



 本文介绍了一种求解强连通分量的方法:首先进行一次正常的深度优先搜索(DFS),然后反转所有边的方向,根据第一次DFS的结束时间逆序再次进行DFS。通过这种方法能够有效地找到图中的所有强连通分量。
本文介绍了一种求解强连通分量的方法:首先进行一次正常的深度优先搜索(DFS),然后反转所有边的方向,根据第一次DFS的结束时间逆序再次进行DFS。通过这种方法能够有效地找到图中的所有强连通分量。
第一次DFS是正常顺序;第二次将edge反向,然后从Finish time最后的点开始DFS。
如下分别是两次DFS。
逆序即以b为源节点开始,会得到b->a->e; c->d; g->f; h;四棵子树,即四个强连通分量。
现在解释一下为什么要先反向?
以C结点为例,图未反向时,我们从C能遍历到的结点有,c->g->h->f->d。
图反向后,我们从C能遍历到的结点有,c->d。(注意图反向后,我们是从b开始DFS的)从这里我们可以看出c,d就是一个强连通子图。因为从c的正向出发可以到达d,从反向出发也能到达d,那就说明c,d之间两两都有路径。
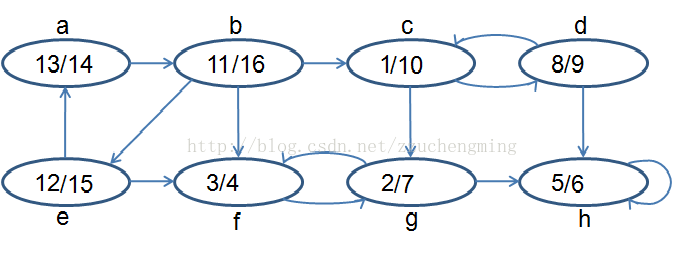
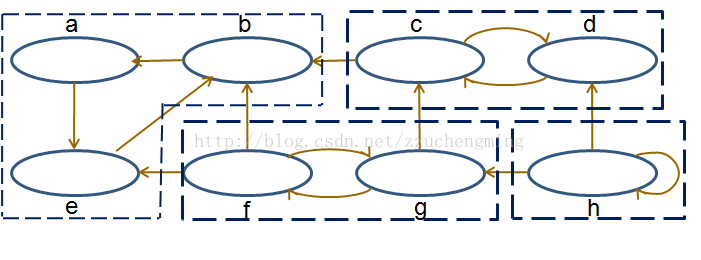
所以我们发现,c->d,而反向后c->d说明d->c,说明c,d是一个强连通分量。相当于反向前和反向后求交集。

















 9241
9241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









