






 本文记录了一次Redis实例userd_memory超出maxmemory限制导致的内存告警问题,通过检查key大小、持久化数据、分析客户端缓冲区,最终定位到输出缓冲区占用未释放的问题,并详细描述了问题处理及总结。
本文记录了一次Redis实例userd_memory超出maxmemory限制导致的内存告警问题,通过检查key大小、持久化数据、分析客户端缓冲区,最终定位到输出缓冲区占用未释放的问题,并详细描述了问题处理及总结。
Redis:userd_memory使用超出maxmemory
一、问题现象
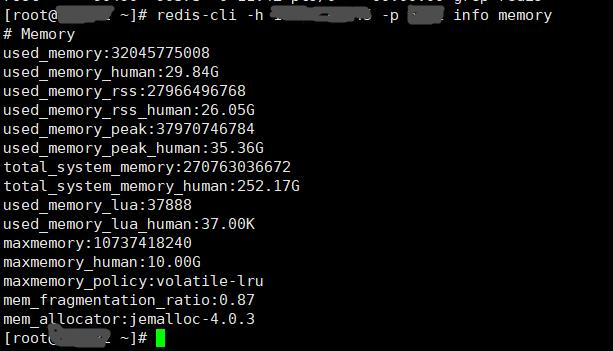
2018.12.30 19:26分,收到Redis实例内存使用告警“内存使用率299%>=80%”,检查实例info memory信息, 发现:userd memory=29.84G 而实例maxmemory=10G,集群中其它实例userd_memory均匀且保持在500M左右;
二、问题分析
1、检查此实例中的key数量和大小,排查是否存在大key,执行dbsize,显示当前实例有68个key,执行--bigkeys命令,显示最大key是个hash类型的,size为500M;
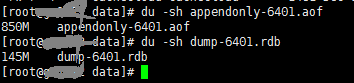
2、持久化当前实例的数据,一般情况下,实例usermemory大小会介于rdb-aof文件大小之间,实际的userdmemory不超过850M,很显然实例中没有大key写入,
实例默认开启aof,我们需要手动执行bgsave,生成dump文件;
3、集群中其它实例userd_memory均在500M左右,包括这个主实例对应的从实例;
4、上谷歌搜索后,改变分析思路,检查实例输入输出缓冲区,执行client info 找出缓冲区最大的量,再执行client list 查看客户端连接信息,发现输出缓冲区有占用未释放,
id=140220 addr=10.xx.xx.xx fd=100 name= age=1118 idle=197 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=206443 omem=4850384840 events=rw cmd=setex
其中qbuf表示输入缓冲区的量,obl、oll、omem表示输出缓冲区的量,obl表示固定缓冲区的量,oll表示动态缓冲区的量,omem表示输出缓冲区共使用的字节数,换算后是4.6G
有多个客户端连接输出缓冲区很大。
三、问题处理
1、在当前实例对应的从实例上执行failover,倒换主从关系;
2、观察之前的主实例(现在的从实例),发现userd_memory没有下降,再执行重启操作,让主从之间进行一次全量同步;
四、总结
1、在问题处理操作阶段,可以通过重启主实例,Rediscluster会自动进行主从切换,省掉一步,但为了观察过程,我选择了先切换再重启;
2、问题处理阶段,实例的dump文件大小只有100多M,和其它实例的dump文件基本一致,所以当时已不用在实例中存在的key上继续分析了,要转换思路。

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









