



 本文对比了两种不同的ACM竞赛模拟题解决方案,一种是在录入数据时建立ID到成绩信息的映射,另一种则是使用数组记录信息并通过ID找到数组索引。文章详细分析了每种方法的优缺点,并给出了具体的代码实现。
本文对比了两种不同的ACM竞赛模拟题解决方案,一种是在录入数据时建立ID到成绩信息的映射,另一种则是使用数组记录信息并通过ID找到数组索引。文章详细分析了每种方法的优缺点,并给出了具体的代码实现。
这应该是比较简单的一个模拟题,但是考试的时候花了较长的时间,并且最后一个case没过,丢了6分。这题的通过率不高,可见最后一个case还是有挑战性的。
考试的时候想的是在录数据的时候建立一个【ID】到【成绩信息】的映射,但是看网上代码用一个数组来录信息,然后建立【ID】到【数组索引】的映射。根据我的想法反正最后一个case根本过不了,可能只能按照网上博客的思路才行。
考试时的代码(最后一个case报错):


#include <stdio.h> #include <memory.h> #include <math.h> #include <string> #include <vector> #include <set> #include <stack> #include <queue> #include <algorithm> #include <map> #define I scanf #define OL puts #define O printf #define F(a,b,c) for(a=b;a<c;a++) #define FF(a,b) for(a=0;a<b;a++) #define FG(a,b) for(a=b-1;a>=0;a--) #define LEN 501 #define MAX 0x06FFFFFF using namespace std; typedef struct Student{ string name; int gp,gm,gf,G; Student(){ gp=0,gm=0,gf=0,G=0; } Student(string n,int p,int m,int f,int g){ name=n; gp=p,gm=m,gf=f,G=g; } bool operator < (Student const & o)const { if(G<o.G) return true; else if(G==o.G) return name<o.name; } }Student; Student output[10000]; #define MAP map<string,Student*> MAP info; bool cmp(Student a,Student b); int main() { freopen("d:/input/A1137.txt","r",stdin); int P,M,F,t; char buffer[1000]; scanf("%d %d %d",&P,&M,&F); while(P-->0){ I("%s",buffer); scanf("%d",&t); string name(buffer); MAP::iterator it=info.find(name); Student * tmp; if(it==info.end()){ tmp=new Student; tmp->gp=t; tmp->name=name; info[name]=tmp; }else{ tmp=it->second; tmp->gp=t; } } while(M-->0){ I("%s",buffer); scanf("%d",&t); string name(buffer); MAP::iterator it=info.find(name); Student * tmp; if(it==info.end()){ tmp=new Student; tmp->gm=t; tmp->name=name; info[name]=tmp; }else{ tmp=it->second; tmp->gm=t; } } while(F-->0){ I("%s",buffer); scanf("%d",&t); string name(buffer); MAP::iterator it=info.find(name); Student * tmp; if(it==info.end()){ tmp=new Student; tmp->gf=t; tmp->name=name; info[name]=tmp; }else{ tmp=it->second; tmp->gf=t; } } int n,i=0; MAP::iterator it=info.begin(); while(it!=info.end()){ Student * p=it->second; int gp,gm,gf,G; gp=p->gp;gm=p->gm,gf=p->gf; string name=p->name; if(!(gp<200 || gf<60 || gf >100)){ if(gm==0) gm=-1; if(gf>=gm) G=gf; else{ G=round(0.4*(double)gm+0.6*(double)gf); } output[i++]=Student(name,gp,gm,gf,G); } it++; } n=i; sort(output,output+n,cmp); FF(i,n){ O("%s %d %d %d %d\n",output[i].name.c_str(),output[i].gp,output[i].gm,output[i].gf,output[i].G); } return 0; } bool cmp(Student a,Student b){ if(a.G>b.G) return true; else if(a.G==b.G) return a.name<b.name; return false; }
参考网上博客后AC的代码:
#include <stdio.h> #include <memory.h> #include <math.h> #include <string> #include <vector> #include <set> #include <stack> #include <queue> #include <algorithm> #include <map> #define I scanf #define OL puts #define O printf #define F(a,b,c) for(a=b;a<c;a++) #define FF(a,b) for(a=0;a<b;a++) #define FG(a,b) for(a=b-1;a>=0;a--) #define LEN 501 #define MAX 0x06FFFFFF using namespace std; typedef struct Student{ string name; int gp,gm,gf,G; Student(){ gp=0,gm=0,gf=0,G=0; } Student(string n,int p,int m,int f,int g){ name=n; gp=p,gm=m,gf=f,G=g; } }Student; Student students[100000]; #define MAP map<string,int> MAP name2index; bool cmp(Student a,Student b); int main() { freopen("d:/input/A1137.txt","r",stdin); int P,M,F,t; char buffer[1000]; scanf("%d %d %d",&P,&M,&F); int cnt=1; while(P-->0){ I("%s",buffer); scanf("%d",&t); string name(buffer); if(t>=200){ name2index[name]=cnt; students[cnt++]=Student(name,t,-1,-1,-1); } } while(M-->0){ I("%s",buffer); scanf("%d",&t); string name(buffer); int index=name2index[name]; if(index>0){ students[index].gm=t; } } while(F-->0){ I("%s",buffer); scanf("%d",&t); string name(buffer); int index=name2index[name]; if(index>0){ students[index].gf=t; } } int i; FF(i,cnt){ Student &tmp=students[i]; if(tmp.gf>=tmp.gm) tmp.G=tmp.gf; else{ double t=tmp.gm*4+tmp.gf*6; t/=10;t+=0.5; tmp.G=t; } if(tmp.G<60) tmp.G=-1; } sort(students+1,students+cnt,cmp); F(i,1,cnt+1){ if(students[i].G>=60) O("%s %d %d %d %d\n",students[i].name.c_str(), students[i].gp,students[i].gm,students[i].gf,students[i].G); } return 0; } bool cmp(Student a,Student b){ if(a.G==-1) return false; if(a.G>b.G) return true; else if(a.G==b.G) return a.name<b.name; return false; }
需要注意的点:
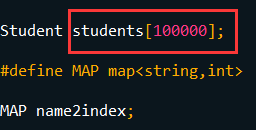 1.数组长度应该设置为1e5,否则段错误。
1.数组长度应该设置为1e5,否则段错误。
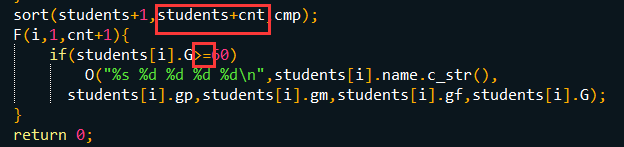
2. sort的第二个参数调试的时候脑抽写错了。students数组存储元素的范围是[1,cnt),第二个参数我脑抽写成了students+cnt+1
3. 判断成绩是否有效的判断语句也写错了。及格应该是大于等于,写成>60第二个和最后一个case过不了。

















 124
124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









