



关于爬虫协议:
有的网站下是有文件:robots.txt
比如:
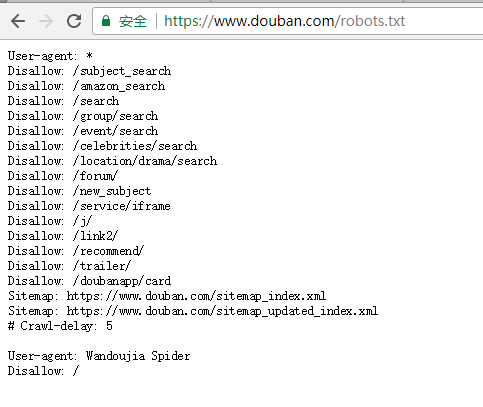
豆瓣
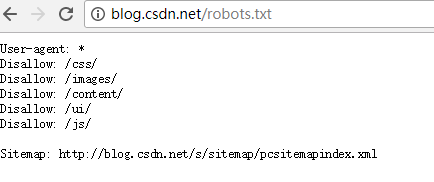
优快云
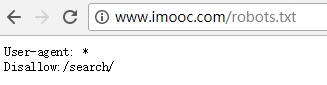
以慕课网http://www.imooc.com/首页为例
源代码:
#coding:utf-8
class Outputer:
def __init__(self,directory):
self.directory=directory
def output(self,file,content):
try:
f=open(self.directory+file,'wb')
f.write(content)
except Exception as err:
print(err)
finally:
f.close()
print(file+"has writed!")
class SpiderMan:
def __init__(self,url,directory):
self.url=url
self.outputer=Outputer(directory)
def crawl(self):
resp=request.urlopen(self.url)
buff=resp.read()
pattern=r'http:.+\.jpg'
jpgurls=re.findall(pattern,buff.decode('utf-8'),flags=0)
count=1
for jurl in jpgurls:
try:
content=request.urlopen(jurl).read()
print(count)
count=count+1
self.outputer.output('imooc_'+str(count)+'.jpg',content)
except UnicodeEncodeError as err:
print(err)
if __name__ == '__main__':
from urllib import request
import re
#http://www.imooc.com/
url='http://www.imooc.com/'
spider=SpiderMan(url,'./spider_imooc/')
spider.crawl()
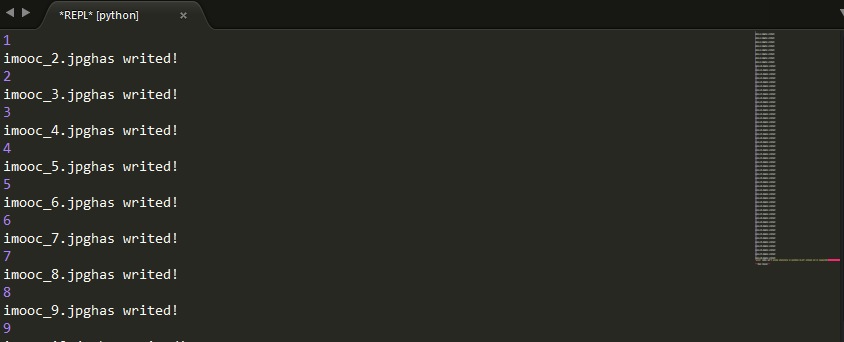
运行图:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









