






 本文分享了使用Python爬虫抓取小说时遇到的问题及解决方法,包括避免乱码问题和正确拼接章节URL,为爬虫初学者提供实用经验。
本文分享了使用Python爬虫抓取小说时遇到的问题及解决方法,包括避免乱码问题和正确拼接章节URL,为爬虫初学者提供实用经验。
爬虫学习的一点心得
任务:抓取某小说并下载
抓取:requests
解析:xpath,正则表达式
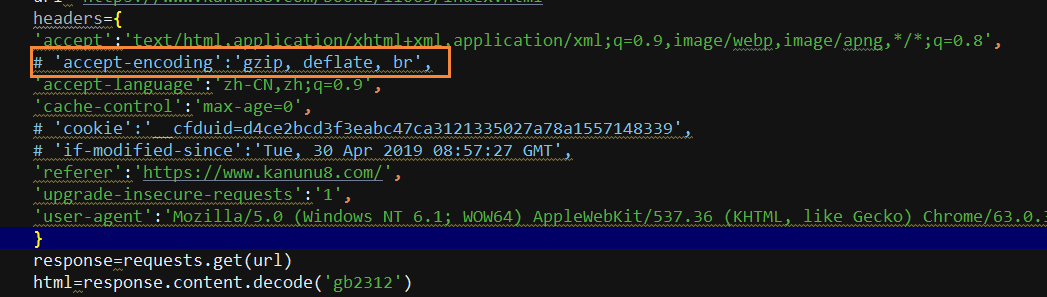
1.获取小说索引页源代码时,出现乱码,试了很多方法都不行,最后找到原因是请求头中有一参数
'accept-encoding':'gzip, deflate, br'
普通浏览器访问网页,之所以添加:
"Accept-Encoding" = "gzip,deflate"
那是因为,浏览器对于从服务器中返回的对应的gzip压缩的网页,会自动解压缩,所以,其request的时候,添加对应的头,表明自己接受压缩后的数据。
而此代码中,如果也添加此头信息,结果就是,返回的压缩后的数据,没有解码,而将压缩后的数据当做普通的html文本来处理,当前显示出来的内容,是乱码了。
删除这一参数就可以了
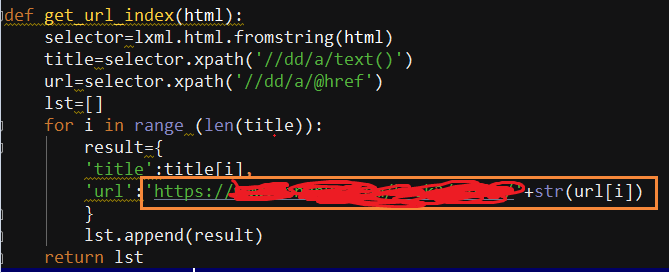
2.索引页抓取每一章节小说的url链接地址,源码中显示的地址只有一部分,需要进行拼接才是完整的url地址

















 3744
3744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









