







 本文介绍了基于MATLAB的硬币识别方法,通过边缘信息检测初步识别后,利用旋转不变的区域二值模式(RRBP)提高准确率。在处理旋转和光照变化时,LBP方法展现出稳定性。通过计算梯度图像、扇区划分、求均值等步骤,结合汉明距离计算不同模式间的相似度,实现45.5%的识别准确率。尽管低于论文中的89.1%,但在实际应用场景中仍面临光照不佳、数据量小等问题,为硬币识别提供了一个基础方案。
本文介绍了基于MATLAB的硬币识别方法,通过边缘信息检测初步识别后,利用旋转不变的区域二值模式(RRBP)提高准确率。在处理旋转和光照变化时,LBP方法展现出稳定性。通过计算梯度图像、扇区划分、求均值等步骤,结合汉明距离计算不同模式间的相似度,实现45.5%的识别准确率。尽管低于论文中的89.1%,但在实际应用场景中仍面临光照不佳、数据量小等问题,为硬币识别提供了一个基础方案。
书接上回,经过自动检测和裁剪之后,已经有很多切割整齐的硬币照片了,再来看看相似检测的方法。
一开始的思路极其简单,既然前面做了边缘提取,而对于硬币的种类,人眼最关心的也是和轮廓、花纹相关的信息。那就利用边缘信息来检测,怎么检测呢?
拿待检测的图的边缘,和所有标准图的边缘一个一个叠起来比较,和谁重合的面积越大,就和谁最像。虽然这个思路简单到小学二年级的同学都会笑出声,但这个方法在使用得当的时候,准确率可以高达40%(不行还是太弱了)
设待检测的图像的边缘信息为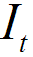 ,n个标准图像的边缘信息为
,n个标准图像的边缘信息为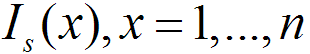 ,这里要求和
,这里要求和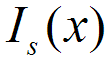 图像尺寸均一致。这样,与待测图像最接近的标准图像为。
图像尺寸均一致。这样,与待测图像最接近的标准图像为。
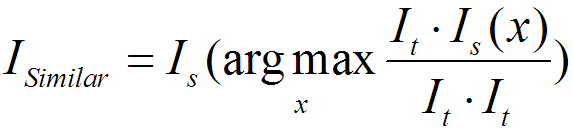
说人话:就是看看标准图和测试图重合区域的面积,哪个面积越接近测试图像的面积,就是最相像的标准图像(为了防止混乱,这里强调一下,“面积”指的是图片里白色区域的面积,或者说白色像素块的数量。这里涉及的图都是只有黑色和白色两个颜色的)。

老潘用手工方式标注了200个硬币配对,在这上面做点简单测试,这种方法准确率只有8%,经过观察大部分硬币图片都被识别成了这两个

这时候我有一个猜测,如果某个标准图像非常极端的全部为白色,那么待测图像和标准图像的重合范围肯定是非常大的(重合范围就是100%的待测图像),所以上面的方法需要改一下。必须同时考虑测试图和标准图。这里将 的判别方法改写为
的判别方法改写为
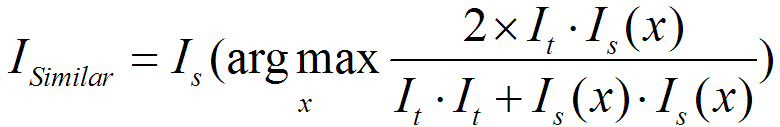
说人话,就是看看标准图测试图重合面积、测试图面积以及标准图的面积情况,只有同时和两者都接近的才能被选作相似的图片配对。
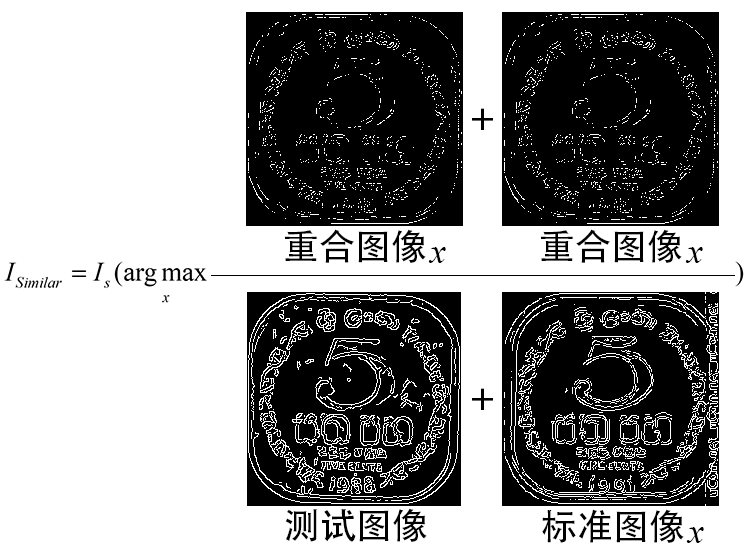
这个方法的准确率迅猛提升到了40%,但是该方法有一个致命的bug,就是一旦硬币的角度稍有旋转(实际这个情况却很容易发生),识别率显然会受到影响。而且数据量增大也会使准确率和速度逐渐降低。速度降低很显然,至于准确率下降,老潘在测试的时
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









