






 本文详细介绍如何利用正则表达式提取器从HTTP响应中获取特定数据,包括配置方法及正则表达式的编写技巧。
本文详细介绍如何利用正则表达式提取器从HTTP响应中获取特定数据,包括配置方法及正则表达式的编写技巧。
关联:与系统交互过程中,系统返回的内容,需要在接下来的交互中用到,如防止csrf攻击而生成的token。
从前一个请求中取,用Regular Expression Extractor 正则表达式提取器
注:写在一个请求的下面
位置:在具体的http请求--后置处理器--正则表达式(关键是要弄清楚提取的值是在哪个页面生成的)
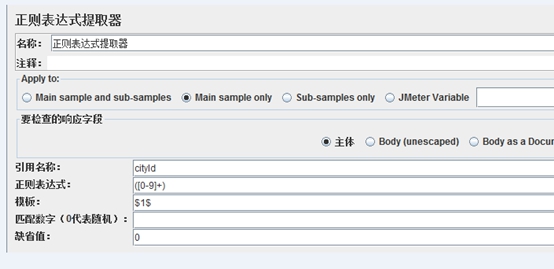
- 引用名称:其他地方引用提取值的变量名称,如填写的是:str,具体的引用方式是${str}。
- 正则表达式:提取内容的正则表达式,一般情况下确定左右边界,一定要用括号括起来,例如:session=(.*)> 或 ( [0-9] {17} ) 或count\(\*\)\n(.+)
【稍注意一下:( )表示提取,对于你要提取的内容需要用小括号括起来】
- 模板:用$$引用起来,如果在正则表达式中有多个提取表达式(多个括号括起来的东东),则可以是$1$,$2$等等,表示解析到的第几个值给str,正 则表达式的提取模式,值从1开始,值0对应的是整个匹配的表达式 如对于表达式s(.*) 值0对应str,值1对应tr
- 匹配数字(0代表随机):0代表随机,-1/负数代表全部匹配,其余正整数代表将在已提取的内容中第几个匹配的内容,如$2$代表取出第二组参数的值
- 缺省值:正则匹配失败时,取的值,一般情况下不管,空着就好。
下一步操作是在另一个HTTP请求引用该变量
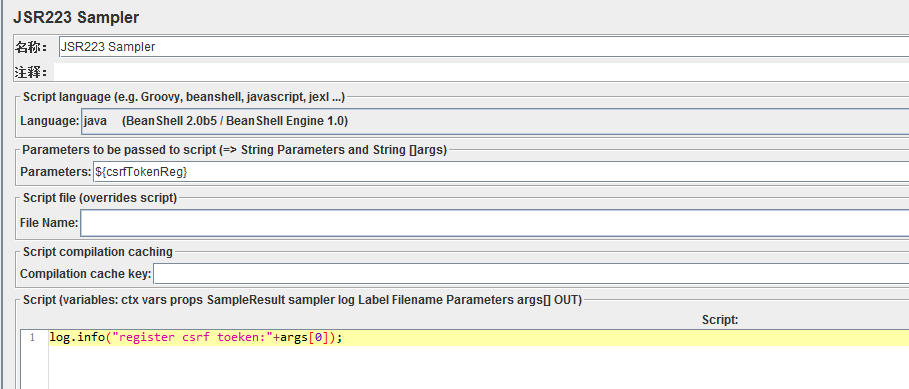
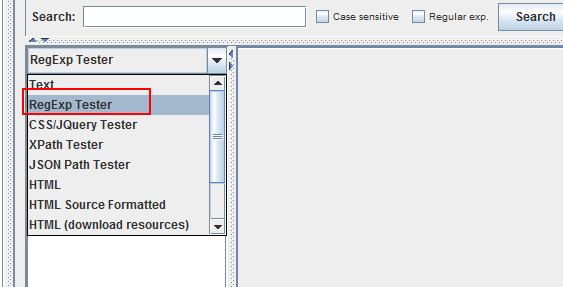
如何匹配正则?
使用察看结果树---RegExp Tester

















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









