






 本文介绍了一种使用正则表达式提取文件中单词的方法,并通过字典统计单词出现次数。随后利用自定义Comparator实现了按单词出现频率从高到低排序,相同频率下按字典序排序的功能。
本文介绍了一种使用正则表达式提取文件中单词的方法,并通过字典统计单词出现次数。随后利用自定义Comparator实现了按单词出现频率从高到低排序,相同频率下按字典序排序的功能。
问题描述:
读取一个文件,统计其中单词出现次数,并按从高到低的顺序显示,相同顺序的字典序排列。
思路:
基于上次的程序用正则提取出文本里的单词,然后利用字典计数(先get,为null则置1,不为null则加1),全部输入字典后通过entrySet()方法输出到列表,然后实现Comparator接口的类作为Collections.sort的参数实现排序的目的。遍历列表输出。
程序片段:
主要的就是下面的实现Comparator接口的类:
1 class sortman implements Comparator<Map.Entry<String, Integer>> { 2 public int compare(Map.Entry<String, Integer> p1,Map.Entry<String,Integer> p2) 3 { 4 if(p1.getValue()<p2.getValue()) return 1; 5 else if(p1.getValue()==p2.getValue()) 6 if(p1.getKey().compareTo(p2.getKey())<0) return -1; 7 else if(p1.getKey().compareTo(p2.getKey())==0) return 0; 8 else return 1; 9 else return -1; 10 } 11 }
运行结果:
eclipse下指定命令行参数,在工作区右键,run as-> run configure,切到parameter栏,以空格为分隔输入。
第一个小程序:
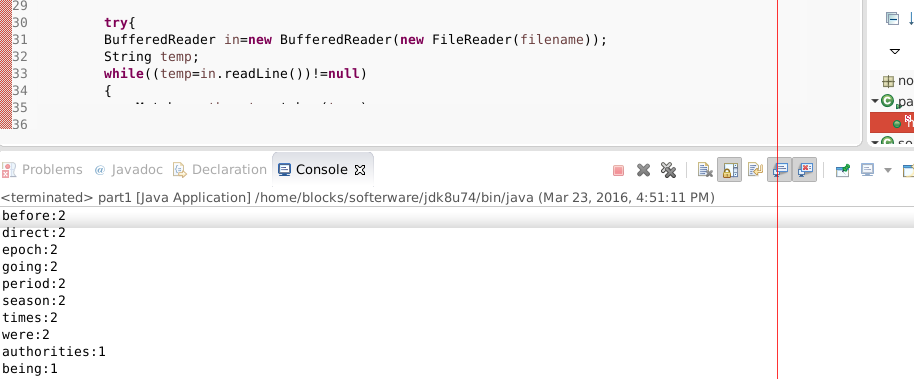
第二个小程序:
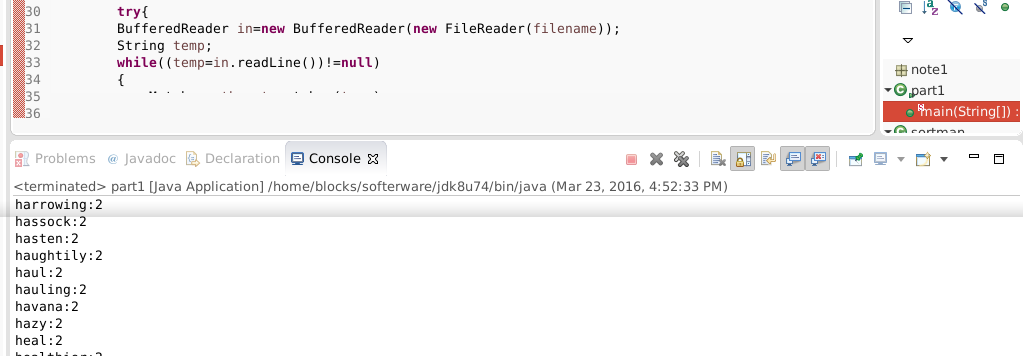
结束语:
这个程序放弃了TreeMap,因为并没有想到怎么实现Comparator接口作为TreeMap的构造函数的参数,如果是compare(<Map<String,Integer> p1, Map<String, Integer> p2)那怎么实现拿出key和value呢。。ps:知道的偷偷告诉我。然后就是统计性能的问题,linux下真没想到怎么做,百度了下说jconsole这些,还要指定pid,运行时间这么短,反应不过来。应该还没打开程序就结束了吧。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









