






 本文介绍TypeScript的基本概念,包括其作为JavaScript超集的特点、环境搭建步骤及自动编译配置方法,并详细解析各种数据类型的应用。
本文介绍TypeScript的基本概念,包括其作为JavaScript超集的特点、环境搭建步骤及自动编译配置方法,并详细解析各种数据类型的应用。
该文章用于督促自己学习TypeScript,作为学笔记进行保存,如果有错误的地方欢迎指正
2019-03-27 16:50:03
一、什么是TypeScript?
TypeScript是javascript的超集,在ts中可以使用所有的js代码,并对js进行了扩展,包括类型效验,数据类型,接口等
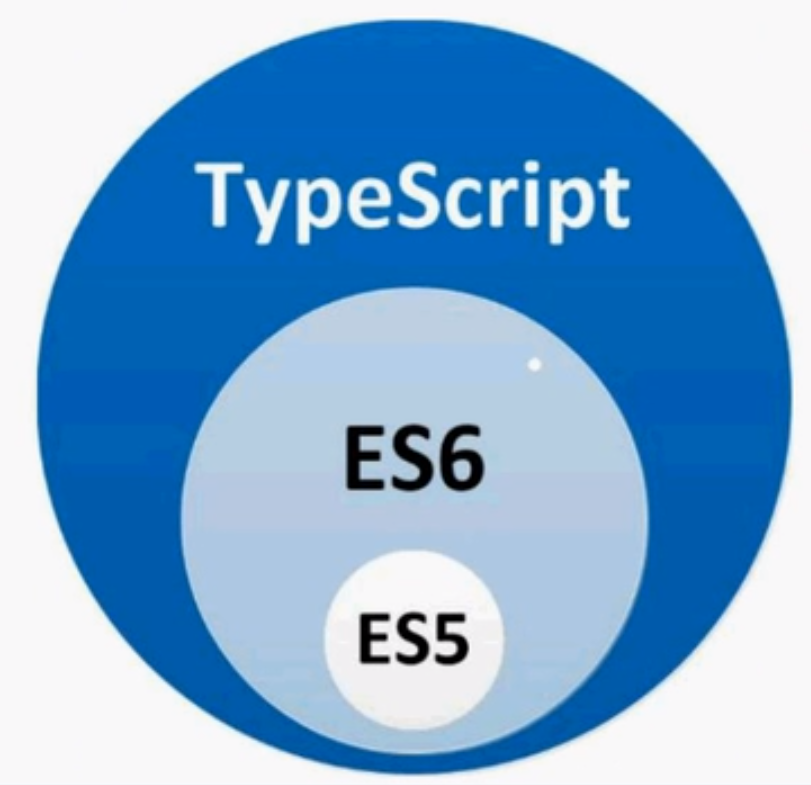
如图所示,TypeScript包含了javascript并进行延伸
二、准备工作
在说TypeScript之前先说一下如何让ts编译为js代码
首先安装 typescrpt,
npm install -g typescript
将ts编译为js代码,在命令行中输入
tsc index.ts
但不能每次写完代码都输入一遍 tsc 来进行编译吧?那也太麻烦了,我们能不能直接保存就自动编译呢?可以的,下面是使用VScode的自动编译方法
首先在文件根目录下打开命令行输入,
tsc --init
输入以后会在文件中出现一个 tsconfig.json 文件
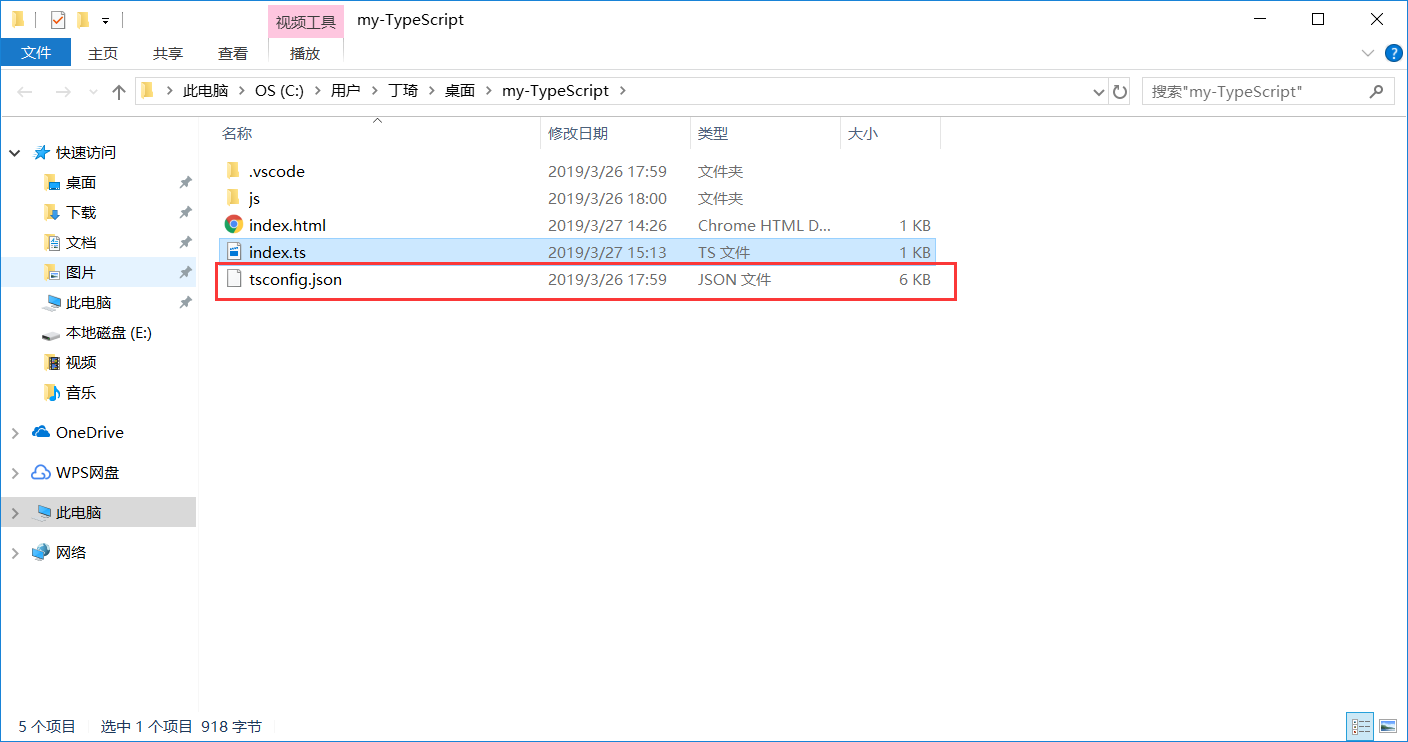
在文件中将 "outDir" : "./"打开,改为 "outDir" : "./js" ,表示编译后的 .js 文件 的存放位置
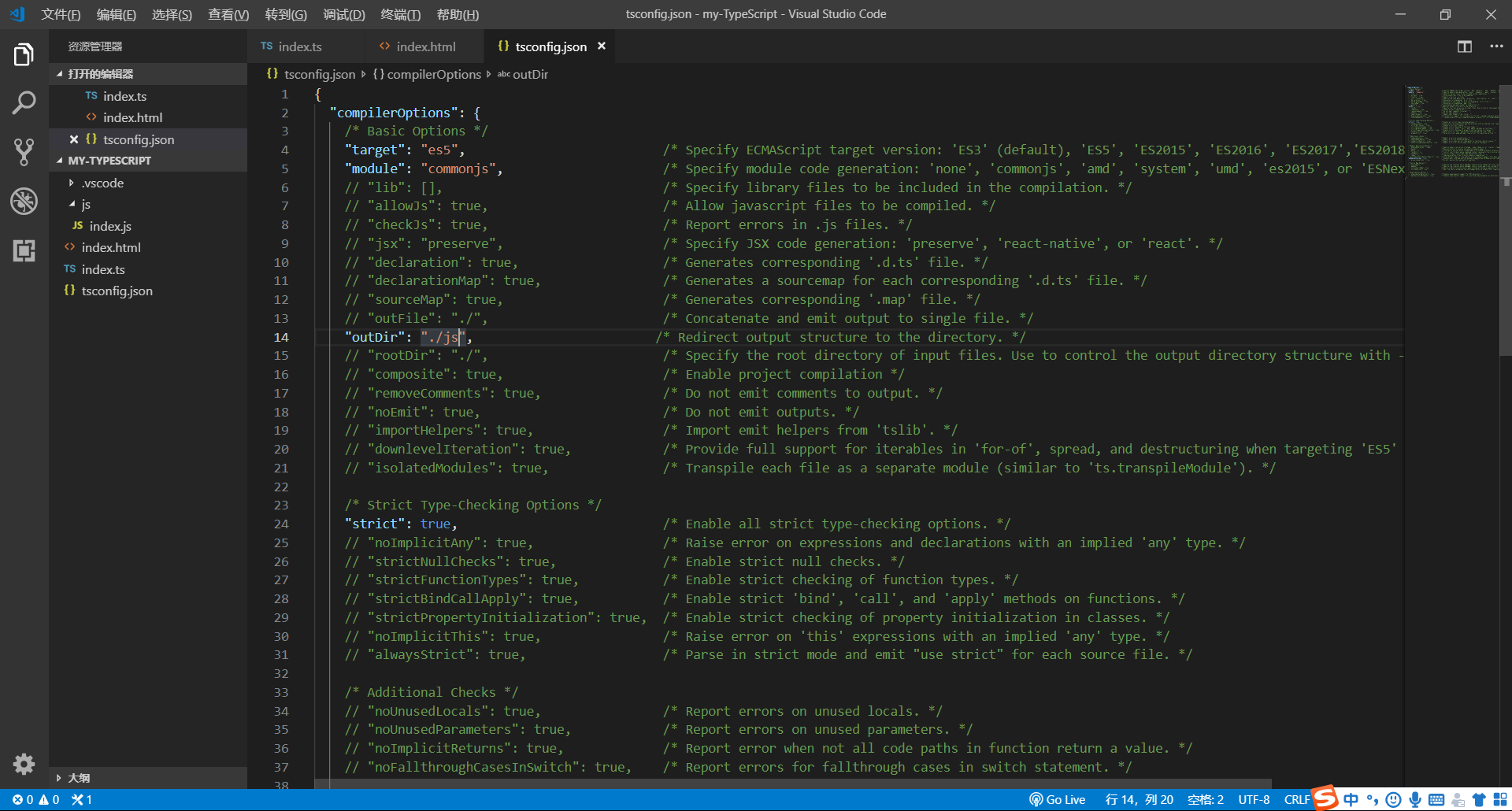
在 VScode 的工具栏中选择:终端 --> 运行任务
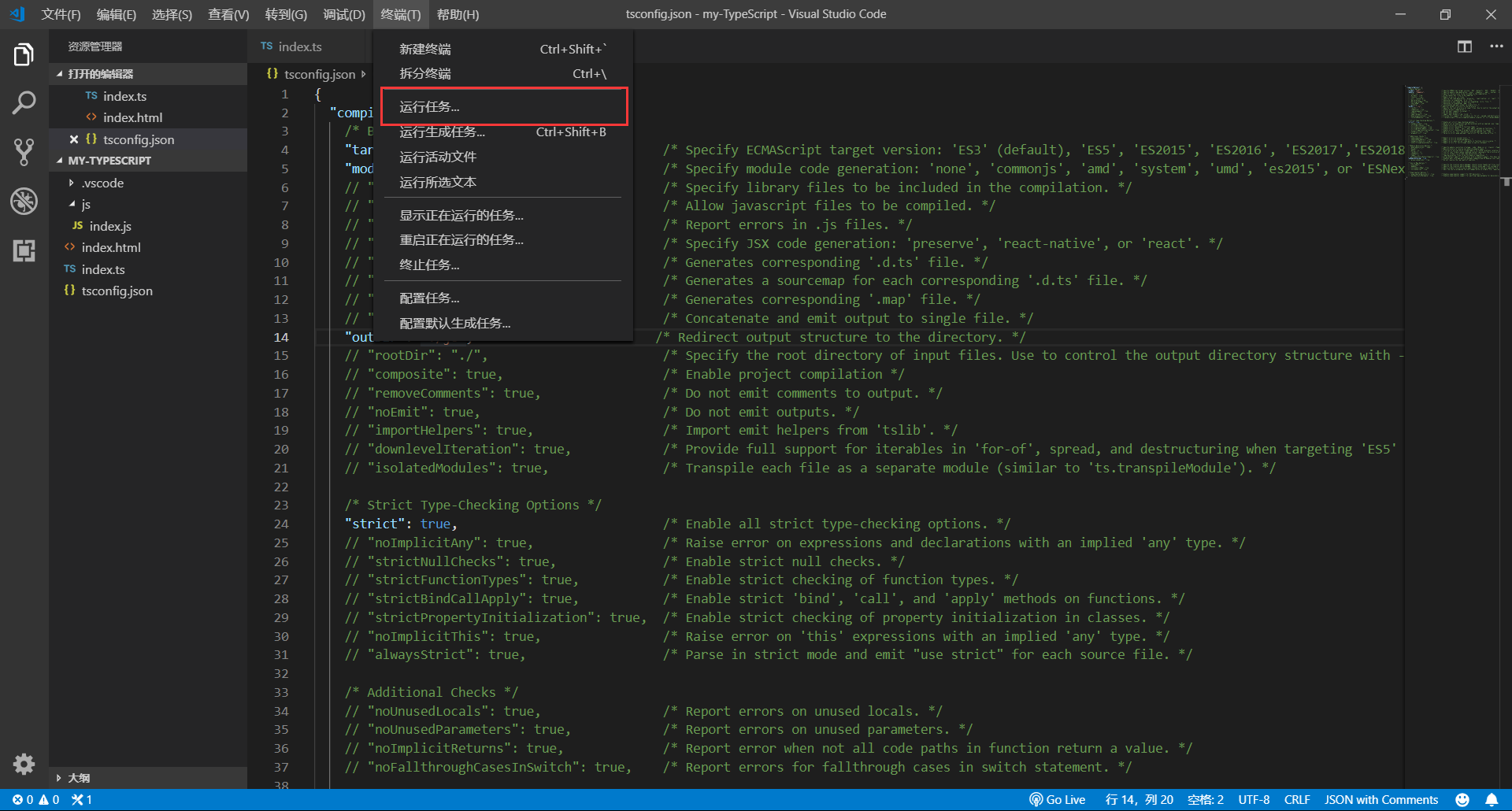
在工具栏弹出框里选择:
tsc:监视 - tsconfig.json
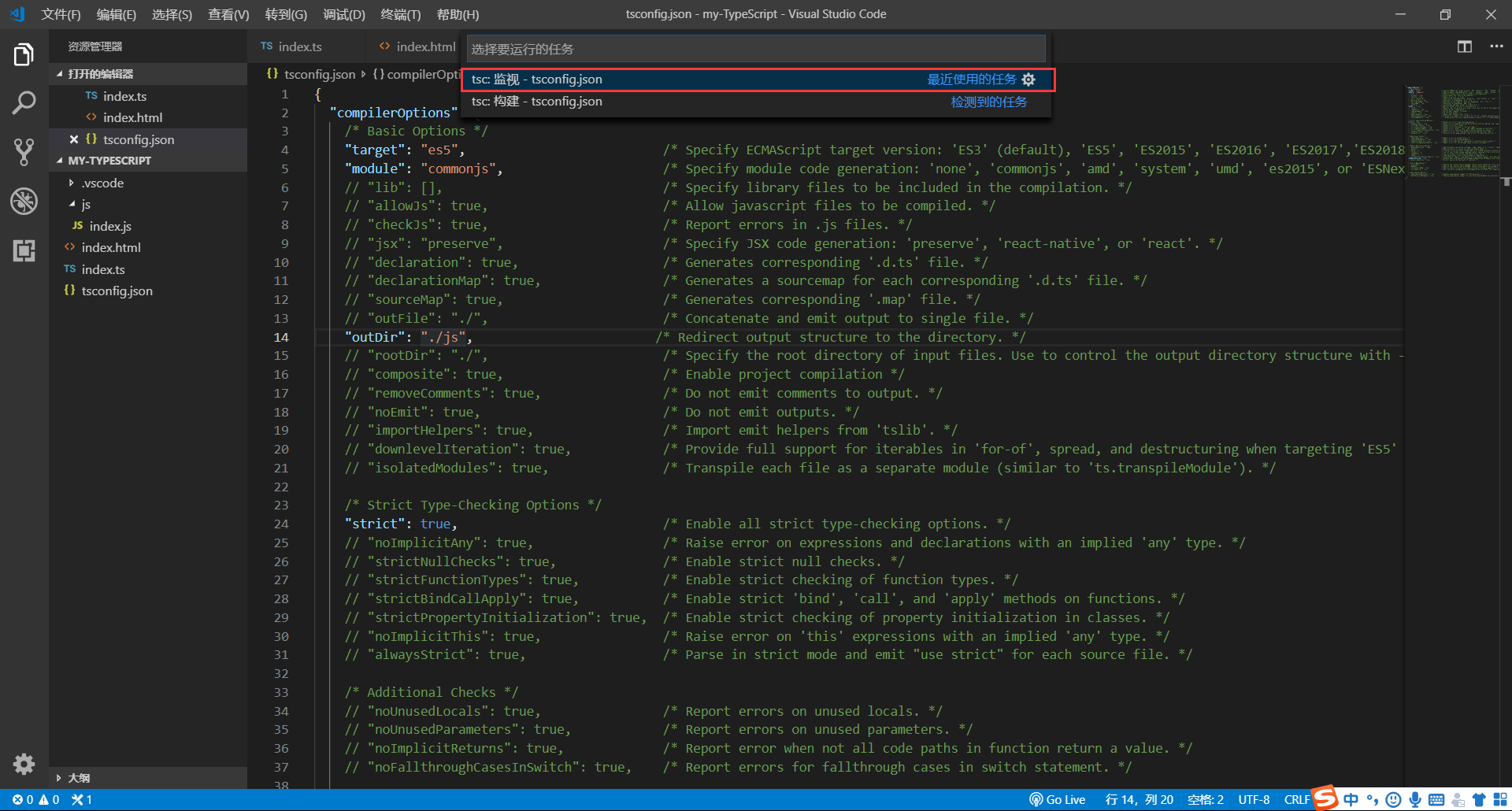
这样就配置完成了,可以在文件中试一试,保存ts文件后,会在文件中生成一个名为js的文件,里面就是编译后的 同名.js 文件,在html中引入js,就可以进行测试了
三、TypeScript的数据类型
1)布尔值类型(boolean)
使用 ts 的高级工具 类型注解来创建一个变量 bol ,要求 变量bol 的值得类型为 boolean 类型,否则会报错

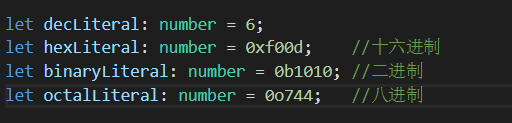
2)数字类型(number)
支持所有浮点数,并支持二进制、八进制、十进制、十六进制的写法
3)字符串类型(string)

支持双引号 " "、单引号 ' ' 和模板字符串 ` `
4)数组类型(Array)
创建模板字符串有两种方式:
第一种:在变量名的类型后面加上 [ ] ,表示数组内的元素都是同一个类型:

第二种:是数组泛型,使用Array<元素类型>

5)元组类型(Tuple)
元组也是数组的一种,ts的数组如果使用使用类型注解来创建,数组的元素就具有效验的功能,但是未免太单一,而使用元组的方式创建数组,会稍微灵活那么一点点
使用元组来创建:
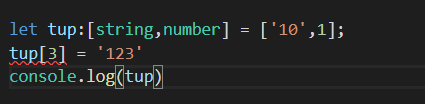
浏览器输出为:
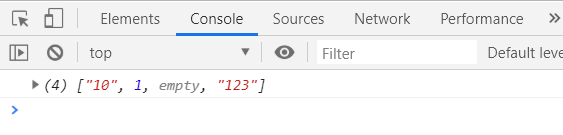
在图示中可以看到,元组可以规定前两个元素的类型,下标为 0 的元素必须为 string,下标为 1 的元素必须为 number,而后的元素则会使用联合类型替代,可以是 string 或 number ,我尝试了隔空添加元素,下标为 2 的元素 显示为 empty(空),在遍历这个元组的时候,empty不会被遍历出来,只会遍历到 “10” 1 “123” ,对应的下标为0,1,3
图示中的报错是vscode插件的报错,不会影响运行
6)枚举类型(enum)
枚举类型可以是对状态码的标识,如 0 代表成功支付 ,1 代表失败支付,2 代表取消订单,3 代表未支付 这样的状态码标识不易读,可以使用枚举的方式来标识
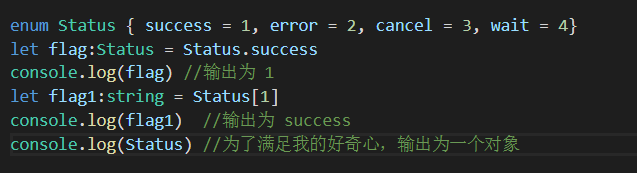
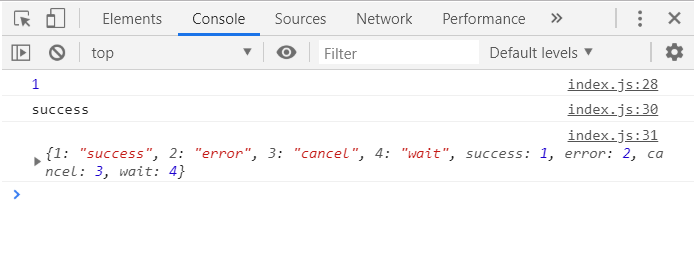
看到枚举类型 Status 的输出,就明白了为什么可以得到 Status[1] 为success 了
枚举类型也可以不赋值,默认从 0 开始,一旦手动赋值后,前面的值不变,后面的值会依次递增
7)任意类型(any)
在实际使用中我们也许并不想让 ts 进行类型注解,就可以使用 any类型 ,any类型的好处在于,当我们不确定这个值为什么类型的时候,用 any类型注解 声明后的变量,他的类型是不确定的,从而使得这个变量可以调用任何不同类型的方法,但是编译器不会检查

可以使用 any 来进行数组的类型注解,不限制数组的元素类型

8)无类型(void)
void类型可以说与any类型完全相反,当函数没有返回值时返回的类型就是 void 类型,一般来说声明一个 void类型 的变量没有什么用,void 类型只能被赋值,undefined 和 null
在 typescript 中 默认情况下 undefined 和 null 是所有类型的子类型,可以将他们赋值给 number 类型的变量
当指定了严格模式 --strictNullChecks 后,undefined 和 null 只能赋值给他本身
9)never类型(never)
never类型表示永远不存在的值的类型,
引入官方文档的示例图

never类型是所有类型的子类型,但never类型本身没有子类型或任何类型都不能赋值给他,连any都不行,never只能赋值给never
9)Object类型
object类型表示非原始类型,就是除了 boolean,number,string,array,undefined,null 之外的类型
参考官方给的图片

图片示例的意思我理解的是这样的:
创建一个create函数,参数 o 的类型注解表示,参数的类型为 object 或者 null ,函数create的返回值为 void类型
接着调用函数,发现参数为 {prop:0} 和 null 是可以的
参数为 数字 42,字符串 "string",布尔值 false,无类型 undefined,都不可以
补充:类型断言
类型断言使用在告诉编译器,你已完全确定这个值的类型,编译器将会跳过数据检查,不影响运行
类型断言有两种写法
第一种:使用尖括号

第二种:使用 as 语法

注意:在 TypeScript 中使用 JSX,只能用 as语法 的类型断言

















 2000
2000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









