






Val编程中,对于汉字的读取不是很友好,利用fileget直接读取记事本产生的文件字符串会导致乱码的产生。因为Val只支持使用utf-8进行编码,因此读取的文本需要进行utf-8格式转换。
在GBK中,汉字占两个字节。并且每个字节都大于128.可以通过直接读取位来进行转换来读取汉字。通过读取的两个数字来获得汉字的ASCII码。
而在utf-8中具有自己的编码方式。模拟器中读取的是用GBK编码,而显示的是UTF-8.
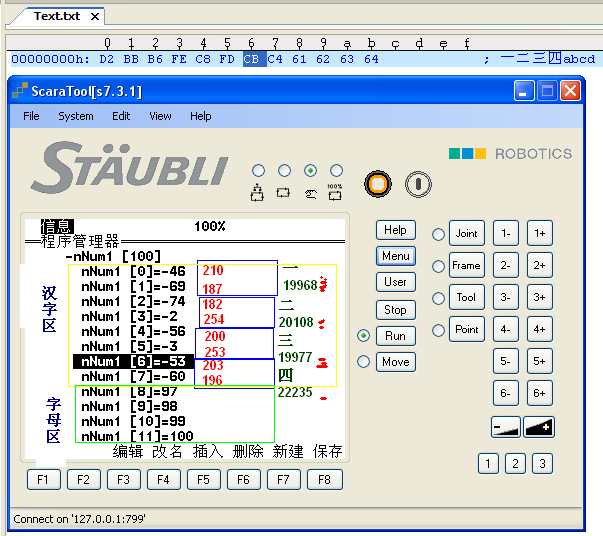
utf-8格式说明:
这是为传输而设计的编码,其系列还有UTF-7和UTF-16
其中UTF-16和Unicode编码大致一样, UTF-8就是以8位为单元对Unicode进行编码。从Unicode到UTF-8的编码方式如下:
Unicode编码(16进制) UTF-8 字节流(二进制)
0000 - 007F 0xxxxxxx
0080 - 07FF 110xxxxx 10xxxxxx
0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx
例如“汉”字的Unicode编码是6C49。6C49在0800-FFFF之间,所以肯定要用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 110001 001001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
推荐使用UltraEdit进行编辑。
通过读取汉字文本实现效果:
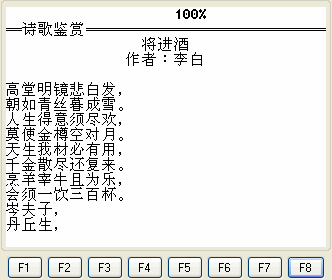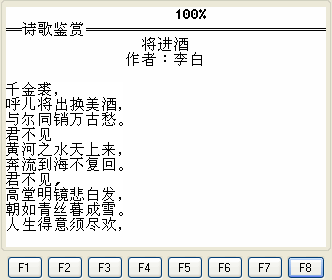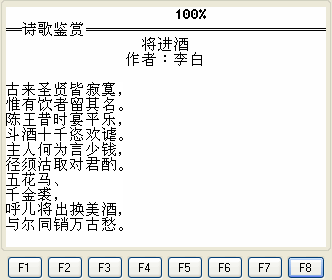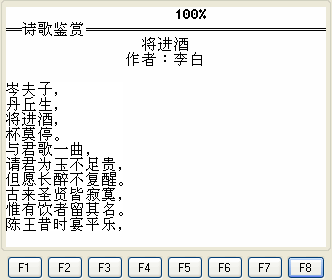
代码:
begin
//屏幕预处理
cls()
userPage()
setTextMode(0)
//关闭所有文件
$fileClose(0)
$fileClose(1)
$fileClose(2)
$fileClose(3)
$fileClose(4)
$fileClose(5)
$fileClose(6)
$fileClose(7)
$fileClose(8)
$fileClose(9)
//检查文件是否存在
if !$fileExists("Disk://Text.txt")
popUpMsg("文件不存在!")
return
endIf
//打开文件
nFileID=$fileOpen("Disk://Text.txt","r")
if nFileID<0 or nFileID>9
popUpMsg("文件打开错误!")
return
endIf
//读取文件
resize(sData,1,1)
while $fileGet(nFileID,l_sBuff,1)==1
if l_sBuff!=""
sData[size(sData)-1]=l_sBuff
append(sData)
endIf
endWhile
//去掉最后一行空白
resize(sData,1,size(sData)-1)
// 关闭文件
$fileClose(0)
$fileClose(1)
$fileClose(2)
$fileClose(3)
$fileClose(4)
$fileClose(5)
$fileClose(6)
$fileClose(7)
$fileClose(8)
$fileClose(9)
//显示文件
title("诗歌鉴赏")
//诗歌名
for l_nIndex=0 to 1
gotoxy((39-getDisplayLen(sData[l_nIndex]))/2,l_nIndex)
put(sData[l_nIndex])
endFor
//轮流显示
while true
for l_nIndex=0 to 9
gotoxy(0,l_nIndex+3)
l_nNum=l_nNum+1
if l_nNum==size(sData)
l_nNum=2
endIf
l_nNum=max(2,l_nNum)
put(left(sData[l_nNum]+" ",35))
endFor
delay(0.4)
endWhile
end

















 4346
4346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









