






 本文深入探讨了SparkStreaming的架构设计与运行机制,包括ReceiverTracker的工作原理及其如何利用时间间隔分配数据给BatchDuration,同时介绍了currentBuffer的作用以及SparkStreaming运行的核心思想。
本文深入探讨了SparkStreaming的架构设计与运行机制,包括ReceiverTracker的工作原理及其如何利用时间间隔分配数据给BatchDuration,同时介绍了currentBuffer的作用以及SparkStreaming运行的核心思想。
本期内容 :
- Spark Streaming中的架构设计和运行机制
- Spark Streaming深度思考
Spark Streaming的本质就是在RDD基础之上加上Time ,由Time不断的运行触发周而复始的接收数据及产生Job处理数据。
一、 ReceiverTracker :
Receiver数据接收器的启动、接收数据过程中元数据管理,元数据管理是使用内部的RPC。
根据时间的间隔把数据分配给当前的BatchDuration :
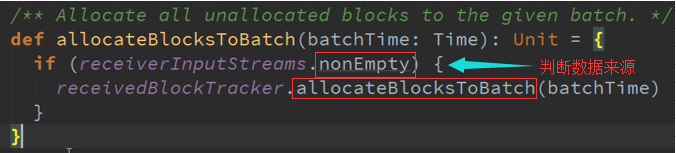
通过Dstreams中的StreamID以及这个DStreamID给这个时间段(getReceivedQueue(SteamID))的Block为例 :

不断的分配是依赖定时器,看数据生成的时候怎么产生数据及通过他的方式管理数据的 。

不断接收数据并保存起来,在BlockTracker启动Receiver时首先会启动StartReceiver 。
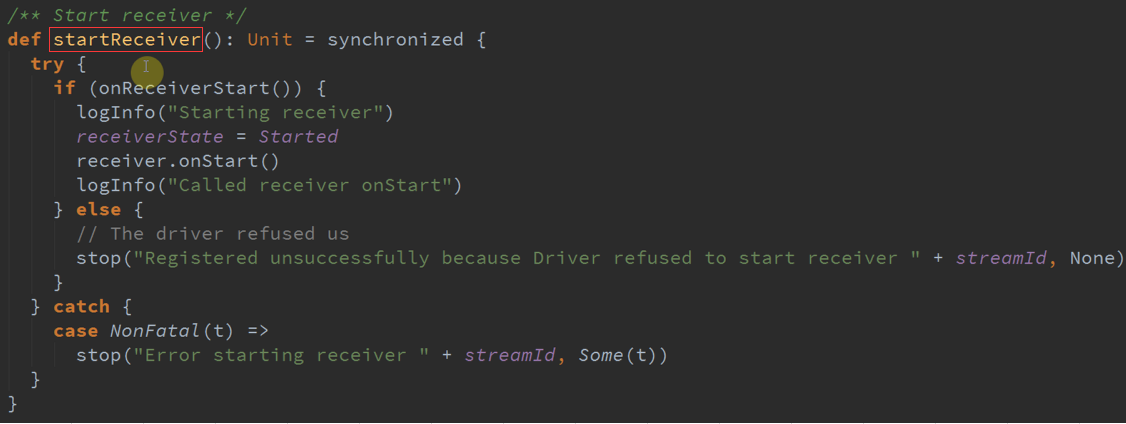
写数据时有不同的BlockHandler 。

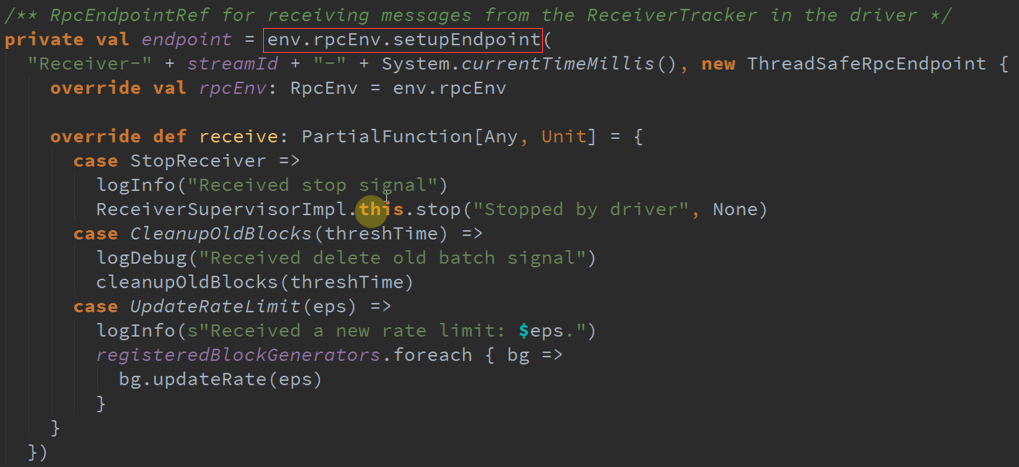
Receiver自己的RPC ,响应不同的消息。
定时器按照具体的时间间隔 :


二、 currentBuffer :
把接收的数据保存在一个currentBuffer数据结构(属于临时数据结构)中,每次根据其时间间隔进行,每次都会New一下currentBuffer,默认是200MS。
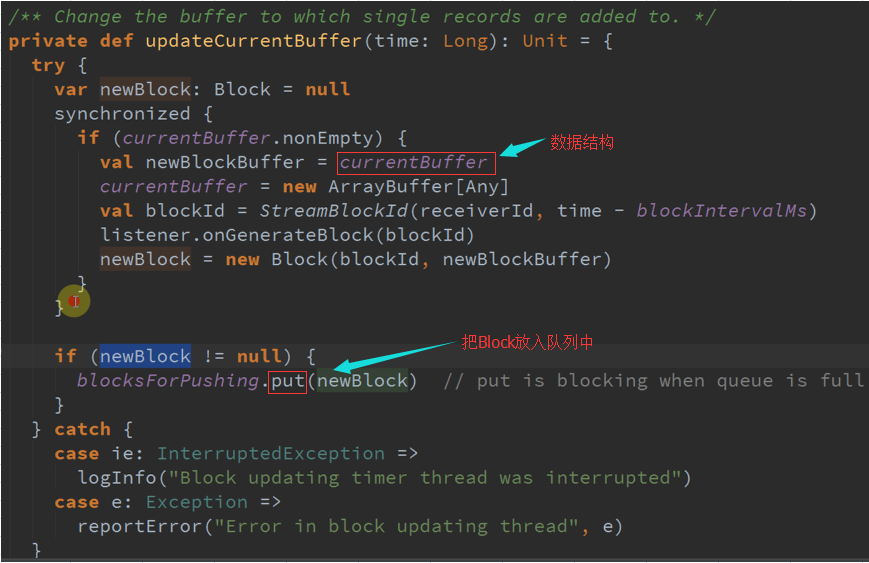

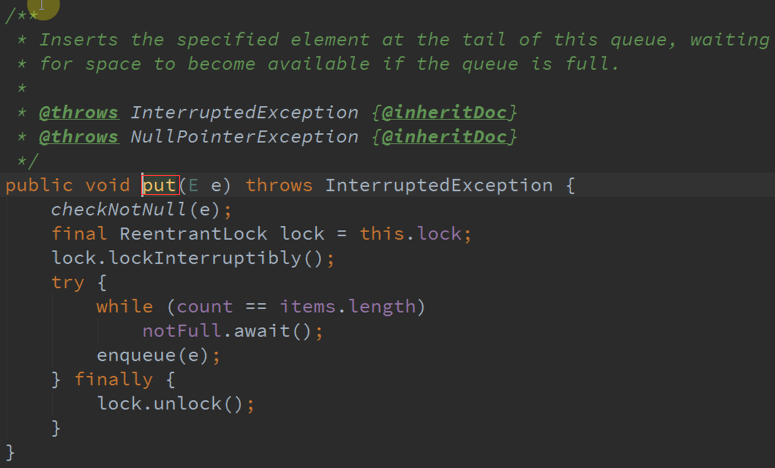
三、 架构思考 :
从Spark Streaming的角度讲静态生成Dstreams,Dstreams当遇到时间的时候才会生成RDD和DStreamGenerator。
基于DStreamGenerator就构成了这个依赖关系。调度层面讲JobScheduler,是基于时间的流处理框架。
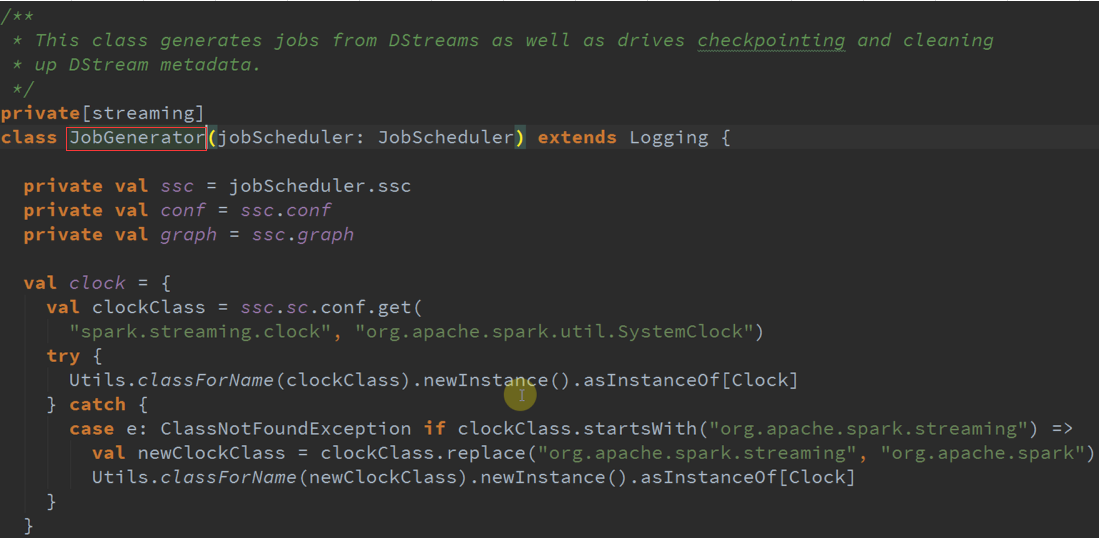
根据BatchDuration的时钟不断循环,不断的发送消息 。


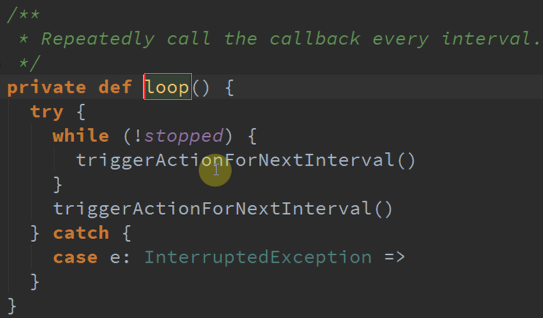
以时间为基准 不断的发送消息给event 。



生成作业 :
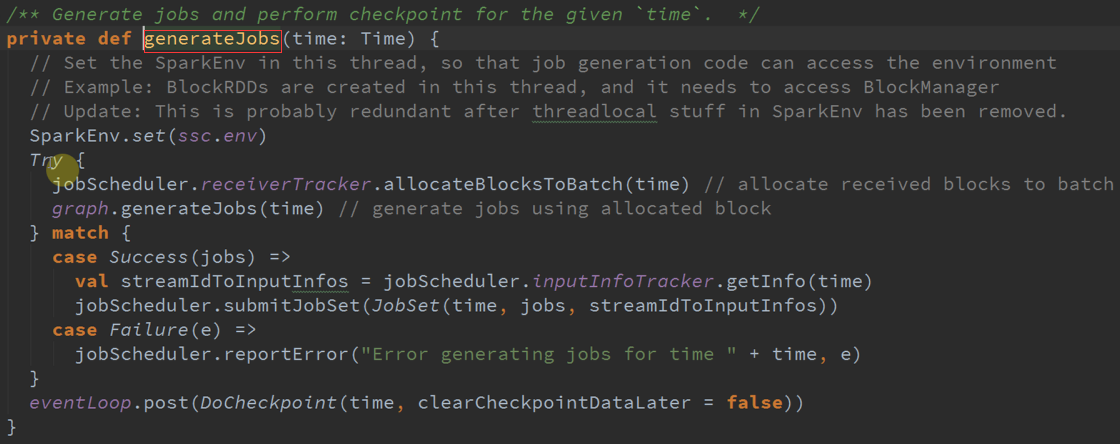
Spark Streaming运行核心:
Spark RDD加上Time,无论是从概念还是数据接收、数据处理,Time是驱动力,不断的循环事件、消息,时间的确定、数据、RDD接着就转到Spark Core。

















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









