






*****概念*****
索引:对数据库表中一个或多个列的值进行排序的逻辑结构
优点:能够快速访问表中的记录,提高查询速度
缺点: 1.索引占用磁盘空间 2.降低添加、删除、更行行的速度
索引分类:
聚簇索引:聚簇索引的顺序就是数据的物理存储顺序。简单说,原表的顺序就是聚簇索引的顺序。
非聚簇索引:索引顺序与数据物理排列顺序无关。简单说,独立的排序顺序,与原表顺序无关。
个人简析:
新华字典文字是按英文字母顺序排序:a、b、c....x、y、z,可假定新华字典就是一张新华字典表,表内文字按照字母顺序进行排序。
假设我们要查找“搜”字,需要翻到“s”字母部分,因此会按照字母排序的顺序(“a”到“z”的顺序),翻到“s”字母部分。这里字母排序顺序就是非聚簇索引的顺序。
当然,我们可以通过偏旁部首的顺序进行查询,查找到“扌”,我们就能找到“搜”,这种方式和新华字典表顺序不同,为独立的顺序,这就是非聚簇索引。
避免使用索引:
索引不应该使用在较小的表上。
索引不应该使用在有频繁的大批量的更新或插入操作的表上。
索引不应该使用在含有大量的 NULL 值的列上。
索引不应该使用在频繁操作的列上。
*****索引实操*****
唯一索引:
基于表的单列创建的索引
组合索引:
基于表的两个或多个列创建的索引
使用标准:
是否要创建一个单列索引还是组合索引,要考虑到您在作为查询过滤条件的 WHERE 子句中使用非常频繁的列。
如果值使用到一个列,则选择使用单列索引。如果在作为过滤的 WHERE 子句中有两个或多个列经常使用,则选择使用组合索引
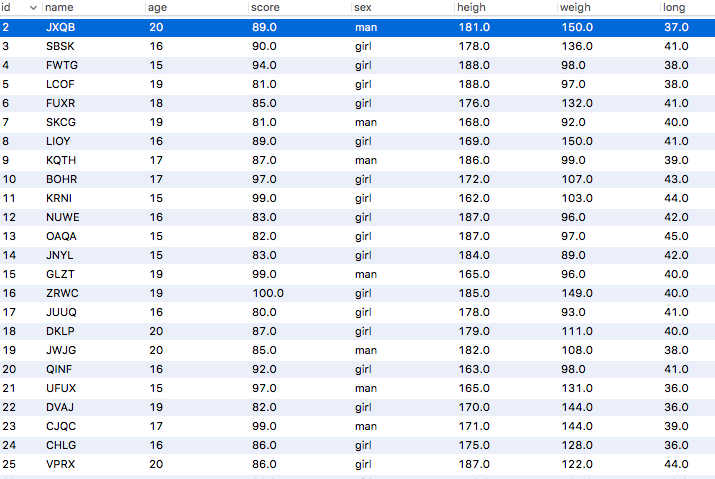
实验数据:300w+,图为截取部分数据,共8个字段
---------------------------------------------------------------------------------打死不弯分割线 ---------------------------------------------------------------------------------
查看数据量:
select count(*) FROM t_student;
结果:

---------------------------------------------------------------------------------打死不弯分割线 ---------------------------------------------------------------------------------
正常查询效率:
查询weigh字段,体重最轻的10条数据
SELECT weigh from t_student order by weigh asc LIMIT 0,10;
结果:

查询weigh、long字段,体重超过100,脚长超过40
SELECT weigh,long from t_student where weigh>100.0 and long>40
结果:

---------------------------------------------------------------------------------打死不弯分割线 ---------------------------------------------------------------------------------
使用唯一索引:CREATE INDEX index_name on table_name (column_name);
--创建索引 create INDEX index_weigh on t_student(weigh); --查询所有索引 SELECT * FROM sqlite_master WHERE type='index' ORDER BY name;
结果:索引创建成功

进行查询:
--查询
SELECT weigh from t_student order by weigh asc LIMIT 0,10;
结果:
删除索引:DROP INDEX index_name;
--删除索引
--DROP INDEX index_weigh;
--------------------------------------------------------------------------------- 打死不弯分割线 ---------------------------------------------------------------------------------
使用组合索引:CREATE INDEX index_name on table_name (column1, column2);
--创建索引 CREATE INDEX index_name on t_student (weigh,long); --查询所有索引 SELECT * FROM sqlite_master WHERE type='index' ORDER BY name;
结果:成功创建

进行查询:
--创建组合索引
CREATE INDEX index_name on t_student (weigh,long);
--查询
SELECT weigh,long from t_student where weigh>100.0 and long>40
结果:

--------------------------------------------------------------------------------- 打死不弯分割线 ---------------------------------------------------------------------------------

















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









