



// str.h
#ifndef STR_H
#define STR_H
char * trim(char *c,int mode);
char** split(const char* string, char delim, int* count);
#endif
// str.c
#include <stdlib.h>
#include <string.h>
#include "str.h"
static inline int php_charmask(unsigned char *input, int len, char *mask)
{
unsigned char *end;
unsigned char c;
int result = 0;
memset(mask, 0, 256);
for (end = input+len; input < end; input++) {
c=*input;
if ((input+3 < end) && input[1] == '.' && input[2] == '.'
&& input[3] >= c) {
memset(mask+c, 1, input[3] - c + 1);
input+=3;
} else if ((input+1 < end) && input[0] == '.' && input[1] == '.') {
if (end-len >= input) {
result = -1;
continue;
}
if (input+2 >= end) {
result = -1;
continue;
}
if (input[-1] > input[2]) {
result = -1;
continue;
}
result = -1;
continue;
} else {
mask[c]=1;
}
}
return result;
}
char * trim(char *c,int mode){
if (!c)
return NULL;
register int i;
int len = strlen(c) + 1;
int trimmed = 0;
char mask[256];
php_charmask((unsigned char*)" \n\r\t\v\0", 6, mask);
if (mode & 1) {
for (i = 0; i < len; i++) {
if (mask[(unsigned char)c[i]]) {
trimmed++;
} else {
break;
}
}
len -= trimmed;
c += trimmed;
}
if (mode & 2) {
for (i = len - 1; i >= 0; i--) {
if (mask[(unsigned char)c[i]]) {
len--;
} else {
break;
}
}
}
c[len] = '\0';
return c;
}
char** split(const char* string, char delim, int* count){
if (!string )
return 0;
int i,j,c;
i = 0; j = c = 1;
int length = strlen(string);
char * copy_str = (char*) malloc(length + 1);
memmove(copy_str,string,length);
copy_str[length] = '\0';
for (; i<length; i++){
if (copy_str[i] == delim){
c += 1;
}
}
(*count) = c;
char ** str_array = malloc(sizeof(char*) * c);
str_array[0] = copy_str;
for (i = 0; i < length; i++){
if (copy_str[i] == delim){
copy_str[i] = '\0';
str_array[j++] = copy_str + i + 1;
}
}
return str_array;
}
// hashtable.h
#ifndef _HASHTABLE_H
#define _HASHTABLE_H
#define SUCCESS 0
#define FAILURE -1
#define EXISTS 1
#define NOTEXISTS -2
#define VLEN 8
#define TNLEN 32
#define create_hashtable(size, ...) \
_create_hashtable(size, #__VA_ARGS__)
#define hash_add(ht,key,value) \
_hash_add((ht),(key),(value))
#define hash_find(ht,key,value) \
_hash_find((ht),(key),(value))
#define hash_del(ht,key) \
_hash_del((ht),(key))
#define hash_exists(ht,key) \
_hash_exists((ht),(key))
#define reset(ht) ((ht)->pInternalPointer = (ht)->pListHead)
#define next(ht) ((ht)->pInternalPointer = (ht)->pInternalPointer->pListNext)
#define isnotend(ht) ((ht)->pInternalPointer != NULL)
#define nkey(ht) ((ht)->pInternalPointer->h)
#define skey(ht) ((ht)->pInternalPointer->key)
#define value(ht) ((ht)->pInternalPointer->value)
typedef unsigned long ulong;
typedef unsigned int uint;
typedef struct _bucket {
ulong h; /* hash value of key, keyvalue if key is a uint or ulong */
char * key; /* the point to key , if key is a string */
char value[VLEN]; /* store a var of builtin type in a 8bit buffer */
struct _bucket *pListNext;
struct _bucket *pListLast;
struct _bucket *pNext;
struct _bucket *pLast;
} Bucket;
typedef struct _hashtable{
int nTableSize;
int nTableMask;
int nNumOfElements;
char keyType[TNLEN];
char valueType[TNLEN];
Bucket * pInternalPointer;
Bucket * pListHead;
Bucket * pListTail;
Bucket ** arBuckets;
} HashTable;
HashTable * _create_hashtable(uint size, const char* s_typename);
int _hash_add(HashTable * ht, ...);
int _hash_find(HashTable * ht, ...);
int _hash_del(HashTable * ht, ...);
int _hash_exists(HashTable * ht, ...);
int hash_num_elements(HashTable * ht);
void hash_free(HashTable * ht);
#endif //HASHTABLE_H
// hashtable.c
#include <stdio.h>
#include <stdarg.h>
#include <string.h>
#include <stdlib.h>
#include "str.h"
#include "hashtable.h"
#define CONNECT_TO_BUCKET_DLLIST(element, list_head) do{ \
(element)->pNext = (list_head); \
(element)->pLast = NULL; \
if ((element)->pNext) { \
(element)->pNext->pLast = (element); \
} \
}while(0);
#define DECONNECT_FROM_BUCKET_DLLIST(element,list_head) do{ \
if((element)->pLast){ \
(element)->pLast->pNext = (element)->pNext; \
} \
else{ \
(list_head) = (element)->pNext; \
} \
if ((element)->pNext){ \
(element)->pNext->pLast = (element)->pLast; \
} \
}while(0);
#define CONNECT_TO_GLOBAL_DLLIST(element, ht) do{ \
(element)->pListLast = (ht)->pListTail; \
(ht)->pListTail = (element); \
(element)->pListNext = NULL; \
if ((element)->pListLast != NULL) { \
(element)->pListLast->pListNext = (element); \
} \
if (!(ht)->pListHead) { \
(ht)->pListHead = (element); \
} \
if ((ht)->pInternalPointer == NULL) { \
(ht)->pInternalPointer = (element); \
} \
}while(0);
#define DECONNECT_FROM_GLOBAL_DLLIST(element,ht) do{ \
if ((element)->pListNext){ \
(element)->pListNext->pListLast = (element)->pListLast; \
} \
else{ \
(ht)->pListTail = (element)->pListLast; \
} \
if ((element)->pListLast){ \
(element)->pListLast->pListNext = (element)->pListNext; \
} \
else{ \
(ht)->pListHead = (element)->pListNext; \
(ht)->pInternalPointer = (element)->pListNext; \
} \
}while(0);
// 计算字符串索引的hash值
static ulong hash_func(char *arKey)
{
register ulong hash = 5381;
int nKeyLength = strlen(arKey);
for (; nKeyLength >= 8; nKeyLength -= 8) {
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
}
switch (nKeyLength) {
case 7: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 6: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 5: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 4: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 3: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 2: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 1: hash = ((hash << 5) + hash) + *arKey++; break;
case 0: break;
default:
break;
}
return hash;
}
HashTable * _create_hashtable(uint size, const char* s_typename){
if (!s_typename || strlen(s_typename) == 0 || strlen(s_typename) >= TNLEN)
return NULL;
int count;
char types[TNLEN];
strcpy(types,s_typename);
char ** str_array = split(trim(types,3),',',&count);
if (count != 2){
free(str_array[0]);
free(str_array);
return NULL;
}
if (strcmp(trim(str_array[0],3),"int") &&
strcmp(trim(str_array[0],3),"long") &&
strcmp(trim(str_array[0],3),"char*")){
free(str_array[0]);
free(str_array);
return NULL;
}
if (strcmp(trim(str_array[1],3),"int" ) &&
strcmp(trim(str_array[1],3),"long" ) &&
strcmp(trim(str_array[1],3),"double") &&
strcmp(trim(str_array[1],3),"float" ) &&
strcmp(trim(str_array[1],3),"short" ) &&
strcmp(trim(str_array[1],3),"char*" ) &&
strcmp(trim(str_array[1],3),"char")){
free(str_array[0]);
free(str_array);
return NULL;
}
HashTable * ht = (HashTable*)malloc(sizeof(HashTable));
if (!ht){
free(str_array[0]);
free(str_array);
return NULL;
}
strcpy(ht->keyType, trim(str_array[0],3));
strcpy(ht->valueType,trim(str_array[1],3));
free(str_array[0]);
free(str_array);
// 创建hash表的大小
uint i = 3;
if (size>= 0x80000000) {
ht->nTableSize = 0x80000000;
} else {
while ((1U << i) < size) {
i++;
}
ht->nTableSize = 1 << i;
}
ht->arBuckets = (Bucket **) malloc(ht->nTableSize * sizeof(Bucket *));
if (!ht->arBuckets)
return NULL;
memset(ht->arBuckets,0,ht->nTableSize * sizeof(Bucket *));
ht->nTableMask = ht->nTableSize - 1;
ht->pListHead = NULL;
ht->pListTail = NULL;
ht->pInternalPointer = NULL;
ht->nNumOfElements = 0;
return ht;
}
int _hash_add(HashTable * ht, ...){
ulong h;
char * key = NULL;
int keylen = 0;
char value[8];
uint nIndex;
Bucket *p;
va_list vlist;
va_start(vlist,ht);
if(strcmp(ht->keyType,"int") == 0){
int k = va_arg(vlist,int);
h = k;
}
else if(strcmp(ht->keyType,"long") == 0){
long k = va_arg(vlist,long);
h = k;
}
else if (strcmp(ht->keyType, "char*") == 0){
char* k = va_arg(vlist,char*);
h = hash_func(k); // 只有char*字符串才会通过hash_func来计算hash值
key = k;
keylen = strlen(key);
}
else {
return FAILURE;
}
if (strcmp(ht->valueType, "char") == 0)
(*value) = (char)va_arg(vlist,int);
else if (strcmp(ht->valueType, "short") == 0)
(*(short*)value) = (short)va_arg(vlist,int);
else if(strcmp(ht->valueType, "int") == 0)
(*(int*)value) = va_arg(vlist,int);
else if (strcmp(ht->valueType, "long") == 0)
(*(long*)value) = va_arg(vlist,long);
else if (strcmp(ht->valueType, "float") == 0)
(*(float*)value) = (float)va_arg(vlist,double);
else if (strcmp(ht->valueType, "double") == 0)
(*(double*)value) = va_arg(vlist,double);
else if (strcmp(ht->valueType, "char*") == 0){
char * tmp_str = va_arg(vlist,char*);
char * new_str = (char*)malloc(strlen(tmp_str)+1);
strcpy(new_str,tmp_str);
new_str[strlen(tmp_str)] = '\0';
(*(char**)value) = new_str;
}
else
return FAILURE;
va_end(vlist);
nIndex = h & ht->nTableMask; // nIndex是对应的bucket*在二维数组arBucket**中的偏移量。
p = ht->arBuckets[nIndex]; // 如果p不为空,则说明当前计算得到的hash值之前存在。
while (p!= NULL){ // 值已存在
if (p->h == h){ // 如果2次存入的hash值都一样
if ((strcmp(ht->keyType,"char*") != 0)){ // int,long类型的话,直接覆盖更新
memcpy(p->value, value, 8);
return SUCCESS;
}
else if(strcmp(p->key,key) == 0){ // char*类型, 如果2次输入的字符串都一致,则直接覆盖
free(*(char**)p->value);
memcpy(p->value, value, 8);
return SUCCESS;
}
}
p = p->pNext;
}
p = (Bucket *) malloc(sizeof(Bucket));
if (!p ){
if (strcmp(ht->valueType, "char*") == 0){
free(*(char**)value);
}
return FAILURE;
}
p->h = h;
p->key = NULL;
memcpy(p->value,value,8);
if (0 == strcmp(ht->keyType,"char*")){
p->key = (char*)malloc(keylen +1);
memcpy(p->key,key,keylen);
p->key[keylen] = '\0';
}
CONNECT_TO_BUCKET_DLLIST(p, ht->arBuckets[nIndex]); // 如果新元素的key的hash值之前已存在,则list_head为HashTable.arBucket[nIndex].
// 如果新元素的key的hash值之前没存在过,则list_head就为NULL.
CONNECT_TO_GLOBAL_DLLIST(p, ht);
ht->arBuckets[nIndex] = p;
ht->nNumOfElements+=1;
return SUCCESS;
}
int _hash_find(HashTable * ht, ...){
ulong h;
char * key = NULL;
int keylen = 0;
uint nIndex = 0;
Bucket *p = NULL;
va_list vlist;
va_start(vlist,ht);
if (strcmp(ht->keyType,"int") == 0){
int k = va_arg(vlist,int);
h = k;
}
else if(strcmp(ht->keyType, "long") == 0){
long k = va_arg(vlist,long);
h = k;
}
else if (strcmp(ht->keyType, "char*") == 0){
char * k = va_arg(vlist,char*);
h = hash_func(k);
key = k;
keylen = strlen(key);
}
else{
return FAILURE;
}
nIndex = h & ht->nTableMask;
p = ht->arBuckets[nIndex];
while (NULL != p){
if (p->h == h){
if ((strcmp(ht->keyType, "char*") != 0)||
(strcmp(ht->keyType, "char*") == 0 && strcmp(p->key,key) == 0)){
if (strcmp(ht->valueType, "char") == 0){
char * value = va_arg(vlist,char*);
*value = (char)(*(p->value));
}
else if (strcmp(ht->valueType, "short") == 0){
short * value = va_arg(vlist,short*);
*value = *((short*)p->value);
}
else if (strcmp(ht->valueType, "int") == 0){
int * value = va_arg(vlist,int*);
*value = *((int*)p->value);
}
else if (strcmp(ht->valueType, "long") == 0){
long * value = va_arg(vlist,long*);
*value = *((long*)p->value);
}
else if (strcmp(ht->valueType, "float") == 0){
float * value = va_arg(vlist,float*);
*value = *((float*)p->value);
}
else if (strcmp(ht->valueType, "double")== 0){
double * value = va_arg(vlist,double*);
*value = *((double*)p->value);
}
else if (strcmp(ht->valueType, "char*") == 0){
char ** value = va_arg(vlist,char**);
*value = *((char**)p->value);
}
else {
va_end(vlist);
return FAILURE;
}
va_end(vlist);
return SUCCESS;
}
}
p = p->pNext;
}
va_end(vlist);
return NOTEXISTS;
}
int _hash_del(HashTable * ht, ...){
ulong h;
char * key = NULL;
int keylen = 0;
uint nIndex = 0;
Bucket *p = NULL;
va_list vlist;
va_start(vlist,ht);
if (strcmp(ht->keyType,"int") == 0){
int k = va_arg(vlist,int);
h = k;
}
else if(strcmp(ht->keyType, "long") == 0){
long k = va_arg(vlist,long);
h = k;
}
else if (strcmp(ht->keyType, "char*") == 0){
char * k = va_arg(vlist,char*);
h = hash_func(k);
key = k;
keylen = strlen(key);
}
else{
return FAILURE;
}
va_end(vlist);
nIndex = h & ht->nTableMask;
p = ht->arBuckets[nIndex];
while (NULL != p){
if (p->h == h){
if ((strcmp(ht->keyType, "char*") != 0)||
(strcmp(ht->keyType, "char*") == 0 && strcmp(p->key,key) == 0)){
DECONNECT_FROM_BUCKET_DLLIST(p,ht->arBuckets[nIndex]);
DECONNECT_FROM_GLOBAL_DLLIST(p,ht);
if (p->key) {free(p->key);p->key = NULL;}
if (strcmp(ht->valueType, "char*") == 0) free(*(char**)p->value);
free(p); p = NULL;
ht->nNumOfElements -= 1;
return SUCCESS;
}
}
p = p->pNext;
}
return SUCCESS;
}
int _hash_exists(HashTable * ht, ...){
ulong h;
char * key = NULL;
int keylen = 0;
uint nIndex = 0;
Bucket *p = NULL;
va_list vlist;
va_start(vlist,ht);
if (strcmp(ht->keyType,"int") == 0){
int k = va_arg(vlist,int);
h = k;
}
else if(strcmp(ht->keyType, "long") == 0){
long k = va_arg(vlist,long);
h = k;
}
else if (strcmp(ht->keyType, "char*") == 0){
char * k = va_arg(vlist,char*);
h = hash_func(k);
key = k;
keylen = strlen(key);
}
else{
return FAILURE;
}
va_end(vlist);
nIndex = h & ht->nTableMask;
p = ht->arBuckets[nIndex];
while (NULL != p){
if (p->h == h){
if ((strcmp(ht->keyType, "char*") != 0)||
(strcmp(ht->keyType, "char*") == 0 && strcmp(p->key,key) == 0)){
return EXISTS;
}
}
p = p->pNext;
}
return NOTEXISTS;
}
int hash_num_elements(HashTable *ht)
{
return ht->nNumOfElements;
}
void hash_free(HashTable * ht){
Bucket *p, *q;
p = ht->pListHead;
while (p != NULL) {
q = p;
p = p->pListNext;
if (strcmp(ht->keyType,"char*") == 0 &&
q->key){
free(q->key);
q->key = NULL;
}
if (strcmp(ht->valueType,"char*") == 0){
free(*(char**)q->value);
}
free(q);
q = NULL;
}
if (ht->arBuckets) {
free(ht->arBuckets);
ht->arBuckets = NULL;
}
free(ht);
}
上面的2个文件放在util文件夹内,此处的makefile为:
// util/makefile
其中 -DNDEBUG 加了之后使所有 assert 失效。
-O3 使代码优化,gdb调试时不显示信息。
SHELL = /bin/bash
CC = gcc -std=c99
CFBASE = -Wall -pedantic
CFLAGS = $(CFBASE) -DNDEBUG -O3 -fpic
LD = gcc
SOFLAGS = -shared
OBJS = hashtable.o str.o
SOS = libht.so libstr.so
STATICS = libhts.a libstrs.a
all: $(OBJS)
so: $(SOS)
statics:$(STATICS)
hashtable.o: hashtable.h hashtable.c makefile
$(CC) $(CFLAGS) -c hashtable.c -o $@
str.o: str.h str.c makefile
$(CC) $(CFLAGS) -c str.c -o $@
libht.so: hashtable.o str.o
$(LD) $(SOFLAGS) hashtable.o str.o -o $@
libstr.so : str.o
$(LD) $(SOFLAGS) str.o -o $@
libhts.a: hashtable.o str.o
ar cr libhts.a hashtable.o str.o
libstrs.a:str.o
ar cr libstrs.a str.o
#-----------------------------------------------------------------------
# Clean up
#-----------------------------------------------------------------------
clean:
rm -f $(PRGS) *.o *.so *.a
// src/test.c 测试代码
#include <stdio.h>
#include <string.h>
#include "hashtable.h"
int main(){
printf("\n<int,double>\n");
HashTable *ht = create_hashtable(100,int,double);
double t = 2000000000.0;
hash_add(ht,100,t);
hash_add(ht,20,15.0);
double v;
hash_find(ht,20,&v);
printf("\t20 :%lf\n",v);
hash_find(ht,100,&v);
printf("\t100 :%lf\n",v);
printf("\tset 100's value = 200.0\n");
hash_add(ht,100,200.0);
hash_find(ht,100,&v);
printf("\t100 :%lf\n",v);
int key;
double tvalue;
printf("\n\t[itering...]\n");
for (reset(ht);isnotend(ht);next(ht)){
key = nkey(ht);
tvalue = *(double*)value(ht);
printf("\tkey: %d, value:%lf\n",key,tvalue);
}
hash_free(ht);
ht = NULL;
printf("\n<char*,int>\n");
HashTable *ht1 = create_hashtable(100,char*,int);
hash_add(ht1,"song",1000);
hash_add(ht1,"abcd",1235451254);
int value;
hash_find(ht1,"song",&value);
printf("\tsong: %d\n",value);
hash_find(ht1,"abcd",&value);
printf("\tabcd: %d\n",value);
char * t_key;
printf("\n\t[itering...]\n");
for (reset(ht1);isnotend(ht1);next(ht1)){
t_key = skey(ht1);
value = *(int*)value(ht1);
printf("\tkey: %s, value:%d\n",t_key,value);
}
free(ht1);
ht1 = NULL;
printf("\n<char*,double>\n");
HashTable *ht2 = create_hashtable(100, char*, double);
hash_add(ht2,"whatafuck",12314524.1235);
hash_add(ht2,"xiaoqiang",123.123);
double b;
hash_find(ht2,"whatafuck", &b);
printf("\twhatafuck: %lf\n",b);
hash_find(ht2,"xiaoqiang", &b);
printf("\txiaoqiang: %lf\n",b);
if(hash_exists(ht2,"xiaoqiang") == EXISTS){
printf("\texists xiaoqiang\n");
}
printf("\thash element counts: %d\n",hash_num_elements(ht2));
printf("\tdel xiaoqiang...\n");
hash_del(ht2,"xiaoqiang");
if(hash_exists(ht2,"xiaoqiang") == NOTEXISTS){
printf("\tnot exists xiaoqiang\n");
}
else if (hash_exists(ht2,"xiaoqiang") == EXISTS){
printf("\tstill exists xiaoqiang\n");
}
printf("\thash element counts: %d\n",hash_num_elements(ht2));
hash_free(ht2);
ht2= NULL;
printf("\n<char*,char*>\n");
HashTable * ht3 = create_hashtable(100,char*,char*);
hash_add(ht3,"fuck","make love");
hash_add(ht3,"like","not love");
char * v_tmp;
hash_find(ht3,"fuck",&v_tmp);
printf("\tfuck: %s\n", v_tmp);
hash_find(ht3,"like", &v_tmp);
printf("\tlike: %s\n",v_tmp);
printf("\n\t[itering...]\n");
for(reset(ht3);isnotend(ht3);next(ht3)){
t_key = skey(ht3);
v_tmp = *(char**)value(ht3);
printf("\tkey: %s, value:%s\n",t_key,v_tmp);
}
hash_free(ht3);
ht3 = NULL;
return 0;
}
// 执行结果:
???
// src/makefile
SHELL = /bin/bash
UTILDIR = ../util
CC = gcc -std=c99
CFBASE = -Wall -pedantic
CFLAGS = $(CFBASE) -DNDEBUG -O3
INCS = -I$(UTILDIR)
LD = gcc
LIBDIR = -L../util
LIBS = -lm -lhts
OBJS = test.o
PRGS = main
#-----------------------------------------------------------------------
# Build Program
#-----------------------------------------------------------------------
all: $(PRGS)
main: $(OBJS) statics makefile
$(LD) $(OBJS) $(LIBDIR) $(LIBS) -o $@
#-----------------------------------------------------------------------
# Main Program
#-----------------------------------------------------------------------
test.o: test.c makefile
$(CC) $(CFLAGS) $(INCS) -c test.c -o $@
#-----------------------------------------------------------------------
# External Modules
#-----------------------------------------------------------------------
statics:
cd $(UTILDIR); $(MAKE) libhts.a
#-----------------------------------------------------------------------
# Installation
#-----------------------------------------------------------------------
install:
cp $(PRGS) $(HOME)/bin
#-----------------------------------------------------------------------
# Clean up
#-----------------------------------------------------------------------
localclean:
rm -f *.o *~ *.flc core $(PRGS)
clean:
$(MAKE) localclean
cd $(UTILDIR); $(MAKE) clean
内存结构:
假设我们创建一个size(桶数)为6的HashTable,并且尝试插入4个元素,其中第一个元素和第四个元素hash冲突,第二个元素与第三个元素hash冲突。那么按照设计,该HashTable在内存中的结构如下图所示:
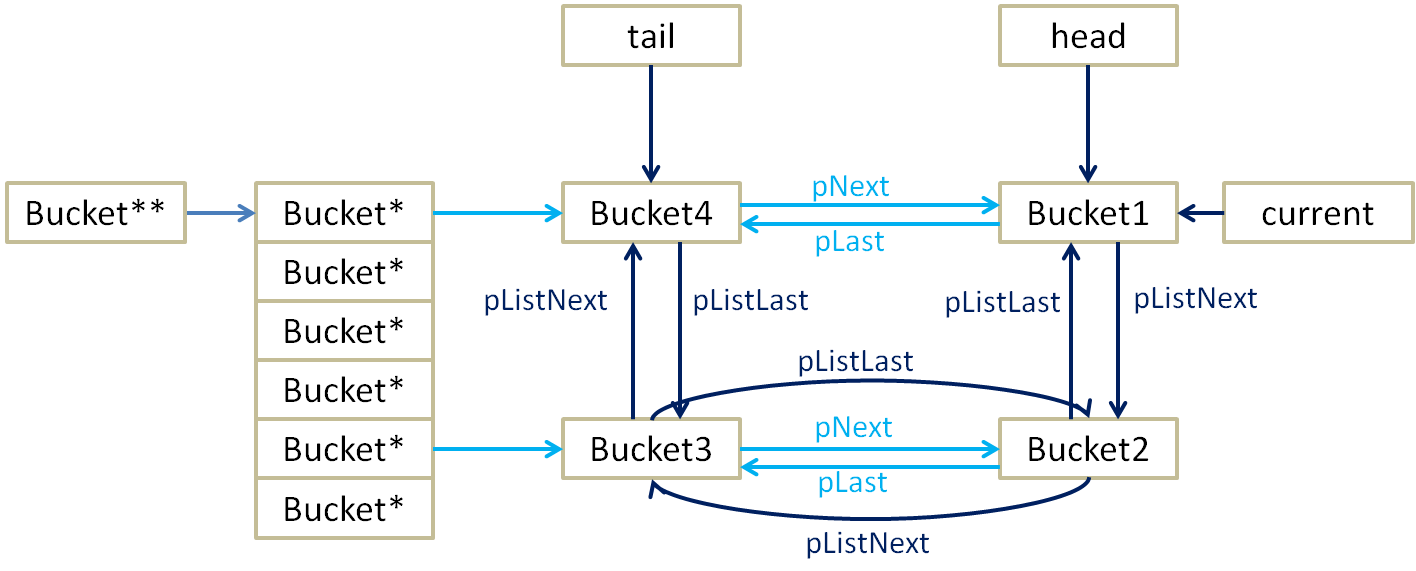
_hash_add()函数先计算要插入的字符串索引的hash值,并与nTableMask做按位与,得到nindex,这个nIndex就是对应的bucket*在二维数组arBucket**中的偏移量。根据代码逻辑,如果nIndex位置不为空,则说明当前计算得到的hash值之前存在。如果连key也相同则执行更新操作,更新了对应的值之后直接退出即可。
在需要有新元素插入到HashTable时,构造好的新元素会经过两步来链入该HashTable:
#define CONNECT_TO_BUCKET_DLLIST(element, list_head) \
(element)->pNext = (list_head); \
(element)->pLast = NULL; \
if ((element)->pNext) { \
(element)->pNext->pLast = (element); \
}
在这一步中如果新元素的key的hash值之前存在过,则list_head为HashTable.arBucket[nIndex],nIndex怎么来的前面已经说过了。在这一步过后会将HashTable.arBucket[nIndex]赋值为当前的新元素.
如果新元素的key对应的hash之前没有存在过,则list_head就为NULL,因为HashTable.arBucket[nIndex]为NULL。
#define CONNECT_TO_GLOBAL_DLLIST(element, ht) \
(element)->pListLast = (ht)->pListTail; \
(ht)->pListTail = (element); \
(element)->pListNext = NULL; \
if ((element)->pListLast != NULL) { \
(element)->pListLast->pListNext = (element); \
} \
if (!(ht)->pListHead) { \
(ht)->pListHead = (element); \
} \
if ((ht)->pInternalPointer == NULL) { \
(ht)->pInternalPointer = (element); \
}
关于这一步会对HashTable的内容有什么样的影响,请参看下面的动态示例。
1.
插入第一个元素A,假设其key对应的hash值为1
则插入之后,内存中的状态如下:
HashTable.arBucket[1]=A;
HashTable.pListHead = A
HashTable.pListTail = A
HashTable.pInternalPointer = A
A.pNext = null
A.pLast = null
A.pListLast = null
A.pListNext = null
2.
插入第二个元素B,假设其key对应的hash值为2
则插入之后内存的状态如下:
HashTable.arBucket[2] = B;
HashTable.pListHead = A
HashTable.pListTail = B
HashTable.pInternalPointer = A //这个只在第一次的时候设置
A.pNext=null
A.pLast = null
A.pListNext = B
A.pListLast = null
B.pListLast = A
B.pListNext = null
B.pNext = null
B.pLast = null
3.
插入第三个元素C,假设其key的hash值为1,和A相同
则插入之后内存状态如下:
HashTable.arBucket[1] = C;
HashTable.pListHead = A
HashTable.pListTail =C
HashTable.pInternalPointer = A //这个只在第一次的时候设置
A.pNext=null
A.pLast = C
A.pListNext = B
A.pListLast = null
B.pNext = null
B.pLast = null
B.pListLast = A
B.pListNext = C
C.pNext = A
C.pLast = null
C.pListNext = null
C.pListLast = B
插入A,B,C三个值之后的内存中状态即为:
HashTable.arBucket[1] = C;
HashTable.pListHead = A
HashTable.pListTail =C
HashTable.pInternalPointer = A
A.pNext=null
A.pLast = C
A.pListNext = B
A.pListLast = null
B.pNext = null
B.pLast = null
B.pListLast = A
B.pListNext = C
C.pNext = A
C.pLast = null
C.pListNext = null
C.pListLast = B
OK,A、B、C三个元素都已插入了,现在我们要实现两个任务:
1.
查找某key的元素值(value):
如果我们要访问A元素,则提供A的key:key_a,得到对应的hash值为1
然后找HastTable.arBucket[1]。这时HastTable.arBucket[1]其实为C不是A,但由于C的key不等于A的key,因此,要沿着pNext的指针找下去,直到NULL,而此时C.pNext就是A,即找到了key_a对应的值A。
总之由key查找一个元素时,首先要hash,然后顺着hash后的索引位置的pNext指针一直找下去,直到NULL,如果遇到了和要查找的key相同的值,则找到,否则找不到。
2.
遍历数组:
由于我们的例子中的key是字符串类型的,全部循环遍历不能用for。只能用foreach,那foreach的遍历是如何实现的呢?
简单,根据最后的HashTable的状态,我们从HastTable.pListHead开始沿着pListNext指针顺序找下去即可了。以本文例子为例,则结果为:
HashTable.pListHead====>A
A.pListNext ====>B
B.pListNext ====>C
则最后的遍历顺序就是A,B,C,发现foreach的遍历顺序是和元素插入到数组的顺序相关的。
如果插入的元素的key不是字符串,而是数值。则可以省去做计算hash值这一步,直接拿数值的key做为hash值使用。
这样就不存在hash冲突的问题,这样也就不会用到每个元素的pNext、pLast两个指针了,这两个指针都只会是NULL。
这样我们可以通过使用for循环来遍历数组了,因为不存在hash冲突。
同样,如果我们使用foreach来遍历数组的话,遍历顺序还是元素的插入顺序.
转自: http://liuzhiqiangruc.iteye.com/blog/1871334

















 1208
1208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









