






 本文深入解析Cassandra数据库的特性、架构、数据模型及操作方法,包括安装配置、CQL语言使用、表操作、批处理、数据读写流程等,旨在为开发者提供全面的Cassandra学习指南。
本文深入解析Cassandra数据库的特性、架构、数据模型及操作方法,包括安装配置、CQL语言使用、表操作、批处理、数据读写流程等,旨在为开发者提供全面的Cassandra学习指南。
Apache Cassandra的一些值得注意的地方
Cassandra的特点
Cassandra的历史
Cassandra 架构
Cassandra中的数据复制
Cassandra的组件
Cassandra 查询语言
写操作
读操作
Cassandra 数据模型
集群(Cluster)
键空间 (Keyspace)
列族
列
超级列
Cassandra 和 RDBMS 的数据模型
总结
Cassandra 安装
安装软件
开发环境
Cassandra参考API
集群(Cluster)
方法
Cluster.Builder
方法
会话
方法
Cassandra Cqlsh
启动cqlsh
Cqlsh命令
记录的Shell命令
CQL数据定义命令
CQL数据操作指令
CQL字句
Cassandra Shell命令
Help
Capture
Consistency
Copy
Describe
Cassandra Keyspace操作
创建Keyspace
使用Cqlsh创建一个Keyspace
语句
replication
示例
验证
Durable_writes
示例
验证
use keyspace
示例
使用Java API创建一个Keyspace
第1步:创建一个集群对象
第2步:创建会话对象
第3步:执行查询
第4步:使用KeySpace
修改Keyspace
使用Cqlsh修改Keyspace
语句
replication
示例
更改 Durable_writes
使用Java API修改键空间
第1步:创建一个集群对象
第2步:创建会话对象
第3步:执行查询
删除Keyspace
使用Cqlsh删除键空间
语句
示例
验证
使用Java API删除键空间
第1步:创建群集对象
第2步:创建会话对象
第3步:执行查询
Cassandra 表操作
Cassandra 创建表
使用Cqlsh创建表
语句
定义列
主键
示例
验证
使用Java API创建表
第1步:创建群集对象
第2步:创建会话对象
第3步:执行查询
Cassandra 修改表
使用Cqlsh改变表
句法
添加列
示例
验证
删除列
示例
验证
使用Java API更改表
第1步:创建集群对象
第2步:创建会话对象
第3步:执行查询
Cassandra 删除表
使用Cqlsh删除表
语法
示例
验证
使用Java API删除表
第1步:创建集群对象
第2步:创建会话对象
第3步:执行查询
Cassandra 截断表
使用Cqlsh截断表
语法
示例
验证
使用Java API截断表
第1步:创建集群对象
第2步:创建会话对象
第3步:执行查询
Cassandra 创建索引
使用Cqlsh创建索引
使用Java API创建索引
第1步:创建集群对象
第2步:创建会话对象
第3步:执行查询
Cassandra 删除索引
使用Cqlsh删除索引
使用Java API删除索引
第1步:创建集群对象
第2步:创建会话对象
第3步:执行查询
Cassandra 批处理
使用Cqlsh执行批处理语句
示例
验证
使用Java API的批处理语句
第1步:创建集群对象
第2步:创建会话对象
第3步:执行查询
Cassandra CURD操作
Cassandra 创建数据
使用Cqlsh创建数据
示例
验证
使用Java API创建数据
第1步:创建集群对象
第2步:创建会话对象
第3步:执行查询
Cassandra 更新数据
使用Cqlsh更新数据
示例
验证
使用Java API更新数据
第1步:创建集群对象
第2步:创建会话对象
第3步:执行查询
Cassandra 读取数据
使用选择子句读取数据
示例
读取必需的列
Where子句
使用Java API读取数据
第1步:创建集群对象
第2步:创建会话对象
第3步:执行查询
第4步:获取ResultSet对象
Cassandra 删除数据
使用Cqlsh删除数据
删除某个数据
示例
验证
删除整行
验证
使用Java API删除数据
第1步:创建集群对象
第2步:创建会话对象
第3步:执行查询
Cassandra CQL数据类型
Cassandra CQL数据类型
内置数据类型
集合类型
用户定义的数据类型
Cassandra CQL集合
List
使用List创建表
将数据插入列表
更新列表
验证
Set
使用Set创建表
将数据插入集合
更新集合
验证
Map
使用Map创建表
将数据插入到地图中
更新集合
验证
Cassandra CQL用户定义的数据类型
创建用户定义的数据类型
示例
验证
更改用户定义的数据类型
将字段添加到类型
验证
在类型中重命名字段
验证
删除用户定义的数据类型
示例
Cassandra 相关资源
Cassandra 相关链接
Cassandra 相关书籍
友情链接
简介
Apache Cassandra是一个高度可扩展的高性能分布式数据库,用于处理大量商用服务器上的大量数据,提供高可用性,无单点故障。这是一种NoSQL类型的数据库。
Apache Cassandra的一些值得注意的地方
- 它是可扩展,容错和一致的。
- 它是一个面向列的数据库。
- 它的分布设计基于Amazon的Dynamo及其在Google的Bigtable上的数据模型。
- 创建在Facebook,它与关系数据库管理系统有很大的不同。
- Cassandra实现了一个没有单点故障的Dynamo风格的复制模型,但增加了一个更强大的“列族”数据模型。
- Cassandra被一些最大的公司使用,如Facebook,Twitter,Cisco,Rackspace,ebay,Netflix等。
Cassandra的特点
- 弹性可扩展性 - Cassandra是高度可扩展的; 它允许添加更多的硬件以适应更多的客户和更多的数据根据要求。
- 始终基于架构 - Cassandra没有单点故障,它可以连续用于不能承担故障的关键业务应用程序。
- 快速线性性能 - Cassandra是线性可扩展性的,即它为你增加集群中的节点数量增加你的吞吐量。因此,保持一个快速的响应时间。
- 灵活的数据存储 - Cassandra适应所有可能的数据格式,包括:结构化,半结构化和非结构化。它可以根据您的需要动态地适应变化的数据结构。
- 便捷的数据分发 - Cassandra通过在多个数据中心之间复制数据,可以灵活地在需要时分发数据。
- 事务支持 - Cassandra支持属性,如原子性,一致性,隔离和持久性(ACID)。
- 快速写入 - Cassandra被设计为在廉价的商品硬件上运行。 它执行快速写入,并可以存储数百TB的数据,而不牺牲读取效率。
Cassandra的历史
- Cassandra在Facebook上开发了收件箱搜索。
- 它是由Facebook在2008年7月开放了源代码。
- Cassandra于2009年3月被纳入Apache孵化器。
- 它自2010年2月以来成为一个Apache顶级项目。
Cassandra 架构
Cassandra的设计目的是处理跨多个节点的大数据工作负载,而没有任何单点故障。Cassandra在其节点之间具有对等分布式系统,并且数据分布在集群中的所有节点之间。
- 集群中的所有节点都扮演相同的角色。 每个节点是独立的,并且同时互连到其他节点。
- 集群中的每个节点都可以接受读取和写入请求,无论数据实际位于集群中的何处。
- 当节点关闭时,可以从网络中的其他节点提供读/写请求。
Cassandra中的数据复制
在Cassandra中,集群中的一个或多个节点充当给定数据片段的副本。如果检测到一些节点以过期值响应,Cassandra将向客户端返回最近的值。返回最新的值后,Cassandra在后台执行读修复以更新失效值。
下图显示了Cassandra如何在集群中的节点之间使用数据复制,以确保没有单点故障的示意图。
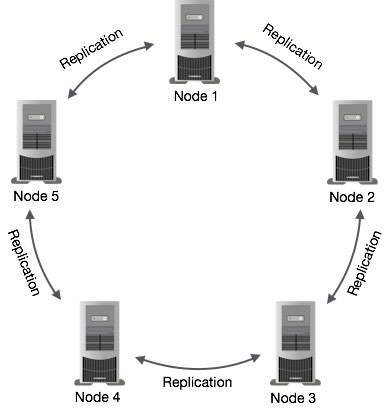
注 - Cassandra在后台使用Gossip协议,允许节点相互通信并检测集群中的任何故障节点。
Cassandra的组件
Cassandra的关键组件如下:
- 节点 - 它是存储数据的地方。
- 数据中心 - 它是相关节点的集合。
- 集群 - 集群是包含一个或多个数据中心的组件。
- 提交日志 - 提交日志是Cassandra中的崩溃恢复机制。每个写操作都写入提交日志。
- Mem-表 - mem-表是存储器驻留的数据结构。提交日志后,数据将被写入mem表。有时,对于单列族,将有多个mem表。
- SSTable - 它是一个磁盘文件,当其内容达到阈值时,数据从mem表中刷新。
- 布隆过滤器 - 这些只是快速,非确定性的算法,用于测试元素是否是集合的成员。它是一种特殊的缓存。 每次查询后访问Bloom过滤器。
Cassandra 查询语言
用户可以使用Cassandra查询语言(CQL)通过其节点访问Cassandra。CQL将数据库(Keyspace)视为表的容器。 程序员使用cqlsh:提示以使用CQL或单独的应用程序语言驱动程序。
客户端针对其读写操作访问任何节点。该节点(协调器)在客户端和保存数据的节点之间播放代理。
写操作
节点的每个写入活动都由写在节点中的提交日志捕获。稍后数据将被捕获并存储在存储器表中。每当内存表满时,数据将写入SStable数据文件。所有写入都会在整个集群中自动分区和复制。Cassandra会定期整合SSTables,丢弃不必要的数据。
简而言之,就是先写到内存里,内存满了,就写到文件里
读操作
在读操作,Cassandra 从MEM-表得到的值,并检查过滤器绽放找到保存所需数据的相应的SSTable。
简而言之,先从内存获取数据,然后再去文件中查看是不是最新的数据
Cassandra 数据模型
Cassandra的数据模型与我们通常在RDBMS中看到的数据模型有很大的不同。本章介绍了Cassandra如何存储数据的概述。
集群(Cluster)
Cassandra数据库分布在几个一起操作的机器上。最外层容器被称为群集。对于故障处理,每个节点包含一个副本,如果发生故障,副本将负责。Cassandra按照环形格式将节点排列在集群中,并为它们分配数据。
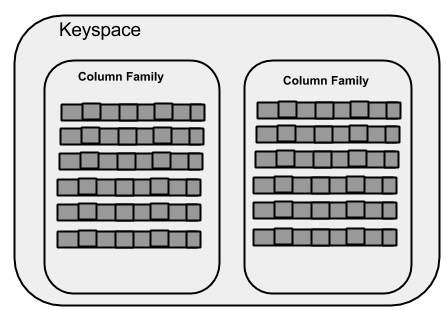
键空间 (Keyspace)
键空间是Cassandra中数据的最外层容器。Cassandra中的一个键空间的基本属性是 -
- 复制因子 - 它是集群中将接收相同数据副本的计算机数。
- 副本放置策略 - 它只是把副本放在戒指中的策略。我们有简单策略(机架感知策略),旧网络拓扑策略(机架感知策略)和网络拓扑策略(数据中心共享策略)等策略。
- 列族 - 键空间是一个或多个列族的列表的容器。列族又是一个行集合的容器。每行包含有序列。列族表示数据的结构。每个键空间至少有一个,通常是许多列族。
创建键空间的语法如下 -
CREATE KEYSPACE Keyspace nameWITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};
下图显示了键空间的示意图。
列族
列族是有序收集行的容器。每一行又是一个有序的列集合。下表列出了区分列系列和关系数据库表的要点。
| 关系表 | Cassandra列族 |
|---|---|
| 关系模型中的模式是固定的。 一旦为表定义了某些列,在插入数据时,在每一行中,所有列必须至少填充一个空值。 | 在Cassandra中,虽然定义了列族,但列不是。 您可以随时向任何列族自由添加任何列。 |
| 关系表只定义列,用户用值填充表。 | 在Cassandra中,表包含列,或者可以定义为超级列族。 |
Cassandra列族具有以下属性 -
- keys_cached - 它表示每个SSTable保持缓存的位置数。
- rows_cached - 它表示其整个内容将在内存中缓存的行数。
- preload_row_cache -它指定是否要预先填充行缓存。
注 - 与不是固定列族的模式的关系表不同,Cassandra不强制单个行拥有所有列。
下图显示了Cassandra列族的示例。
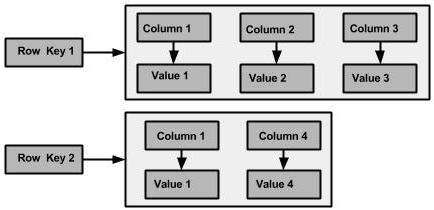
列
列是Cassandra的基本数据结构,具有三个值,即键或列名称,值和时间戳。下面给出了列的结构。

超级列
超级列是一个特殊列,因此,它也是一个键值对。但是超级列存储了子列的地图。
通常列族被存储在磁盘上的单个文件中。因此,为了优化性能,重要的是保持您可能在同一列族中一起查询的列,并且超级列在此可以有所帮助。下面是超级列的结构。

Cassandra 和 RDBMS 的数据模型
下表列出了区分Cassandra的数据模型和RDBMS的数据模型的要点。
| RDBMS | Cassandra |
|---|---|
| RDBMS处理结构化数据。 | Cassandra处理非结构化数据。 |
| 它具有固定的模式。 | Cassandra具有灵活的架构。 |
| 在RDBMS中,表是一个数组的数组。 (ROW x COLUMN) | 在Cassandra中,表是“嵌套的键值对”的列表。(ROW x COLUMN键x COLUMN值) |
| 数据库是包含与应用程序对应的数据的最外层容器。 | Keyspace是包含与应用程序对应的数据的最外层容器。 |
| 表是数据库的实体。 | 表或列族是键空间的实体。 |
| Row是RDBMS中的单个记录。 | Row是Cassandra中的一个复制单元。 |
| 列表示关系的属性。 | Column是Cassandra中的存储单元。 |
| RDBMS支持外键的概念,连接。 | 关系是使用集合表示。 |
总结
关系型数据库就是行*列,非关系型数据库就是行*列的key*列的value
用json举个例子:
[{"key1":"value1", "key2":{"key21":"value21", "key22":"value22"}},{"key1":"value111", "key4":"value444"}]
不同的行能够有不同的列,列里面还能有列。然后整个数据库是分布式的,所有节点都维护同一份记录。数据先保存在内存中,然后内存满了再写入文件。读取先读内存,内存没有命中再读文件。
大概就是这么一回事了。
Cassandra 安装
安装软件
首先访问https://cassandra.apache.org/download/,在这个网站里,你能找到自己想要的安装方式,比方说我想在CentOS上安装,那么根据Installation from RPM packages这一章,我知道首先创建一个/etc/yum.repos.d/cassandra.repo文件,然后在这个文件里面写入
name=Apache Cassandrabaseurl=https://www.apache.org/dist/cassandra/redhat/311x/gpgcheck=1repo_gpgcheck=1gpgkey=https://www.apache.org/dist/cassandra/KEYS
之后运行yum install cassandra安装cassandra,运行service cassandra start开启cassandra,运行chkconfig cassandra on使cassandra能够开机启动。
注意,我在安装的时候,会出现很多Importing GPG key,不用管,一直按y就好了

开发环境
下面给出了使用maven构建Cassandra项目的pom.xml。
<project xmlns = "http://maven.apache.org/POM/4.0.0"xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><build><sourceDirectory>src</sourceDirectory><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>1.7</source><target>1.7</target></configuration></plugin></plugins></build><dependencies><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.5</version></dependency><dependency><groupId>com.datastax.cassandra</groupId><artifactId>cassandra-driver-core</artifactId><version>2.0.2</version></dependency><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>16.0.1</version></dependency><dependency><groupId>com.codahale.metrics</groupId><artifactId>metrics-core</artifactId><version>3.0.2</version></dependency><dependency><groupId>io.netty</groupId><artifactId>netty</artifactId><version>3.9.0.Final</version></dependency></dependencies></project>
Cassandra参考API
本章涵盖Cassandra中的所有重要类。
集群(Cluster)
这个类是驱动程序的主要入口点。它属于com.datastax.driver.core包。
方法
| 序号 | 方法和描述 |
|---|---|
| 1 | Session connect() 它在当前集群上创建一个新会话并对其进行初始化。 |
| 2 | void close() 它用于关闭集群实例。 |
| 3 | static Cluster.Builder builder() 它用于创建一个新的Cluster.Builder实例。 |
Cluster.Builder
此类用于实例化Cluster.Builder类。
方法
| 序号 | 方法和描述 |
|---|---|
| 1 | Cluster.Builder addContactPoint(String address) 此方法向集群添加联系人。 |
| 2 | Cluster build() 此方法使用给定的接触点构建集群。 |
会话
此接口保存与Cassandra群集的连接。使用此接口,可以执行CQL查询。它属于com.datastax.driver.core包。
方法
| 序号 | 方法和描述 |
|---|---|
| 1 | void close() 此方法用于关闭当前会话实例。 |
| 2 | ResultSet execute(Statement statement) 此方法用于执行查询。它需要一个语句对象。 |
| 3 | ResultSet execute(String query) 此方法用于执行查询。它需要一个String对象形式的查询。 |
| 4 | PreparedStatement prepare(RegularStatement statement) 该方法准备提供的查询。查询将以Statement的形式提供。 |
| 5 | PreparedStatement prepare(String query) 该方法准备提供的查询。查询将以String的形式提供。 |
Cassandra Cqlsh
本章介绍Cassandra查询语言shell,并解释如何使用其命令。
默认情况下,Cassandra提供一个提示Cassandra查询语言shell(cqlsh),允许用户与它通信。使用此shell,您可以执行Cassandra查询语言(CQL)。
使用cqlsh,你可以
- 定义模式,
- 插入数据,
- 执行查询。
启动cqlsh
使用命令cqlsh启动cqlsh,如下所示。它提供Cassandra cqlsh提示作为输出。
[hadoop@linux bin]$ cqlshConnected to Test Cluster at 127.0.0.1:9042.[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]Use HELP for help.cqlsh>
Cqlsh - 如上所述,此命令用于启动cqlsh提示符。此外,它还支持更多的选项。下表说明了cqlsh的所有选项及其用法。
| 选项 | 用法 |
|---|---|
| cqlsh --help | 显示有关cqlsh命令的选项的帮助主题。 |
| cqlsh --version | 提供您正在使用的cqlsh的版本。 |
| cqlsh --color | 指示shell使用彩色输出。 |
| cqlsh --debug | 显示更多的调试信息。 |
| cqlsh --execute cql_statement | 指示shell接受并执行CQL命令。 |
| cqlsh --file= "file name" | 如果使用此选项,Cassandra将在给定文件中执行命令并退出。 |
| cqlsh --no-color | 指示Cassandra不使用彩色输出。 |
| cqlsh -u "username" | 使用此选项,您可以验证用户。默认用户名为:cassandra。 |
| cqlsh -p "password" | 使用此选项,您可以使用密码验证用户。默认密码为:cassandra。 |
Cqlsh命令
Cqlsh有几个命令,允许用户与它进行交互。命令如下所示。
记录的Shell命令
下面给出了Cqlsh记录的shell命令。这些是用于执行任务的命令,如显示帮助主题,退出cqlsh,描述等。
- HELP -显示所有cqlsh命令的帮助主题。
- CAPTURE -捕获命令的输出并将其添加到文件。
- CONSISTENCY -显示当前一致性级别,或设置新的一致性级别。
- COPY -将数据复制到Cassandra并从Cassandra复制数据。
- DESCRIBE -描述Cassandra及其对象的当前集群。
- EXPAND -纵向扩展查询的输出。
- EXIT -使用此命令,可以终止cqlsh。
- PAGING -启用或禁用查询分页。
- SHOW -显示当前cqlsh会话的详细信息,如Cassandra版本,主机或数据类型假设。
- SOURCE -执行包含CQL语句的文件。
- TRACING -启用或禁用请求跟踪。
CQL数据定义命令
- CREATE KEYSPACE -在Cassandra中创建KeySpace。
- USE -连接到已创建的KeySpace。
- ALTER KEYSPACE -更改KeySpace的属性。
- DROP KEYSPACE -删除KeySpace。
- CREATE TABLE -在KeySpace中创建表。
- ALTER TABLE -修改表的列属性。
- DROP TABLE -删除表。
- TRUNCATE -从表中删除所有数据。
- CREATE INDEX -在表的单个列上定义新索引。
- DROP INDEX -删除命名索引。
这里我要说明一下,KEYSPACE其实可以类比关系型数据库中的Database,TABLE其实可以类比关系型数据库中的Table,这样就能理解KEYSPACE和TABLE的区别了,详情请见:http://javayoyo.iteye.com/blog/860731
CQL数据操作指令
- INSERT -在表中添加行的列。
- UPDATE -更新行的列。
- DELETE -从表中删除数据。
- BATCH -一次执行多个DML语句。
CQL字句
- SELECT -此子句从表中读取数据
- WHERE -where子句与select一起使用以读取特定数据。
- ORDERBY -orderby子句与select一起使用,以特定顺序读取特定数据。
Cassandra Shell命令
除了CQL命令,Cassandra还提供了记录的shell命令。下面给出了Cassandra记录的shell命令。
Help
HELP命令显示所有cqlsh命令的摘要和简要描述。下面给出了help命令的用法。
cqlsh> helpDocumented shell commands:===========================CAPTURE COPY DESCRIBE EXPAND PAGING SOURCECONSISTENCY DESC EXIT HELP SHOW TRACING.CQL help topics:================ALTER CREATE_TABLE_OPTIONS SELECTALTER_ADD CREATE_TABLE_TYPES SELECT_COLUMNFAMILYALTER_ALTER CREATE_USER SELECT_EXPRALTER_DROP DELETE SELECT_LIMITALTER_RENAME DELETE_COLUMNS SELECT_TABLE
Capture
此命令捕获命令的输出并将其添加到文件。例如,看看下面的代码,它将输出捕获到名为Outputfile的文件。
cqlsh> CAPTURE '/home/hadoop/CassandraProgs/Outputfile'
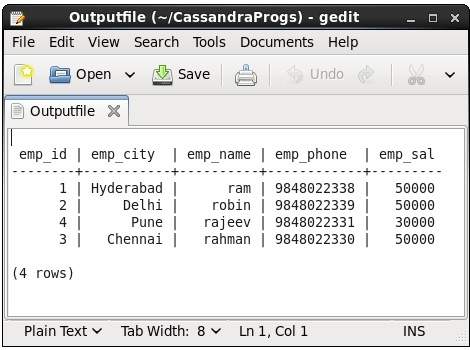
当我们在终端中键入任何命令时,输出将被给定的文件捕获。下面给出的是使用的命令和输出文件的快照。
cqlsh:tutorialspoint> select * from emp;
您可以使用以下命令关闭捕获。
cqlsh:tutorialspoint> capture off;
Consistency
此命令显示当前的一致性级别,或设置新的一致性级别。
cqlsh:tutorialspoint> CONSISTENCYCurrent consistency level is 1.
Copy
此命令将数据从Cassandra复制到文件并从中复制。下面给出一个将名为emp的表复制到文件myfile的示例。
cqlsh:tutorialspoint> COPY emp (emp_id, emp_city, emp_name, emp_phone,emp_sal) TO 'myfile';4 rows exported in 0.034 seconds.
如果您打开并验证给定的文件,您可以找到复制的数据,如下所示。
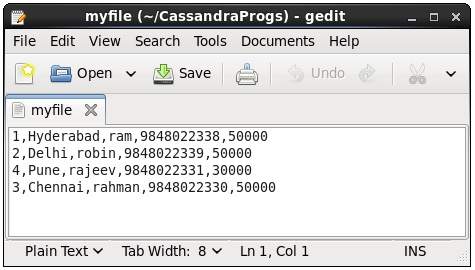
Describe
此命令描述Cassandra及其对象的当前集群。此命令的变体说明如下。
Describe cluster -此命令提供有关集群的信息。
cqlsh:tutorialspoint> describe cluster;Cluster: Test ClusterPartitioner: Murmur3PartitionerRange ownership:-658380912249644557 [127.0.0.1]-2833890865268921414 [127.0.0.1]-6792159006375935836 [127.0.0.1]
Describe Keyspaces -此命令列出集群中的所有键空间。下面给出了这个命令的用法。
cqlsh:tutorialspoint> describe keyspaces;system_traces system tp tutorialspoint
Describe tables -此命令列出了键空间中的所有表。下面给出了这个命令的用法。
cqlsh:tutorialspoint> describe tables;emp
Describe tables -此命令提供表的描述。下面给出了这个命令的用法。
cqlsh:tutorialspoint> describe table emp;CREATE TABLE tutorialspoint.emp (emp_id int PRIMARY KEY,emp_city text,emp_name text,emp_phone varint,emp_sal varint) WITH bloom_filter_fp_chance = 0.01AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'AND comment = ''AND compaction = {'min_threshold': '4', 'class':'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy','max_threshold': '32'}AND compression = {'sstable_compression':'org.apache.cassandra.io.compress.LZ4Compressor'}AND dclocal_read_repair_chance = 0.1AND default_time_to_live = 0AND gc_grace_seconds = 864000AND max_index_interval = 2048AND memtable_flush_period_in_ms = 0AND min_index_interval = 128AND read_repair_chance = 0.0AND speculative_retry = '99.0PERCENTILE';CREATE INDEX emp_emp_sal_idx ON tutorialspoint.emp (emp_sal);
Describe tables
此命令用于描述用户定义的数据类型。下面给出了这个命令的用法。
cqlsh:tutorialspoint> describe type card_details;CREATE TYPE tutorialspoint.card_details (num int,pin int,name text,cvv int,phone set<int>,mail text);
Describe Types
此命令列出所有用户定义的数据类型。下面给出了这个命令的用法。假设有两种用户定义的数据类型:card和card_details。
cqlsh:tutorialspoint> DESCRIBE TYPES;card_details card
Expand
此命令用于扩展输出。在使用此命令之前,您必须打开expand命令。下面给出了这个命令的用法。
cqlsh:tutorialspoint> expand on;cqlsh:tutorialspoint> select * from emp;@ Row 1-----------+------------emp_id | 1emp_city | Hyderabademp_name | ramemp_phone | 9848022338emp_sal | 50000@ Row 2-----------+------------emp_id | 2emp_city | Delhiemp_name | robinemp_phone | 9848022339emp_sal | 50000@ Row 3-----------+------------emp_id | 4emp_city | Puneemp_name | rajeevemp_phone | 9848022331emp_sal | 30000@ Row 4-----------+------------emp_id | 3emp_city | Chennaiemp_name | rahmanemp_phone | 9848022330emp_sal | 50000(4 rows)
注意:您可以使用以下命令关闭展开选项。
cqlsh:tutorialspoint> expand off;Disabled Expanded output.
Exit
此命令用于终止cql shell。
Show
此命令显示当前cqlsh会话的详细信息,如Cassandra版本,主机或数据类型假设。下面给出了这个命令的用法。
cqlsh:tutorialspoint> show host;Connected to Test Cluster at 127.0.0.1:9042.cqlsh:tutorialspoint> show version;[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]
Source
使用此命令,可以在文件中执行命令。假设我们的输入文件如下:
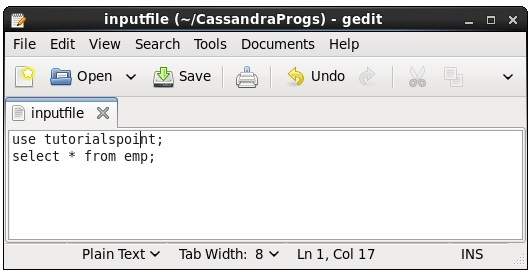
然后可以执行包含命令的文件,如下所示。
cqlsh:tutorialspoint> source '/home/hadoop/CassandraProgs/inputfile';emp_id | emp_city | emp_name | emp_phone | emp_sal--------+-----------+----------+------------+---------1 | Hyderabad | ram | 9848022338 | 500002 | Delhi | robin | 9848022339 | 500003 | Pune | rajeev | 9848022331 | 300004 | Chennai | rahman | 9848022330 | 50000(4 rows)
Cassandra Keyspace操作
创建Keyspace
使用Cqlsh创建一个Keyspace
Cassandra中的键空间是一个定义节点上数据复制的命名空间。集群每个节点包含一个键空间。下面给出了使用语句CREATE KEYSPACE创建键空间的语法。
语句
CREATE KEYSPACE <identifier> WITH <properties>
即
CREATE KEYSPACE “KeySpace Name”WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};CREATE KEYSPACE “KeySpace Name”WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’}AND durable_writes = ‘Boolean value’;
CREATE KEYSPACE语句有两个属性:replication和durable_writes。
replication
复制选项用于指定副本位置策略和所需副本的数量。下表列出了所有副本位置策略。
| 策略名称 | 描述 |
|---|---|
| 简单的策略 | 为集群指定简单的复制因子。 |
| 网络拓扑策略 | 使用此选项,可以单独为每个数据中心设置复制因子。 |
| 旧网络拓扑策略 | 使用此选项,可以单独为每个数据中心设置复制因子。 |
使用此选项,您可以指示Cassandra是否对当前KeySpace的更新使用commitlog。此选项不是强制性的,默认情况下,它设置为true。
示例
下面给出了创建KeySpace的示例。
- 这里我们创建一个名为TutorialsPoint 的KeySpace。
- 我们使用第一个副本放置策略,即简单策略。
- 我们选择复制因子为3个副本。
cqlsh.> CREATE KEYSPACE tutorialspointWITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
验证
您可以使用命令Describe验证是否创建表。如果对键空间使用此命令,它将显示如下所示创建的所有键空间。
cqlsh> DESCRIBE keyspaces;tutorialspoint system system_traces
在这里您可以观察新创建的KeySpace tutorialspoint。
Durable_writes
默认情况下,表的durable_writes属性设置为true,但可以将其设置为false。您不能将此属性设置为simplex策略。
示例
下面给出了示例持久写入属性的使用示例。
cqlsh> CREATE KEYSPACE test... WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 }... AND DURABLE_WRITES = false;
验证
您可以通过查询系统键空间来验证test KeySpace的durable_writes属性是否设置为false。此查询提供了所有KeySpaces及其属性。
cqlsh> SELECT * FROM system.schema_keyspaces;keyspace_name | durable_writes | strategy_class | strategy_options----------------+----------------+------------------------------------------------------+----------------------------test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1" : "3"}tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "4"}system | True | org.apache.cassandra.locator.LocalStrategy | { }system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "2"}(4 rows)
在这里可以观察测试KeySpace的durable_writes属性设置为false。
use keyspace
您可以使用关键字USE使用创建的KeySpace。其语法如下:
Syntax:USE <identifier>
示例
在下面的示例中,我们使用KeySpace tutorialspoint。
cqlsh> USE tutorialspoint;cqlsh:tutorialspoint>
使用Java API创建一个Keyspace
您可以使用Session类的execute()方法创建一个Keyspace。按照以下步骤使用Java API创建键空间。
第1步:创建一个集群对象
首先,创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。以下代码显示如何创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以在单行代码中构建一个集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果已经有一个键空间,可以通过将字符串格式的键空间名称传递给这个方法来将其设置为现有键空间,如下所示。
Session session = cluster.connect(“ Your keyspace name ” );
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在这个例子中,我们创建一个名为tp的KeySpace。我们使用第一个副本放置策略,即简单策略,我们选择复制因子为1个副本。
您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示。
String query = "CREATE KEYSPACE tp WITH replication "+ "= {'class':'SimpleStrategy', 'replication_factor':1}; ";session.execute(query);
第4步:使用KeySpace
您可以使用execute()方法使用创建的KeySpace,如下所示。
execute(“ USE tp ” );
下面给出了使用Java API在Cassandra中创建和使用键空间的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Create_KeySpace {public static void main(String args[]){//QueryString query = "CREATE KEYSPACE tp WITH replication "+ "= {'class':'SimpleStrategy', 'replication_factor':1};";//creating Cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect();//Executing the querysession.execute(query);//using the KeySpacesession.execute("USE tp");System.out.println("Keyspace created");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Create_KeySpace.java$java Create_KeySpace
在正常条件下,它将产生以下输出:
Keyspace created
修改Keyspace
使用Cqlsh修改Keyspace
ALTER KEYSPACE可用于更改属性,例如,一个KeySpace的replicas和durable_writes的数量。下面给出了此命令的语法。
语句
ALTER KEYSPACE <identifier> WITH <properties>
即:
ALTER KEYSPACE “KeySpace Name”WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};
ALTER KEYSPACE的属性与CREATE KEYSPACE相同。它有两个属性:replication和durable_writes。
replication
使用此选项,您可以指示Cassandra是否对当前KeySpace的更新使用commitlog。此选项不是强制性的,默认情况下,它设置为true。
示例
下面给出一个修改KeySpace的例子。
- 这里我们改变一个名为TutorialsPoint的KeySpace。
- 我们将复制因子从1更改为3。
cqlsh.> ALTER KEYSPACE tutorialspointWITH replication = {'class':'NetworkTopologyStrategy', 'replication_factor' : 3};
更改 Durable_writes
您还可以修改KeySpace的durable_writes属性。下面给出测试KeySpace的durable_writes属性。
SELECT * FROM system.schema_keyspaces;keyspace_name | durable_writes | strategy_class | strategy_options----------------+----------------+------------------------------------------------------+----------------------------test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}system | True | org.apache.cassandra.locator.LocalStrategy | { }system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}(4 rows)
ALTER KEYSPACE testWITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}AND DURABLE_WRITES = true;
再次,如果您验证KeySpaces的属性,它将产生以下输出。
SELECT * FROM system.schema_keyspaces;keyspace_name | durable_writes | strategy_class | strategy_options----------------+----------------+------------------------------------------------------+----------------------------test | True | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}system | True | org.apache.cassandra.locator.LocalStrategy | { }system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}(4 rows)
使用Java API修改键空间
您可以使用Session类的execute()方法来更改键空间。按照以下步骤使用Java API更改键空间
第1步:创建一个集群对象
首先,创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。以下代码显示如何创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Clusterclass的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果已经有一个键空间,可以通过将字符串格式的键空间名称传递给这个方法来将其设置为现有键空间,如下所示。
Session session = cluster.connect(“ Your keyspace name ” );
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在这个例子中,
- 我们正在改变一个名为tp的键空间。我们正在将复制选项从简单策略更改为网络拓扑策略。
- 我们正在将durable_writes更改为false
您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示。
//QueryString query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}" +" AND DURABLE_WRITES = false;";session.execute(query);
下面给出了使用Java API在Cassandra中创建和使用键空间的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Alter_KeySpace {public static void main(String args[]){//QueryString query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}"+ "AND DURABLE_WRITES = false;";//Creating Cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect();//Executing the querysession.execute(query);System.out.println("Keyspace altered");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Alter_KeySpace.java$java Alter_KeySpace
在正常条件下,它产生以下输出:
Keyspace Altered
删除Keyspace
使用Cqlsh删除键空间
您可以使用命令DROP KEYSPACE删除KeySpace。下面给出了删除KeySpace的语法。
语句
DROP KEYSPACE <identifier>
即:
DROP KEYSPACE “KeySpace name”
示例
以下代码删除了keyspace tutorialspoint.
cqlsh> DROP KEYSPACE tutorialspoint;
验证
使用命令 Describe 验证键空间,并检查是否删除表,如下所示。
cqlsh> DESCRIBE keyspaces;system system_traces
由于我们已经删除了keyspace tutorialspoint,你不会在keyspace列表中找到它。
使用Java API删除键空间
您可以使用Session类的execute()方法创建一个键空间。按照以下步骤使用Java API删除键空间。
第1步:创建群集对象
首先,创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。以下代码显示如何创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果已经有一个键空间,可以通过将字符串格式的键空间名称传递给这个方法来将其设置为现有键空间,如下所示。
Session session = cluster.connect(“ Your keyspace name”);
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在下面的示例中,我们将删除名为tp的键空间。您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示。
String query = "DROP KEYSPACE tp; ";session.execute(query);
下面给出了使用Java API在Cassandra中创建和使用键空间的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Drop_KeySpace {public static void main(String args[]){//QueryString query = "Drop KEYSPACE tp";//creating Cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect();//Executing the querysession.execute(query);System.out.println("Keyspace deleted");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Delete_KeySpace.java$java Delete_KeySpace
在正常条件下,它应该产生以下输出:
Keyspace deleted
Cassandra 表操作
Cassandra 创建表
使用Cqlsh创建表
您可以使用命令CREATE TABLE创建表。下面给出了创建表的语法。
语句
CREATE (TABLE | COLUMNFAMILY) <tablename>('<column-definition>' , '<column-definition>')(WITH <option> AND <option>)
定义列
您可以定义一个列,如下所示。
column name1 data type,column name2 data type,example:age int,name text
主键
主键是用于唯一标识行的列。因此,在创建表时,必须定义主键。主键由表的一个或多个列组成。您可以定义表的主键,如下所示。
CREATE TABLE tablename(column1 name datatype PRIMARYKEY,column2 name data type,column3 name data type.)
或者
CREATE TABLE tablename(column1 name datatype,column2 name data type,column3 name data type,PRIMARY KEY (column1))
示例
下面给出一个使用cqlsh在Cassandra中创建表的示例。我们到了:
- 使用keyspace tutorialspoint
- 创建名为emp的表
它将有详细信息,如员工姓名,id,城市,工资和电话号码。Employee id是主键。
cqlsh> USE tutorialspoint;cqlsh:tutorialspoint>; CREATE TABLE emp(emp_id int PRIMARY KEY,emp_name text,emp_city text,emp_sal varint,emp_phone varint);
验证
select语句将为您提供模式。使用select语句验证表,如下所示。
cqlsh:tutorialspoint> select * from emp;emp_id | emp_city | emp_name | emp_phone | emp_sal--------+----------+----------+-----------+---------(0 rows)
在这里,您可以观察使用给定列创建的表。由于我们已经删除了keyspace的教程节点,你不会在keyspace列表中找到它。
使用Java API创建表
您可以使用Session类的execute()方法创建表。按照以下给出的步骤使用Java API创建表。
第1步:创建群集对象
首先,创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。以下代码显示如何创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果已经有一个键空间,可以通过将字符串格式的键空间名称传递给这个方法来将其设置为现有键空间,如下所示。
Session session = cluster.connect(“ Your keyspace name ” );
这里我们使用名为tp的键空间。因此,创建会话对象如下所示。
Session session = cluster.connect(“ tp” );
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在下面的示例中,我们将创建一个名为emp的表。您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示。
//QueryString query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "+ "emp_name text, "+ "emp_city text, "+ "emp_sal varint, "+ "emp_phone varint );";session.execute(query);
下面给出了使用Java API在Cassandra中创建和使用键空间的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Create_Table {public static void main(String args[]){//QueryString query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "+ "emp_name text, "+ "emp_city text, "+ "emp_sal varint, "+ "emp_phone varint );";//Creating Cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect("tp");//Executing the querysession.execute(query);System.out.println("Table created");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Create_Table.java$java Create_Table
在正常条件下,它应该产生以下输出:
Table created
Cassandra 修改表
使用Cqlsh改变表
您可以使用命令ALTER TABLE更改表。下面给出了修改表的语法。
句法
ALTER (TABLE | COLUMNFAMILY) <tablename> <instruction>
使用ALTER命令,可以执行以下操作:
- 添加列
- 删除列
添加列
使用ALTER命令,可以向表中添加列。在添加列时,必须注意,列名称不会与现有列名称冲突,并且表未使用紧凑存储选项定义。下面给出了向表中添加列的语法。
ALTER TABLE table nameADD new column datatype;
示例
下面给出了向现有表中添加列的示例。这里我们在名为emp的表中添加一个名为emp_email的文本数据类型的列。
cqlsh:tutorialspoint> ALTER TABLE emp... ADD emp_email text;
验证
使用SELECT语句验证列是否已添加。在这里可以观察新添加的列emp_email。
cqlsh:tutorialspoint> select * from emp;emp_id | emp_city | emp_email | emp_name | emp_phone | emp_sal--------+----------+-----------+----------+-----------+---------
删除列
使用ALTER命令,可以从表中删除列。在从表中删除列之前,请检查该表是否未使用紧凑存储选项进行定义。下面给出了使用ALTER命令从表中删除列的语法。
ALTER table nameDROP column name;
示例
下面给出了从表中删除列的示例。这里我们删除名为emp_email的列。
cqlsh:tutorialspoint> ALTER TABLE emp DROP emp_email;
验证
使用select语句验证列是否已删除,如下所示。
cqlsh:tutorialspoint> select * from emp;emp_id | emp_city | emp_name | emp_phone | emp_sal--------+----------+----------+-----------+---------(0 rows)
由于emp_email列已删除,因此您无法再找到它。
使用Java API更改表
您可以使用Session类的execute()方法创建表。按照以下步骤使用Java API更改表。
第1步:创建集群对象
首先,创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。以下代码显示如何创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果您已经有一个键空间,您可以通过将KeySpace名称以字符串格式传递到此方法来将其设置为现有键空间,如下所示。
Session session = cluster.connect(“ Your keyspace name ” );Session session = cluster.connect(“ tp” );
这里我们使用KeySpace命名为tp。因此,创建会话对象如下所示。
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在以下示例中,我们向名为emp的表中添加列。为此,您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示。
//QueryString query1 = "ALTER TABLE emp ADD emp_email text";session.execute(query);
下面给出了向现有表中添加列的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Add_column {public static void main(String args[]){//QueryString query = "ALTER TABLE emp ADD emp_email text";//Creating Cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect("tp");//Executing the querysession.execute(query);System.out.println("Column added");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Add_Column.java$java Add_Column
在正常条件下,它应该产生以下输出:
Column added
删除列
下面给出了从现有表中删除列的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Delete_Column {public static void main(String args[]){//QueryString query = "ALTER TABLE emp DROP emp_email;";//Creating Cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect("tp");//executing the querysession.execute(query);System.out.println("Column deleted");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Delete_Column.java$java Delete_Column
在正常条件下,它应该产生以下输出:
Column deleted
Cassandra 删除表
使用Cqlsh删除表
您可以使用命令Drop Table删除表。其语法如下:
语法
DROP TABLE <tablename>
示例
以下代码从KeySpace删除现有表。
cqlsh:tutorialspoint> DROP TABLE emp;
验证
用Describe命令验证表是否已删除。由于emp表已删除,您不会在列族列表中找到它。
cqlsh:tutorialspoint> DESCRIBE COLUMNFAMILIES;employee
使用Java API删除表
您可以使用Session类的execute()方法删除表。按照以下步骤使用Java API删除表。
第1步:创建集群对象
首先,创建一个Cluster.builder类的实例com.datastax.driver.core包,如下所示:
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。以下代码显示如何创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果您已经有一个键空间,您可以通过将KeySpace名称以字符串格式传递到此方法来将其设置为现有键空间,如下所示。
Session session = cluster.connect(“Your keyspace name”);
这里我们使用名为tp的键空间。因此,创建会话对象如下所示。
Session session = cluster.connect(“tp”);
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在下面的示例中,我们将删除名为emp的表。您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示。
// QueryString query = "DROP TABLE emp1;”;session.execute(query);
下面给出了使用Java API在Cassandra中删除表的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Drop_Table {public static void main(String args[]){//QueryString query = "DROP TABLE emp1;";Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect("tp");//Executing the querysession.execute(query);System.out.println("Table dropped");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Drop_Table.java$java Drop_Table
在正常条件下,它应该产生以下输出:
Table dropped
Cassandra 截断表
使用Cqlsh截断表
您可以使用TRUNCATE命令截断表。截断表时,表的所有行都将永久删除。下面给出了此命令的语法。
语法
TRUNCATE <tablename>
示例
让我们假设有一个名为student的表有以下数据。
| s_id | s_name | s_branch | s_aggregate |
|---|---|---|---|
| 1 | ram | IT | 70 |
| 2 | rahman | EEE | 75 |
| 3 | robbin | Mech | 72 |
当您执行select语句以获取表student时,它将给您以下输出。
cqlsh:tp> select * from student;s_id | s_aggregate | s_branch | s_name------+-------------+----------+--------1 | 70 | IT | ram2 | 75 | EEE | rahman3 | 72 | MECH | robbin(3 rows)
现在使用TRUNCATE命令截断表。
cqlsh:tp> TRUNCATE student;
验证
通过执行select语句验证表是否被截断。下面给出截断后学生表上的select语句的输出。
cqlsh:tp> select * from student;s_id | s_aggregate | s_branch | s_name------+-------------+----------+--------(0 rows)
使用Java API截断表
您可以使用Session类的execute()方法截断表。按照以下步骤截断表。
第1步:创建集群对象
首先,创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。以下代码显示如何创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果您已经有一个键空间,那么您可以通过将KeySpace名称以字符串格式设置为现有键空间,此方法如下所示。
Session session = cluster.connect(“ Your keyspace name ” );Session session = cluster.connect(“ tp” );
这里我们使用名为tp的键空间。因此,创建会话对象如下所示。
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在下面的示例中,我们截断了一个名为emp的表。您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示。
//QueryString query = "TRUNCATE emp;;”;session.execute(query);
下面给出了使用Java API截断Cassandra中的表的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Truncate_Table {public static void main(String args[]){//QueryString query = "Truncate student;";//Creating Cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect("tp");//Executing the querysession.execute(query);System.out.println("Table truncated");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Truncate_Table.java$java Truncate_Table
在正常条件下,它应该产生以下输出:
Table truncated
Cassandra 创建索引
使用Cqlsh创建索引
您可以使用命令CREATE INDEX在Cassandra中创建索引。其语法如下:
CREATE INDEX <identifier> ON <tablename>
下面给出一个创建列的索引的例子。这里,我们在名为emp的表中为列“emp_name”创建索引。
cqlsh:tutorialspoint> CREATE INDEX name ON emp1 (emp_name);
使用Java API创建索引
您可以使用Session类的execute()方法创建表的列的索引。按照下面给出的步骤为表中的列创建索引。
第1步:创建集群对象
首先,创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。以下代码显示如何创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果您已经有一个键空间,那么您可以通过将KeySpace名称以字符串格式设置为现有键空间,此方法如下所示。
Session session = cluster.connect(“ Your keyspace name ” );Session session = cluster.connect(“ tp” );
这里我们使用名为tp的键空间。因此,创建会话对象如下所示。
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在以下示例中,我们在名为emp的表中为名为emp_name的列创建索引。您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示。
//QueryString query = "CREATE INDEX name ON emp1 (emp_name);";session.execute(query);
下面给出了使用Java API在Cassandra中的表中创建列的索引的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Create_Index {public static void main(String args[]){//QueryString query = "CREATE INDEX name ON emp1 (emp_name);";Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect("tp");//Executing the querysession.execute(query);System.out.println("Index created");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Create_Index.java$java Create_Index
在正常条件下,它应该产生以下输出:
Index created
Cassandra 删除索引
使用Cqlsh删除索引
您可以使用命令DROP INDEX删除索引。其语法如下:
DROP INDEX <identifier>
下面给出了删除表中列的索引的示例。这里我们删除表emp中的列名的索引。
cqlsh:tp> drop index name;
使用Java API删除索引
您可以使用Session类的execute()方法删除表的索引。按照以下步骤从表中删除索引。
第1步:创建集群对象
创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。以下代码显示如何创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果您已经有一个键空间,那么您可以通过将KeySpace名称以字符串格式设置为现有键空间,此方法如下所示。
Session session = cluster.connect(“ Your keyspace name ” );
这里我们使用KeySpace命名为tp。因此,创建会话对象如下所示。
Session session = cluster.connect(“ tp” );
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在下面的示例中,我们删除了emp表的索引“name”。您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示。
//QueryString query = "DROP INDEX user_name;";session.execute(query);
下面给出了使用Java API在Cassandra中删除索引的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Drop_Index {public static void main(String args[]){//QueryString query = "DROP INDEX user_name;";//Creating cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();.//Creating Session objectSession session = cluster.connect("tp");//Executing the querysession.execute(query);System.out.println("Index dropped");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Drop_index.java$java Drop_index
在正常条件下,它应该产生以下输出:
Index dropped
Cassandra 批处理
使用Cqlsh执行批处理语句
使用BATCH,您可以同时执行多个修改语句(插入,更新,删除)。其语法如下:
BEGIN BATCH<insert-stmt>/ <update-stmt>/ <delete-stmt>APPLY BATCH
示例
假设Cassandra中有一个名为emp的表,具有以下数据:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ram | Hyderabad | 9848022338 | 50000 |
| 2 | robin | Delhi | 9848022339 | 50000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
在这个例子中,我们将执行以下操作:
- 插入包含以下详细信息的新行(4,rajeev,pune,9848022331,30000)。
- 将行号为3的员工的工资更新为50000。
- 删除行ID为2的员工的城市。
要一次性执行上述操作,请使用以下BATCH命令:
cqlsh:tutorialspoint> BEGIN BATCH... INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);... UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;... DELETE emp_city FROM emp WHERE emp_id = 2;... APPLY BATCH;
验证
更改后,使用SELECT语句验证表。它应该产生以下输出:
cqlsh:tutorialspoint> select * from emp;emp_id | emp_city | emp_name | emp_phone | emp_sal--------+-----------+----------+------------+---------1 | Hyderabad | ram | 9848022338 | 500002 | null | robin | 9848022339 | 500003 | Chennai | rahman | 9848022330 | 500004 | Pune | rajeev | 9848022331 | 30000(4 rows)
这里可以观察具有修改数据的表。
使用Java API的批处理语句
可以使用Session类的execute()方法以编程方式在表中编写批处理语句。按照下面给出的步骤在Java API的帮助下使用批处理语句执行多个语句。
第1步:创建集群对象
创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。使用以下代码创建集群对象:
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果您已经有一个键空间,那么您可以通过将KeySpace名称以字符串格式设置为现有键空间,此方法如下所示。
Session session = cluster.connect(“ Your keyspace name ”);
这里我们使用KeySpace命名为tp。因此,创建会话对象如下所示。
Session session = cluster.connect(“tp”);
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在这个例子中,我们将执行以下操作:
- 插入包含以下详细信息的新行(4,rajeev,pune,9848022331,30000)。
- 将行号为3的员工的工资更新为50000。
- 删除行ID为2的员工所在的城市。
您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示。
String query1 = ” BEGIN BATCH INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;DELETE emp_city FROM emp WHERE emp_id = 2;APPLY BATCH;”;
下面给出的是使用Java API在Cassandra中的表上同时执行多个语句的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Batch {public static void main(String args[]){//queryString query =" BEGIN BATCH INSERT INTO emp (emp_id, emp_city,emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);"+ "UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;"+ "DELETE emp_city FROM emp WHERE emp_id = 2;"+ "APPLY BATCH;";//Creating Cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect("tp");//Executing the querysession.execute(query);System.out.println("Changes done");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下所示。
$javac Batch.java$java Batch
在正常条件下,它应该产生以下输出:
Changes done
Cassandra CURD操作
Cassandra 创建数据
使用Cqlsh创建数据
可以使用命令INSERT将数据插入到表中行的列中。下面给出了在表中创建数据的语法。
INSERT INTO <tablename>(<column1 name>, <column2 name>....)VALUES (<value1>, <value2>....)USING <option>
示例
让我们假设有一个名为emp的表(emp_id,emp_name,emp_city,emp_phone,emp_sal),并且必须将以下数据插入emp表。
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ram | Hyderabad | 9848022338 | 50000 |
| 2 | robin | Hyderabad | 9848022339 | 40000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
使用下面给出的命令用所需的数据填充表。
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,emp_phone, emp_sal) VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,emp_phone, emp_sal) VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,emp_phone, emp_sal) VALUES(3,'rahman', 'Chennai', 9848022330, 45000);
验证
插入数据后,使用SELECT语句验证数据是否已插入。如果使用SELECT语句验证emp表,它将给您以下输出。
cqlsh:tutorialspoint> SELECT * FROM emp;emp_id | emp_city | emp_name | emp_phone | emp_sal--------+-----------+----------+------------+---------1 | Hyderabad | ram | 9848022338 | 500002 | Hyderabad | robin | 9848022339 | 400003 | Chennai | rahman | 9848022330 | 45000(3 rows)
在这里你可以观察表中填充了我们插入的数据。
使用Java API创建数据
您可以使用Session类的execute()方法在表中创建数据。按照以下步骤使用java API在表中创建数据。
第1步:创建集群对象
创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint("127.0.0.1");
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。以下代码显示如何创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果您已经有一个键空间,那么您可以通过将KeySpace名称以字符串格式设置为现有键空间,此方法如下所示。
Session session = cluster.connect(“ Your keyspace name ” );
这里我们使用KeySpace称为tp。因此,创建会话对象如下所示。
Session session = cluster.connect(“ tp” );
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在下面的示例中,我们在emp表中插入数据。您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示。
String query1 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);” ;String query2 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);” ;String query3 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)VALUES(3,'rahman', 'Chennai', 9848022330, 45000);” ;session.execute(query1);session.execute(query2);session.execute(query3);
下面给出了使用Java API将数据插入到Cassandra表中的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Create_Data {public static void main(String args[]){//queriesString query1 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"+ " VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);" ;String query2 = "INSERT INTO emp (emp_id, emp_name, emp_city,emp_phone, emp_sal)"+ " VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);" ;String query3 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"+ " VALUES(3,'rahman', 'Chennai', 9848022330, 45000);" ;//Creating Cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect("tp");//Executing the querysession.execute(query1);session.execute(query2);session.execute(query3);System.out.println("Data created");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Create_Data.java$java Create_Data
在正常条件下,它应该产生以下输出:
Data created
Cassandra 更新数据
使用Cqlsh更新数据
UPDATE是用于更新表中的数据的命令。在更新表中的数据时使用以下关键字:
- Where - 此子句用于选择要更新的行。
- Set - 使用此关键字设置值。
- Must - 包括组成主键的所有列。
在更新行时,如果给定行不可用,则UPDATE创建一个新行。下面给出了UPDATE命令的语法:
UPDATE <tablename>SET <column name> = <new value><column name> = <value>....WHERE <condition>
示例
假设有一个名为emp的表。此表存储某公司员工的详细信息,其具有以下详细信息:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ram | Hyderabad | 9848022338 | 50000 |
| 2 | robin | Hyderabad | 9848022339 | 40000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
现在让我们将robin的emp_city更新到Delhi,将他的工资更新为50000.以下是执行所需更新的查询。
cqlsh:tutorialspoint> UPDATE emp SET emp_city='Delhi',emp_sal=50000WHERE emp_id=2;
验证
使用SELECT语句来验证数据是否已更新。如果使用SELECT语句验证emp表,它将产生以下输出。
cqlsh:tutorialspoint> select * from emp;emp_id | emp_city | emp_name | emp_phone | emp_sal--------+-----------+----------+------------+---------1 | Hyderabad | ram | 9848022338 | 500002 | Delhi | robin | 9848022339 | 500003 | Chennai | rahman | 9848022330 | 45000(3 rows)
这里可以观察到表数据已更新。
使用Java API更新数据
您可以使用Session类的execute()方法更新表中的数据。按照以下步骤使用Java API更新表中的数据。
第1步:创建集群对象
创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint("127.0.0.1");
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。使用以下代码创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果您已经有一个键空间,那么您可以通过将KeySpace名称以字符串格式设置为现有键空间,此方法如下所示。
Session session = cluster.connect(“ Your keyspace name”);
这里我们使用KeySpace命名为tp。因此,创建会话对象如下所示。
Session session = cluster.connect(“tp”);
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在下面的示例中,我们更新emp表。您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示:
String query = “ UPDATE emp SET emp_city='Delhi',emp_sal=50000WHERE emp_id = 2;” ;
下面给出了使用Java API更新表中数据的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Update_Data {public static void main(String args[]){//queryString query = " UPDATE emp SET emp_city='Delhi',emp_sal=50000"//Creating Cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect("tp");//Executing the querysession.execute(query);System.out.println("Data updated");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Update_Data.java$java Update_Data
在正常条件下,它应该产生以下输出:
Data updated
Cassandra 读取数据
使用选择子句读取数据
SELECT子句用于从Cassandra中的表读取数据。使用此子句,您可以读取整个表,单个列或特定单元格。下面给出了SELECT子句的语法。
SELECT FROM <tablename>
示例
假设在名为emp的键空间中有一个具有以下详细信息的表:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ram | Hyderabad | 9848022338 | 50000 |
| 2 | robin | null | 9848022339 | 50000 |
| 3 | rahman | Chennai | 9848022330 | 50000 |
| 4 | rajeev | Pune | 9848022331 | 30000 |
以下示例显示如何使用SELECT子句读取整个表。这里我们读一个表emp。
cqlsh:tutorialspoint> select * from emp;emp_id | emp_city | emp_name | emp_phone | emp_sal--------+-----------+----------+------------+---------1 | Hyderabad | ram | 9848022338 | 500002 | null | robin | 9848022339 | 500003 | Chennai | rahman | 9848022330 | 500004 | Pune | rajeev | 9848022331 | 30000(4 rows)
读取必需的列
以下示例显示如何读取表中的特定列。
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;emp_name | emp_sal----------+---------ram | 50000robin | 50000rajeev | 30000rahman | 50000(4 rows)
Where子句
使用WHERE子句,可以对必需的列设置约束。其语法如下:
SELECT FROM <table name> WHERE <condition>;
注意:WHERE子句只能用于作为主键的一部分或在其上具有辅助索引的列。
在以下示例中,我们正在读取薪水为50000的员工的详细信息。首先,将辅助索引设置为列emp_sal。
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;emp_id | emp_city | emp_name | emp_phone | emp_sal--------+-----------+----------+------------+---------1 | Hyderabad | ram | 9848022338 | 500002 | null | robin | 9848022339 | 500003 | Chennai | rahman | 9848022330 | 50000
使用Java API读取数据
您可以使用Session类的execute()方法从表中读取数据。按照下面给出的步骤在Java API的帮助下使用批处理语句执行多个语句。
第1步:创建集群对象
创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。使用以下代码创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect( );
此方法创建一个新会话并初始化它。如果您已经有一个键空间,那么您可以通过将KeySpace名称以字符串格式设置为现有键空间,此方法如下所示。
Session session = cluster.connect(“Your keyspace name”);
这里我们使用KeySpace称为tp。因此,创建会话对象如下所示。
Session session = cluster.connect(“tp”);
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在这个例子中,我们从emp表中检索数据。将查询存储在字符串中,并将其传递给会话类的execute()方法,如下所示。
String query = ”SELECT 8 FROM emp”;session.execute(query);
使用Session类的execute()方法执行查询。
第4步:获取ResultSet对象
select查询将以ResultSet对象的形式返回结果,因此将结果存储在RESULTSET类的对象中,如下所示。
ResultSet result = session.execute( );
下面给出的是从表中读取数据的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.ResultSet;import com.datastax.driver.core.Session;public class Read_Data {public static void main(String args[])throws Exception{//queriesString query = "SELECT * FROM emp";//Creating Cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect("tutorialspoint");//Getting the ResultSetResultSet result = session.execute(query);System.out.println(result.all());}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Read_Data.java$java Read_Data
在正常条件下,它应该产生以下输出:
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin,9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3,Chennai, rahman, 9848022330, 50000]]
Cassandra 删除数据
使用Cqlsh删除数据
您可以使用命令DELETE从表中删除数据。其语法如下:
DELETE FROM <identifier> WHERE <condition>;
删除某个数据
示例
让我们假设Cassandra中有一个名为emp的具有以下数据的表:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ram | Hyderabad | 9848022338 | 50000 |
| 2 | robin | Hyderabad | 9848022339 | 40000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
以下语句删除最后一行的emp_sal列:
cqlsh:tutorialspoint> DELETE emp_sal FROM emp WHERE emp_id=3;
验证
使用SELECT语句验证数据是否已删除。如果使用SELECT验证emp表,它将产生以下输出:
cqlsh:tutorialspoint> select * from emp;emp_id | emp_city | emp_name | emp_phone | emp_sal--------+-----------+----------+------------+---------1 | Hyderabad | ram | 9848022338 | 500002 | Delhi | robin | 9848022339 | 500003 | Chennai | rahman | 9848022330 | null(3 rows)
由于我们删除了Rahman的薪资,你将看到一个空值代替薪资。
删除整行
以下命令从表中删除整个行。
cqlsh:tutorialspoint> DELETE FROM emp WHERE emp_id=3;
验证
使用SELECT语句验证数据是否已删除。如果使用SELECT验证emp表,它将产生以下输出:
cqlsh:tutorialspoint> select * from emp;emp_id | emp_city | emp_name | emp_phone | emp_sal--------+-----------+----------+------------+---------1 | Hyderabad | ram | 9848022338 | 500002 | Delhi | robin | 9848022339 | 50000(2 rows)
由于我们删除了最后一行,因此表中只剩下两行。
使用Java API删除数据
您可以使用Session类的execute()方法删除表中的数据。按照以下步骤使用java API从表中删除数据。
第1步:创建集群对象
创建一个名为com.datastax.driver.core的Cluster.builder类的实例,如下所示。
//Creating Cluster.Builder objectCluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder对象的addContactPoint()方法添加联系点(节点的IP地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder objectCluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。使用以下代码创建集群对象。
//Building a clusterCluster cluster = builder.build();
您可以使用单行代码构建集群对象,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
第2步:创建会话对象
使用Cluster类的connect()方法创建一个Session对象的实例,如下所示。
Session session = cluster.connect();
使用新的构建器对象,创建一个集群对象。为此,在Cluster.Builder类中有一个名为build()的方法。使用以下代码创建集群对象。
Session session = cluster.connect(“ Your keyspace name ”);
这里我们使用KeySpace称为tp。因此,创建会话对象如下所示。
Session session = cluster.connect(“tp”);
第3步:执行查询
您可以使用Session类的execute()方法执行CQL查询。将查询以字符串格式或Statement类对象传递给execute()方法。无论您以字符串格式传递给此方法将在cqlsh上执行。
在下面的示例中,我们从名为emp的表中删除数据。您必须将查询存储在字符串变量中,并将其传递给execute()方法,如下所示。
String query1 = ”DELETE FROM emp WHERE emp_id=3; ”;session.execute(query);
下面给出了使用Java API从Cassandra中的表中删除数据的完整程序。
import com.datastax.driver.core.Cluster;import com.datastax.driver.core.Session;public class Delete_Data {public static void main(String args[]){//queryString query = "DELETE FROM emp WHERE emp_id=3;";//Creating Cluster objectCluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();//Creating Session objectSession session = cluster.connect("tp");//Executing the querysession.execute(query);System.out.println("Data deleted");}}
使用类名称和.java保存上述程序,浏览到保存位置。编译并执行程序如下图所示。
$javac Delete_Data.java$java Delete_Data
在正常条件下,它应该产生以下输出:
Data deleted
Cassandra CQL数据类型
Cassandra CQL数据类型
内置数据类型
CQL提供了一组丰富的内置数据类型,包括集合类型。除了这些数据类型,用户还可以创建自己的自定义数据类型。下表提供了CQL中可用的内置数据类型的列表。
| 数据类型 | 常量 | 描述 |
|---|---|---|
| ascii | strings | 表示ASCII字符串 |
| bigint | bigint | 表示64位有符号长 |
| blob | blobs | 表示任意字节 |
| Boolean | booleans | 表示true或false |
| counter | integers | 表示计数器列 |
| decimal | integers, floats | 表示变量精度十进制 |
| double | integers | 表示64位IEEE-754浮点 |
| float | integers, floats | 表示32位IEEE-754浮点 |
| inet | strings | 表示一个IP地址,IPv4或IPv6 |
| int | integers | 表示32位有符号整数 |
| text | strings | 表示UTF8编码的字符串 |
| timestamp | integers, strings | 表示时间戳 |
| timeuuid | uuids | 表示类型1 UUID |
| uuid | uuids | 表示类型1或类型4 UUID |
| varchar | strings | 表示UTF8编码的字符串 |
| varint | integers | 表示任意精度整数 |
这里我说明一下,类型1 UUID是基于时间戳,类型4 UUID是基于随机数,两者并不完全相同,Java里面UUID.randomUUID()可以创建类型4的UUID,通过uuid.version()可以看到,我也不知道类型1的UUID是怎么创建出来的。
集合类型
Cassandra查询语言还提供了一个集合数据类型。下表提供了CQL中可用的集合的列表。
| 集合 | 描述 |
|---|---|
| list | 列表是一个或多个有序元素的集合。 |
| map | 地图是键值对的集合。 |
| set | 集合是一个或多个元素的集合。 |
用户定义的数据类型
Cqlsh为用户提供了创建自己的数据类型的工具。下面给出了处理用户定义的数据类型时使用的命令。
- CREATE TYPE -创建用户定义的数据类型。
- ALTER TYPE -修改用户定义的数据类型。
- DROP TYPE -删除用户定义的数据类型。
- DESCRIBE TYPE -描述用户定义的数据类型。
- DESCRIBE TYPES -描述用户定义的数据类型。
Cassandra CQL集合
CQL提供了使用Collection数据类型的功能。使用这些集合类型,您可以在单个变量中存储多个值。本章介绍如何在Cassandra中使用Collections。
List
List用于以下的情况下
- 将保持元素的顺序,并且
- 值将被多次存储。
您可以使用列表中元素的索引来获取列表数据类型的值
使用List创建表
下面给出了一个创建一个包含两个列(名称和电子邮件)的样本表的示例。要存储多个电子邮件,我们使用列表。
cqlsh:tutorialspoint> CREATE TABLE data(name text PRIMARY KEY, email list<text>);
将数据插入列表
在将数据插入列表中的元素时,在如下所示的方括号[]中输入以逗号分隔的所有值。
cqlsh:tutorialspoint> INSERT INTO data(name, email) VALUES ('ramu',['abc@gmail.com','cba@yahoo.com'])
更新列表
下面给出了一个在名为data的表中更新列表数据类型的示例。在这里,我们正在向列表中添加另一封电子邮件。
cqlsh:tutorialspoint> UPDATE data... SET email = email +['xyz@tutorialspoint.com']... where name = 'ramu';
验证
如果使用SELECT语句验证表,您将得到以下结果:
cqlsh:tutorialspoint> SELECT * FROM data;name | email------+--------------------------------------------------------------ramu | ['abc@gmail.com', 'cba@yahoo.com', 'xyz@tutorialspoint.com'](1 rows)
Set
Set是用于存储一组元素的数据类型。集合的元素将按排序顺序返回。
使用Set创建表
以下示例创建一个包含两个列(名称和电话)的样本表。对于存储多个电话号码,我们使用集合。
cqlsh:tutorialspoint> CREATE TABLE data2 (name text PRIMARY KEY, phone set<varint>);
将数据插入集合
在将数据插入集合中的元素时,请在花括号{}中输入逗号分隔的所有值,如下所示。
cqlsh:tutorialspoint> INSERT INTO data2(name, phone)VALUES ('rahman', {9848022338,9848022339});
更新集合
以下代码显示如何更新名为data2的表中的集合。在这里,我们正在添加另一个电话号码。
cqlsh:tutorialspoint> UPDATE data2... SET phone = phone + {9848022330}... where name = 'rahman';
验证
如果使用SELECT语句验证表,您将得到以下结果:
cqlsh:tutorialspoint> SELECT * FROM data2;name | phone--------+--------------------------------------rahman | {9848022330, 9848022338, 9848022339}(1 rows)
Map
地图是用于存储元素的键值对的数据类型。
使用Map创建表
以下示例显示如何创建具有两个列(名称和地址)的样本表。为了存储多个地址值,我们使用map。
cqlsh:tutorialspoint> CREATE TABLE data3 (name text PRIMARY KEY, addressmap<text, text>);
将数据插入到地图中
在将数据插入到地图中的元素时,输入所有的键:值对,用逗号在逗号之间以逗号分隔,如下所示。
cqlsh:tutorialspoint> INSERT INTO data3 (name, address)VALUES ('robin', {'home' : 'hyderabad' , 'office' : 'Delhi' } );
更新集合
以下代码显示如何在名为data3的表中更新地图数据类型。在这里,我们改变了关键办公室的价值,也就是说,我们改变一个名为robin的人的办公地址。
cqlsh:tutorialspoint> UPDATE data3... SET address = address+{'office':'mumbai'}... WHERE name = 'robin';
验证
如果使用SELECT语句验证表,您将得到以下结果:
cqlsh:tutorialspoint> select * from data3;name | address-------+-------------------------------------------robin | {'home': 'hyderabad', 'office': 'mumbai'}(1 rows)
Cassandra CQL用户定义的数据类型
CQL提供了创建和使用用户定义的数据类型的功能。您可以创建一个数据类型来处理多个字段。本章介绍如何创建,更改和删除用户定义的数据类型。
创建用户定义的数据类型
命令CREATE TYPE用于创建用户定义的数据类型。其语法如下:
CREATE TYPE <keyspace name>.<data typename>( variable1, variable2)
示例
下面给出了创建用户定义数据类型的示例。在此示例中,我们正在创建一个包含以下详细信息的card_details数据类型。
| 字段 | 字段名称 | 数据类型 |
|---|---|---|
| credit card no | num | int |
| credit card pin | pin | int |
| name on credit card | name | text |
| cvv | cvv | int |
| Contact details of card holder | phone | set |
cqlsh:tutorialspoint> CREATE TYPE card_details (... num int,... pin int,... name text,... cvv int,... phone set<int>... );
注:用于用户定义数据类型的名称不应与保留类型名称一致。
验证
使用DESCRIBE命令验证是否已创建创建的类型。
describe type card_details
查询结果
CREATE TYPE tutorialspoint.card_details (num int,pin int,name text,cvv int,phone set<int>);
更改用户定义的数据类型
ALTER TYPE命令用于更改现有数据类型。使用ALTER,您可以添加新字段或重命名现有字段。
将字段添加到类型
使用以下语法向现有用户定义的数据类型添加新字段。
ALTER TYPE typenameADD field_name field_type;
以下代码向Card_details数据类型添加了一个新字段。这里我们添加一个名为email的新字段。
cqlsh:tutorialspoint> ALTER TYPE card_details ADD email text;
验证
使用DESCRIBE命令验证是否添加新字段。
cqlsh:tutorialspoint> describe type card_details;CREATE TYPE tutorialspoint.card_details (num int,pin int,name text,cvv int,phone set<int>,email text);
在类型中重命名字段
使用以下语法重命名现有的用户定义数据类型。
ALTER TYPE typenameRENAME existing_name TO new_name;
以下代码更改类型中字段的名称。这里我们将字段电子邮件重命名为邮件。
cqlsh:tutorialspoint> ALTER TYPE card_details RENAME email TO mail;
验证
使用DESCRIBE命令验证类型名称是否已更改。
cqlsh:tutorialspoint> describe type card_details;CREATE TYPE tutorialspoint.card_details (num int,pin int,name text,cvv int,phone set<int>,mail text);
删除用户定义的数据类型
DROP TYPE是用于删除用户定义的数据类型的命令。下面给出了一个删除用户定义数据类型的示例。
示例
在删除之前,使用DESCRIBE_TYPES命令验证所有用户定义的数据类型的列表,如下所示。
cqlsh:tutorialspoint> DESCRIBE TYPES;card_details card
从这两种类型中,删除名为card的类型,如下所示。
cqlsh:tutorialspoint> drop type card;
使用DESCRIBE命令验证数据类型是否丢失。
cqlsh:tutorialspoint> describe types;card_details
Cassandra 相关资源
以下资源包含有关Cassandra的其他信息。请使用它们获得有关此主题的更深入的知识。
Cassandra 相关链接
- Cassandra - Cassandra官方网站。
- Cassandra 维基百科 - Cassandra维基百科参考
Cassandra 相关书籍






友情链接
本文所有内容全部参考https://www.w3cschool.cn/cassandra/,并加入了一部分自己的理解

















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









