



 SPP_net作为2014年提出的算法,在目标检测领域扮演了重要角色。它通过引入空间金字塔池化层解决了传统CNN中输入图像尺寸固定的限制,并减少了卷积层的重复计算。本文详细介绍了SPP_net的工作原理及其优势。
SPP_net作为2014年提出的算法,在目标检测领域扮演了重要角色。它通过引入空间金字塔池化层解决了传统CNN中输入图像尺寸固定的限制,并减少了卷积层的重复计算。本文详细介绍了SPP_net的工作原理及其优势。
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPP_net 是一个2014年的文章, 也是 Object Detection 领域逐渐发展的重要一步。
R-CNN 做Object Detection的时候,是在 image 阶段是根据bounding boxes对原来的image 进行 crop,然后对cropped image进行classification。
这样做遵从Object Detection两部曲,BBox Detect & Object Classification。 但是这种方法有一个缺点: Conv层大量的重复计算。

同时,对于传统的CNN, 输入都需要固定大小的image size, 但是由于CNN的网络特点,在Conv层是不需要考虑image size 的, 只有后面的FC层才需要考虑。
所以,可以将conv 层提前。
那么, 经过改进的算法就是 SPP_net.
SPP_net 的三个优点是:
(1) Can generate a fixed-length representation regardless of image scale/size
(2) SPP uses multi-level spatial bins;
(3) SPP can pool features extracted at variable scales thanks to the flexibility of input scales
对feature map的分析:
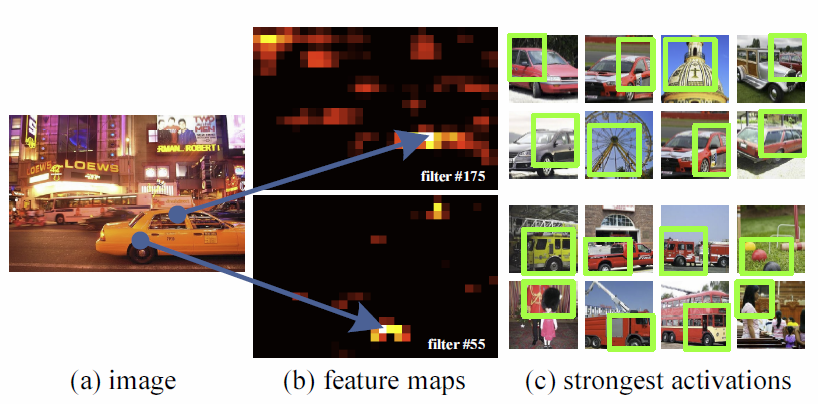
每一个 feature map 都会反应该feature map的反应强度和空间位置。 经过训练,每一个feature map都反应 the most activated by some shape.
比如: 有些feature map 对圆形反馈,有些对V型反馈。
这些feature map就做到一个提取特征的作用。(这个特征不仅仅包含形状,颜色,而且有空间特征)
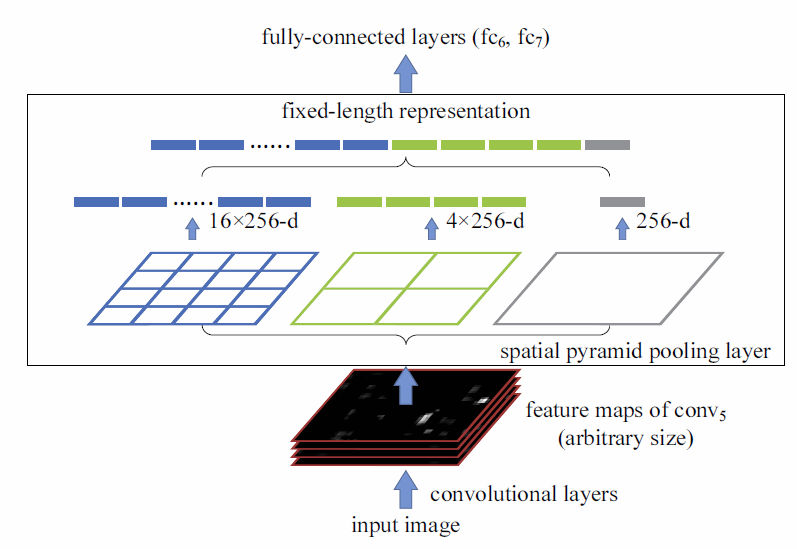
SPP_net 新加入的一种layer: spatial pyramid pooling layer
对 Conv5 层的feature maps 进行spatial pyramid pooling, 对于任意size的feature maps(width, height, channel=256), 得到典型的三种:pooling 成 (4 x 4 x channel), (2 x 2 x channel), (1 x 1 x channel), 然后将这三个maps concatenate into vector, 那么这个 vector就是 (4 x 4 + 2 x 2 + 1 x 1) x channel 维度的。
总结: 看完Faster RCNN 之后再回过头来看这些文章。发现:方法就是这样一步一步试出来,每次小小的改动,最后成为一个很实用很有效的东西。

















 4688
4688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









