






 本文通过使用Python和sklearn库,在西瓜数据集上实现了K近邻分类器,并对比了不同权重设置下分类效果的变化。同时,展示了决策树与K近邻分类器在数据划分上的差异。
本文通过使用Python和sklearn库,在西瓜数据集上实现了K近邻分类器,并对比了不同权重设置下分类效果的变化。同时,展示了决策树与K近邻分类器在数据划分上的差异。
原题:在西瓜数据集上实现K近邻分类器。
#!/usr/bin/python # -*- coding:utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier file1 = open('c:\quant\watermelon.csv','r') data = [line.strip('\n').split(',') for line in file1] data = np.array(data) #X = [[float(raw[-7]),float(raw[-6]),float(raw[-5]),float(raw[-4]),float(raw[-3]), float(raw[-2])] for raw in data[1:,1:-1]] X = [[float(raw[-3]), float(raw[-2])] for raw in data[1:]] y = [1 if raw[-1]=='1' else 0 for raw in data[1:]] X = np.array(X) y = np.array(y) print(__doc__) import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap from sklearn import neighbors, datasets n_neighbors = 5 # import some data to play with iris = datasets.load_iris() #X = iris.data[:, :2] # we only take the first two features. We could # avoid this ugly slicing by using a two-dim dataset #y = iris.target h = .02 # step size in the mesh # Create color maps cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF']) cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF']) for weights in ['uniform', 'distance']: # we create an instance of Neighbours Classifier and fit the data. clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights) clf.fit(X, y) # Plot the decision boundary. For that, we will assign a color to each # point in the mesh [x_min, m_max]x[y_min, y_max]. x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # Put the result into a color plot Z = Z.reshape(xx.shape) plt.figure() plt.pcolormesh(xx, yy, Z, cmap=cmap_light) # Plot also the training points plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold) plt.xlim(xx.min(), xx.max()) plt.ylim(yy.min(), yy.max()) plt.title("3-Class classification (k = %i, weights = '%s')" % (n_neighbors, weights)) plt.show()
结果如下:
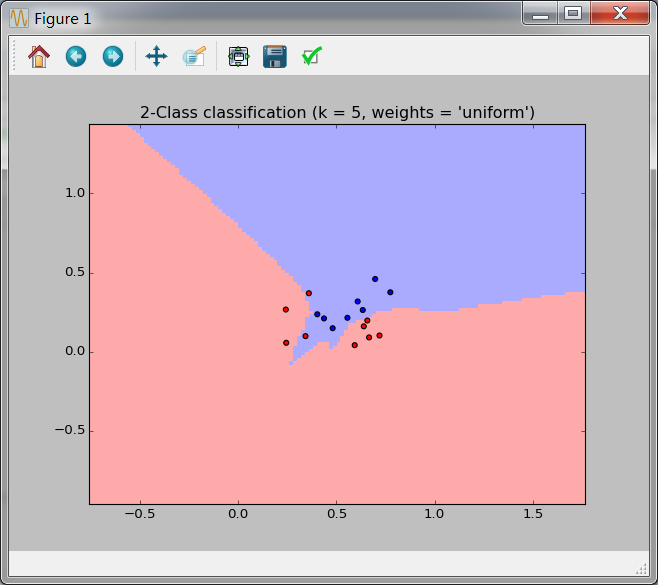
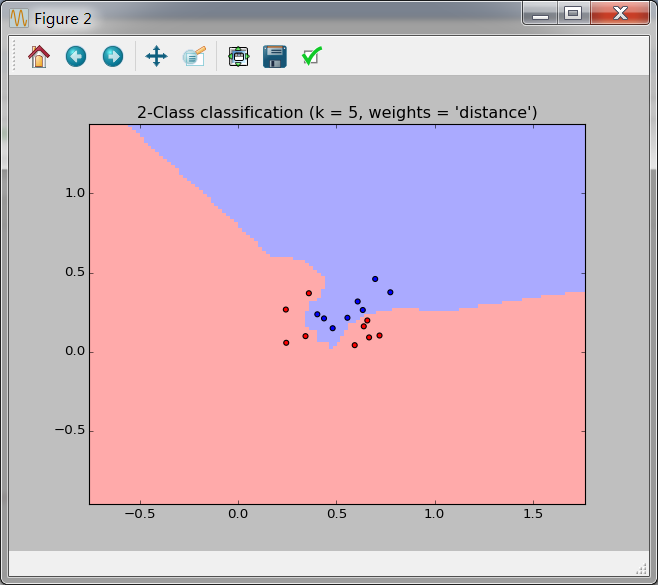
可以看到不同权重的分布对西瓜数据更加容易分类。
然后我们看决策树的分裂结果如下:
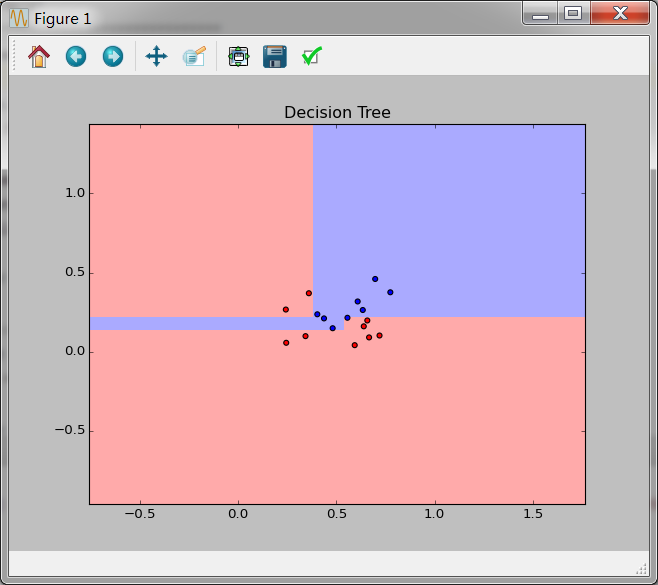
一个很明显的区别就是决策树的分裂边界是垂直于坐标轴的,二聚类的边界是任意形状和规则。

















 9732
9732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









