






 本文记录了一次结对编程的经历,详细介绍了从需求分析到代码实现的过程,并针对字符串操作进行了重点设计,采用Dictionary进行单词频率统计。
本文记录了一次结对编程的经历,详细介绍了从需求分析到代码实现的过程,并针对字符串操作进行了重点设计,采用Dictionary进行单词频率统计。
第三次作业——结对编程
| github地址 | https://github.com/damaoya |
| 结对伙伴的作业地址 |
https://www.cnblogs.com/ArthurUnreal/p/10659810.html
|
一.设计与讨论
1)下面是我和结对伙伴的讨论照

2)PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 25 | 30 |
| Estimate | 估计这个任务需要多少时间 | 25 | 30 |
| Development | 开发 | 870 | 1000 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 50 |
| Design Spec | 生成设计文档 | 30 | 25 |
| Design Review | 设计复审 (和同事审核设计文档) | 60 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| Design | 具体设计 | 75 | 80 |
| Coding | 具体编码 | 450 | 500 |
| Code Review | 代码复审 | 105 | 160 |
| Test | 测试(自我测试,修改代码,提交修改) | 70 | 130 |
| Reporting | 报告 | 80 | 80 |
| Test Report | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 20 | 25 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 25 |
|
| 合计 | 1620 | 1840 |
3)项目设计思路
- 此次设计的程序主要是在字符串的操作上,所以对文件方面就不会有太过复杂的操作,我们第一个想法是从文件中读出所有内容并保存到一个字符串后,就结束所有的文件操作(基础功能方面)。
- 之后的第一个要求是统计文件字符数(除汉字),去汉字后引用string.Length语句就能轻松办到。
- 第二个要求需要统计单词数,要求较复杂,我们的想法起初是直接按照ToLower().split(' ',','),按空格和‘,’分离每个单词并小写化后成为数组单元,然后直接进入循环判断,但是实际操作的时候出现了问题,单用split()并不能去除换行符,于是伙伴建议在split()前使用Replace()语句将换行符"\r\n"换成空字符"",但是最后的结果反而多出了为空的元素(可能里面是空格或者其他的东西),所以使用了GetHashCode()语句得到此元素的哈希代码,做了个判断语句以去除该元素。默认所有数组元素为单词,将计为总数,然后判断数组若小于4以及数组元素大于4时若前4位元素的Ascii码是否为a—z之外,若满足条件,则在总数中减去1。
- 行数可以直接通过统计从未去换行符之前的数组元素获得,关键语句IndexOfAny(),所以找行数的步骤可以直接在统计单词时进行。
- 第五个要求我们试图引用了第二个要求里的数组,引用了计数数组和排序集合Dictionary<string,int>,然后将排序后的集合与计数数组一一对应,然后输出。
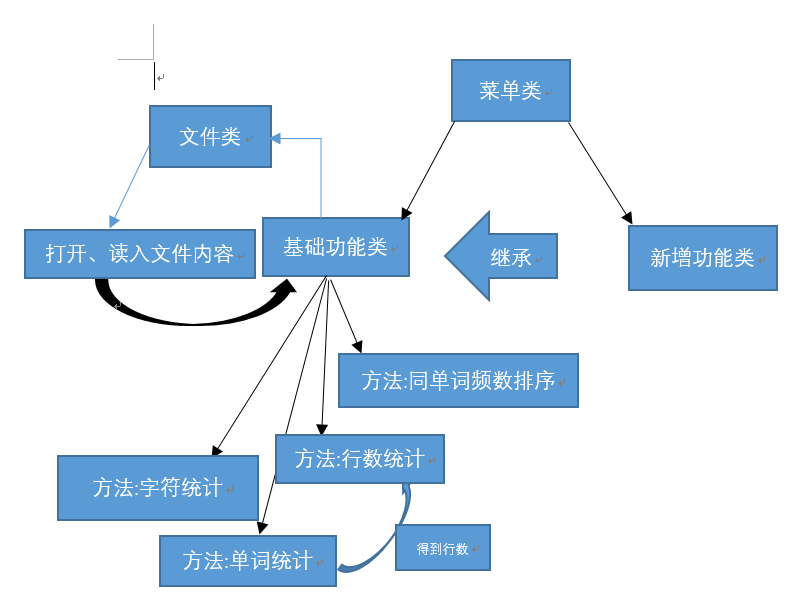
4.基础功能的步骤设计图
二、代码说明
1.详见结对伙伴
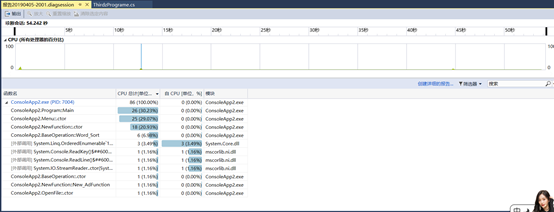
2.效能分析
三、代码规范
1.函数名直接使用英文单词,保证更快速的读懂代码。
2.一个类实现一个功能。
3.括号上下对齐。
4.变量名私有化。
5.尽量的注释。
四、代码复审
//林某人的院子:为避免新功能类代码实现重复基本功能,所以用了继承。
//既实现了新功能中依旧能调用基本功能,也实现了使用基本功能类里的成员达到新功能避免写入重复函数、重复成员的问题。
//并且在做排序时,一直想不到一个能将单词与频数一一对应的方法,于是咨询了同班同学,给了我们一个特别好的方法Dictionary<string,int>
//大猫呀:此次项目的读入转换时总是出现换行符无法去掉以及数组中出现空格成员的问题,
//但修改replace()和spilt()的函数后依旧无法解决该问题,
//所以为解决这类问题,我们得到数组中空成员的哈希代码,在数组中循环判断是否为该哈希代码,若为此代码,则删除该成员,全体进一位且数组元素总数少一位
五、总结
一些东西东西想象的和实际的不一样,要自己实际操作了之后才知道。

















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









