



 本文介绍了HDFS中因小文件过多导致的问题及解决方案,包括如何使用fsimage文件进行小文件统计,以及如何通过Hive进行小文件排查。此外,还提供了具体的SQL查询示例来帮助用户更好地理解和解决HDFS中的小文件问题。
本文介绍了HDFS中因小文件过多导致的问题及解决方案,包括如何使用fsimage文件进行小文件统计,以及如何通过Hive进行小文件排查。此外,还提供了具体的SQL查询示例来帮助用户更好地理解和解决HDFS中的小文件问题。
一,背景
hdfs的海量文件信息都是存储在datanode上,datanode会定时发送心跳到namenode,namenode会把这些文件,目录,节点信息都以内存对象形式存在内存中,如果小文件过多(小文件是指大小远小于dfs.blocksize,一般在大集群中都设置为128M以上,默认值64M),会消耗大量的namenode内存,给集群的管理带来很大的压力,
另外一方面namendoe会将所有客户端的写操作记录在editlog,secondary namenode会周期性合并快照文件fsimage和edits成新的fsimage,具体过程如下图所示
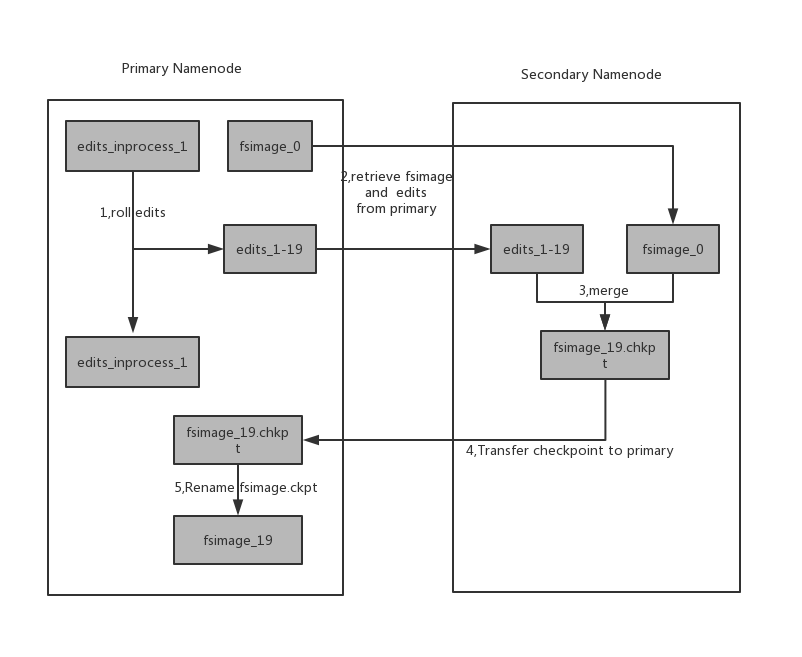
1,secondary namenode 通知primary namenode将事务id滚动存入editlog文件,primary namenode将以事务起始id和结束id做edit文件名后缀更新新的edit文件
2,secondary namenode 通过http get的方式从primary namenode获取到最新的fsimage和edit文件
3,secondary namenode将fsimage 文件加载到内存中,从edit文件中合并新的事务id,生成一个新的fsimage文件
4,secondary namenode 通过http put的方式将最新的fsimage传到primary namenode,primary namenode以此为临时.ckpt文件
5, primary namenode重命名该临时文件为fsimage文件
二,小文件的查找
现在从fsimage文件对hdfs中的文件大小做一个简单的统计,方便后续的小文件排查
1,如下命令从fsimage文件解析出文本格式的文件,再导入到hive文件(生产环境最好是将fsimage传到低负载节点,加载fsimage会非常消耗内存)
HADOOP_CLIENT_OPTS="-Xmx60000M" ; 如果报oom错误需要将client 的jvm调大 nohup hdfs oiv -p Delimited -i ./fsimage_0000000016419636404 -o ./fsimage_text &
2,创建hive表,存储fsimage文件
create table default.fsimage ( path string, num_replication int, modification_time string, access_time string, block_size int, num_blocks int, num_bytes BIGINT, ns_quota int, ds_quota string, permission string, username string, groupname string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE; load data local inpath '/data/fsimage_text' into table default.fsimage;
3, 从fsimage表中找出hdfs 中每一级目录文件大小的分布,正对找出的小文件排出整改计划
select regexp_replace(path,'/[0-9-A-z_\.=]+$',"") dir, sum(case when num_bytes < 1024*1024*1 then 1 else 0 end ) fnum_1M, sum(case when num_bytes >= 1024*1024*1 and num_bytes < 1024*1024*10 then 1 else 0 end ) fnum_1M_10M, sum(case when num_bytes >= 1024*1024*10 and num_bytes < 1024*1024*50 then 1 else 0 end) fnum_10M_50M, sum(case when num_bytes >= 1024*1024*50 and num_bytes < 1024*1024*100 then 1 else 0 end) fnum_50M_100M, sum(case when num_bytes >= 1024*1024*100 and num_bytes < 1024*1024*256 then 1 else 0 end) fnum_100M_256M, sum(case when num_bytes >= 1024*1024*256 then 1 else 0 end) fnum_256M from default.fsimage where num_blocks >0 group by regexp_replace(path,'/[0-9-A-z_\.=]+$',"") order by fnum_1M desc limit 50
4,另外还找出第三级目录下,每个目录的文件数,或者大小倒序(可以筛选出要压缩的大表或者大文件)
SELECT regexp_extract(path,'(/[0-9-A-z_\.=]+/[0-9-A-z_\.=]+/[0-9-A-z_\.=]+)',1) dir, count(*) filescn, sum(num_bytes)/(1024*1024*1024*1024.0) sizeTB from default.fsimage where num_blocks >0 group by regexp_extract(path,'(/[0-9-A-z_\.=]+/[0-9-A-z_\.=]+/[0-9-A-z_\.=]+)',1) order by filescn desc limit 50;
5,找出以某种特征结尾的文件, 有些空文件可以清理(比如_SUCCESS结尾)
select path from default.fsimage where num_blocks >0 and regexp_extract(path,'.*_SUCCESS$',0)<>'' limit 50
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsImageViewer.html

















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









