通系统、实时分析等领域已经开始得到应用。这些领域需要快速响应系统事件,优先级队列正好可以按照预定的优先级处理这些事件。随着物联网设备数量的剧增以及数据实时处理的需求不断上升,优先级队列技术有望在实现高效资源管理和任务调度方面扮演更加关键的角色。
随着计算能力的提升和算法的优化,未来优先级队列可能会结合人工智能算法,实现更加智能化的资源分配和任务处理,从而在提高效率的同时降低延迟,为用户带来更加流畅和快速的服务体验。此外,随着区块链技术的发展,优先级队列也可能在去中心化系统中找到新的应用场景,实现更高效、更安全的数据处理和交易验证机制。
本系列文章从理论到实践,从基本概念到深入源码,再到应用场景的探索,我们全面地学习了小根堆和优先级队列的各个方面。通过这些知识的积累和应用,希望读者能够将这些宝贵的数据结构运用到实际问题解决中,创造出更加高效和智能的软件系统。
简介:优先级队列是Java中一种特殊的数据结构,主要用于管理有优先级的元素集合,支持高效的插入和删除操作。本文深入探讨了小根堆作为优先级队列的实现原理,包括Java内置的 PriorityQueue 类的使用和自定义小根堆的构建步骤。文章详细介绍了小根堆的基本概念、如何使用内置优先级队列类、自定义实现方法、源码分析以及在不同场景下的应用。通过理解小根堆的工作原理,开发者能够更高效地解决问题,并优化代码性能。

















 5946
5946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









