 热备份与归档日志备份
热备份与归档日志备份




 本文介绍如何在数据库保持打开状态下进行热备份,并详细解释了热备份的原理及步骤,同时给出了备份脚本的具体实现。此外,还介绍了如何备份归档日志文件。
本文介绍如何在数据库保持打开状态下进行热备份,并详细解释了热备份的原理及步骤,同时给出了备份脚本的具体实现。此外,还介绍了如何备份归档日志文件。
第3、4节介绍了从一致备份中还原并恢复一个数据库,但弊端在于操作过程中数据库必须被关闭。因为在实际环境中,用户和应用系统一直在使用数据库,数据库是不允许被关闭,那如何实现打开数据库的备份和恢复,本节及下一节进行讨论。
在数据打开时,数据文件和控制文件被被更新,重做日志被写入并归档,此时办法是在备份时把表空间置于备份模式,然后备份数据文件,备份完毕后把表空间恢复到正常状态。当数据库出现故障时,可以从备份路径下复制部分或全部文件进行还原,需要特别注意的每个数据文件首部都有一个序号,所有数据文件必须拥有同样的SCN号时,数据库才能够被打开。
上面提到打开数据库备份时需要把表空间置为备份模式,当表空间处于备份模式时处理动作如下:
- 设置该表空间文件头标记,表明该文件即将进行热备份;
- 表空间数据文件执行一个检查点,内存中所有“脏”数据块被写入数据文件中,检查点的SCN被写入数据文件头和控制文件中,这时对文件中的任何变化都是冻结的;
- 在告警日志文件中添加一个开始备份记录
- 在数据文件中任何块首次变动前,相关数据块将被拷贝到重做日志中,然后针对该块的变动生成一个标准的重做向量。
表空间处于备份模式时,可以使用操作系统的复制命令,把数据文件拷贝到其他地方。由于热备期间重做日志必须保留每个已变化数据块的拷贝(仅对首次变化),因此应在数据库活动较少时进行打开数据库的备份。
数据库复制完毕后,表空间脱离备份模式将进行如下动作:
- 清除热备份标志,表明备份已经结束;
- 终止记录备份SCN,并作为重做矢量;
- 数据文件的检查点结构解除冻结,并与数据库的其他部分相匹配;
- 重做生成返回到正常方式。
练习5:备份打开的数据库
本练习中,使用ALTER TABLESPACE…BEGIN BACKUP命令,对表空间中的数据文件进行打开数据库的备份,备份完毕后,使用ALTER TABLESPACE…END BACKUP或ALTER DATABASE END BACKUP命令把表空间脱离热备份模式。一个完整的数据库打开备份处理需要复制每一个联机数据文件外,还需要对当前控制文件进行备份。
步骤一:产生数据库活动
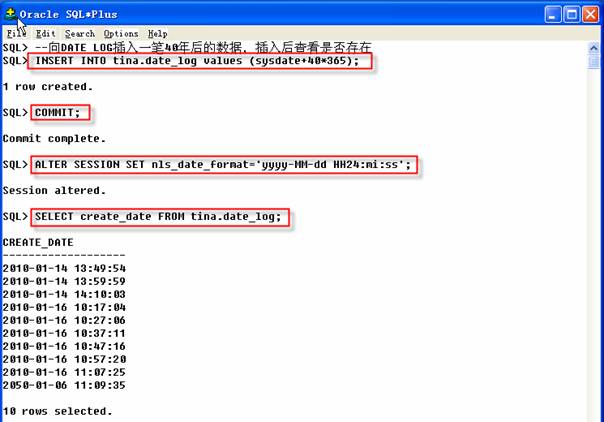
向TINA用户的DATE_LOG插入四十年后的数据,可以在恢复完毕后查看是否存在该笔数据以确认恢复是否成功。
2 SQL>COMMIT;
3 SQL>ALTER SESSION SET nls_date_format=’yyyy-MM-dd HH24:mi:ss’;
4 SQL>SELECT create_date FROM tina.date_log;
步骤二:创建热备份脚本
创建的脚本将完成如下工作:
- 切换日志文件,确保在备份前归档所有更改;
- 将一个表空间设置为热备模式;
- 用操作系统命令复制该空间下的文件;
- 将该表空间脱离热备份模式;
- 对于每一个表空间,重复2-4操作;
- 切换日志文件,归档备份中所做的更改;
- 备份当前控制文件
在下面创建使用的的文件有:
- 备份脚本文件(open_backup.sql) 使用文本编辑器创建的热备脚本;
- 备份命令文件(open_backup_command.sql) 该文件是在open_back.sql中创建并执行的;
- 备份命令文件输出文件(open_backup_output.list) 用于记录open_backup_command.sql执行的结果
1 set feedback off pagesize 0 heading off verify off linesize 200 trimspool on
2 define dir = 'D:\oracle\CODE\chap5'
3 define fil = 'D:\oracle\CODE\tmp\open_backup_commands.sql'
4 define spo = '&dir\open_backup_output.lst'
5 prompt *** Spooling to &fil
6 set serveroutput on
7 spool &fil
8 prompt spool &spo
9 prompt archive log list;;
10 prompt alter system switch logfile;;
11 DECLARE
12 CURSOR cur_tablespace IS
13 SELECT tablespace_name FROM dba_tablespaces
14 WHERE status <> 'READ ONLY';
15 CURSOR cur_datafile (tn VARCHAR) IS
16 SELECT file_name
17 FROM dba_data_files
18 WHERE tablespace_name = tn;
19 BEGIN
20 FOR ct IN cur_tablespace LOOP
21 dbms_output.put_line('alter tablespace ' || ct.tablespace_name || ' begin backup;');
22 FOR cd IN cur_datafile(ct.tablespace_name) LOOP
23 dbms_output.put_line('host copy ' || cd.file_name || ' &dir');
24 END LOOP;
25 dbms_output.put_line('alter tablespace ' || ct.tablespace_name || ' end backup;');
26 END LOOP;
27 END;
28 /
29 prompt alter system switch logfile;;
30 prompt alter database backup controlfile to '&dir\backup.ctl' REUSE;;
31 prompt archive log list;;
32 prompt spool off;;
33 spool off;
34 @&fil
- 第1行设置SQL*Plus变量,避免从数据库中提取的结果在命令文件中显示不必要的内容;
- 第2-4行在脚本范围内为命令制定用户变量, dir变量指定了备份文件将被拷贝的路径位置,fil则指定了生成备份命令的文件名称,spo变量定义脚本执行的日志。在接下来的脚本中,可以通过在变量名前加&来引用该变量;
- 第6行使用SQL*Plus提示命令显示输出结果;
- 第7行通知SQL*Plus将所有的屏幕结果输出结果写入一个文件,该文件名为变量fil所定义的open_backup_commands.sql;
- 第8行向spool文件open_backup_commands.sql写入一条spool命令,当运行open_backup_commands.sql脚本时,可以把执行日志记录到open_backup_output.list文件中;
- 第9行向命令文件写入显示当前正在归档信息命令,当恢复数据库时,需要了解当前日志文件的序号;
- 第10行将日志文件从当前日志文件切换到下一个日志文件,这将对所有数据文件进行一次检查点并创建一个新的归档日志文件;
- 第11-27行分别进行将表空间置于备份模式、复制所有的数据文件到备份目标路径以及向表空间脱离备份模式。这里使用了两个游标:分别是数据库所有表空间列表和每个表空间数据文件列表。其具体处理过程如下:循环获取表空间游标值,首先置表空间于备份模式,然后获取该表空间下所有数据文件并复制到目标备份路径,复制完毕后,该表空间接触备份模式;
- 第28行将当前日志文件切换到下一个日志文件,以保证热备过程中创建的中动作得以归档;
- 第29行在数据文件备份完成后应立即创建控制文件的备份。脚本中使用一个SQL语句生成该文件的拷贝,REUSE关键字表示如果存在该文件将覆盖;
- 第30-32行指示open_backup_commands.sql文件将归档信息列出到备份脚本的spool文件,然后文件终止假脱机;
- 第33行执行创建的热备脚本
步骤三:运行备份脚本
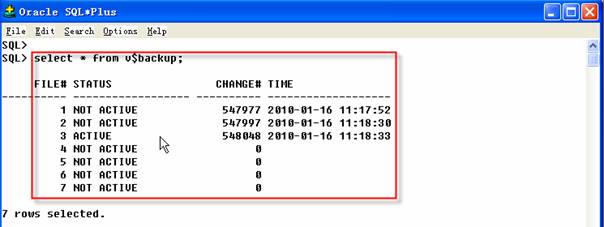
在SQL*Plus中执行步骤二创建的脚本,该脚本运行时,表空间和数据文件被置于备份模式,此时可以通过另一个SQL*Plus会话中查看v$backup视图,查看哪些文件处于备份模式。
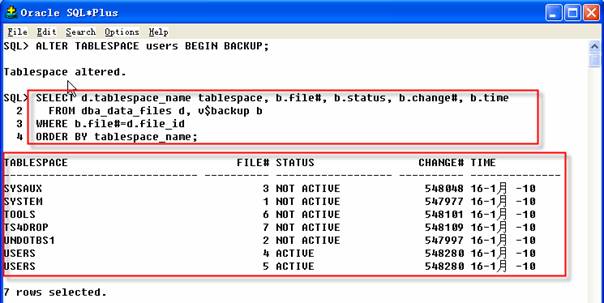
在备份结束后,也可以将用户表空间置于备份模式,查看联机数据文件的备份状态。
2 SQL>SELECT d.tablespace_name tablespace, b.file#, b.status, b.change#, b.time
3 FROM dba_data_files d, v$backup b
4 WHERE b.file#=d.file_id
5 ORDER BY tablespace_name;
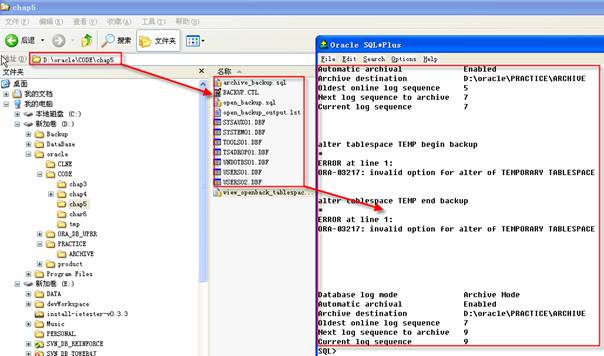
打开备份运行后,查看告警日志,将得到如下的备份模式记录。
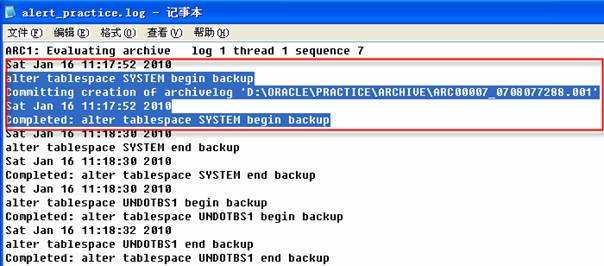
该警告显示SYSTEM表空间打开备份操作的时间信息,2010-1-16 11:17:52执行脚本生成命令,将SYSTEM表空间置于备份模式,随之SYSTEM表空间真正处于备份模式,在这等待的过程中,数据库进行相关的操作;复制SYSTEM数据文件所需要的时间38秒,2010-1-16 11:18:30提交命令,将SYSTEM表空间脱离备份模式,随之SYSTEM表空间恢复为正常模式。
本练习中的命令实现了Oracle推荐的连续备份方式,该方式可以是ALTER TABLESPACE…BEGIN/END BACKUP语句之间的时间间隔减少到最少,避免在热备过程中产生庞大的重做信息,另外如果在热备过程中数据库崩溃,结束一个表空间中部分数据文件的备份要比结束对所有包括总舵数据库文件的多个空间的备份要快得多、容易得多。
步骤四:检查备份命令
查看脚本创建的文件open_backup_commands.sql,该文件有助于了解热备的整个流程。
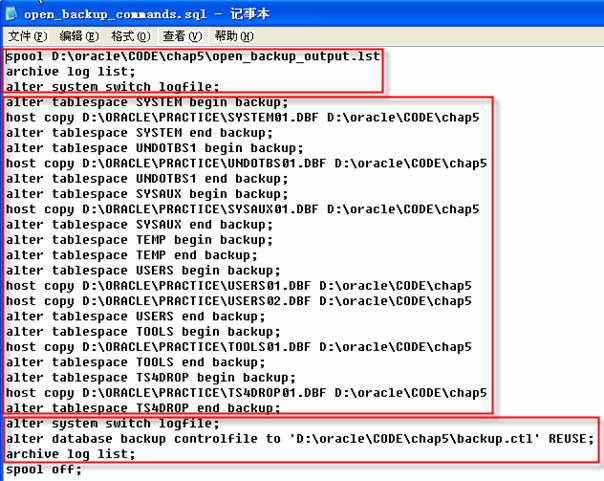
练习6:备份归档日志文件
在练习5中我们已经对数据库数据文件进行了热备,实际中备份后,数据库不断创建归档日志文件,经过一段时间累积这些文件将填满归档路径。这就需要我们定期对归档路径进行清理,可以把这些归档文件转义至一个磁带备份设备或者一台远程机器上,当由于灾害(洪水、火灾、地震等)而导致机器损毁,可以通过脱机数据文件、控制文件、脱机归档文件可用于恢复数据库。
步骤一:寻找归档文件
归档文件存在在数据库初始化文件配置节log_archive_dest参数定义路径下,可以通过参数文件、SHOW PARAMETER命令或从v$archive_dest视图进行查看。如何设置该参数请参考练习3步骤一描述。
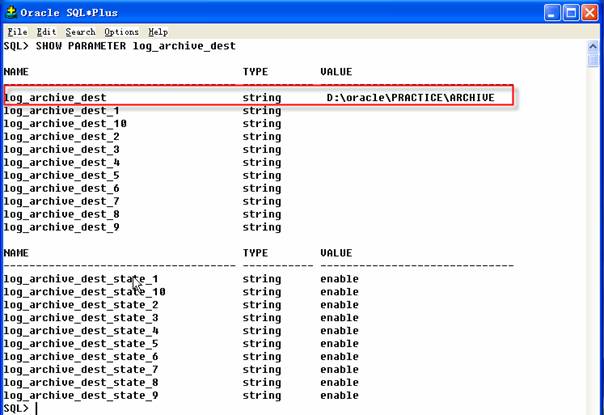
步骤二 :创建归档文件脚本
可以使用操作系统move命令来异动已经归档的文件从归档路径转移到其他地方。在archive_backup.sql的文件中,生成一个备份命令文件archive_back_commands.sql。该命令首先从v$archive_log视图中找出昨日创建的所有归档日志文件,使用move命令将这些归档日志转移到一个备份路径下。
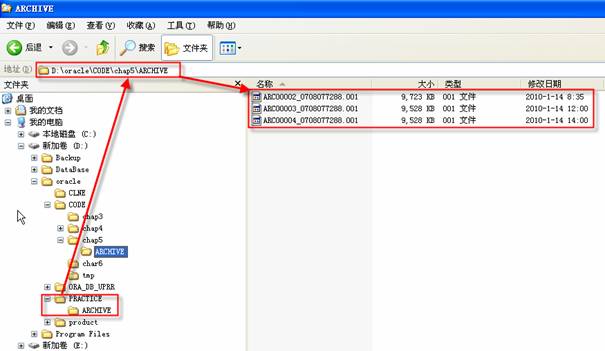
2 define dir = 'D:\oracle\CODE\chap5\ARCHIVE'
3 define fil = 'D:\oracle\CODE\tmp\archive_back_commands.sql'
4 spool &fil
5 prompt archive log next;;
6 SELECT 'host copy ' || name || ' &dir'
7 FROM v$archived_log
8 WHERE completion_time >= trunc(sysdate) - 1
9 AND completion_time < trunc(sysdate);
10 spool off;
11 @&fil
- 第2-3行设置SQL*Plus需要使用的变量,dir变量指定了备份文件将被拷贝的路径位置;
- 第4行和第10行分别开始和终止将SQL输出记录到一个文件中;
- 第5行通知数据库对任何未归档的联机重做日志文件进行归档。该命令非常重要,由于数据库处于归档状态中,重做活动繁多,ARCHIVE LOG NEXT命令可以确保在返回到SQL*Plus命令提示符控制之前,所有需要归档的联机重做日志得到归档。需注意该命令有两个分号,这个在生成的命令文件中产生一个分号;
- 第6-9行从v$archived_log视图中获取已归档日志文件,利用各文件名称,对路径会生成一个move命令。在这个脚本中将转移昨天创建的文件,trunc功能将删除sysdate变来那个的时间(time)部分,该脚本转移从昨天00:00:00至23:59:59之间24小时内创建的所有归档;
- 第11行运行spool文件的内容;
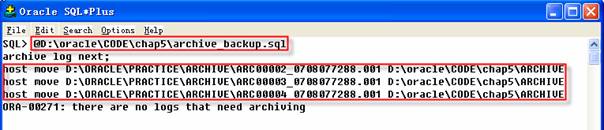
步骤三:运行归档文件脚本
创建完毕archive_backup.sql内容后,以SYS身份登录,从SQL*Plus运行这个脚本。如果多次运行这个脚本,将会得到消息提示:移动命令没有找到文件,这是正常的,因为归档文件已经被转移了。
步骤四:确认归档日志备份
打开归档备份路径,确认文件已经被转移到目标路径上,查看是否所期望的所有归档日志文件被成功转移。

















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









