






 本文详细介绍了Fast R-CNN的结构原理,包括输入、深度网络处理过程、ROI pooling层的功能及其反向传播机制、mini-batch设置、损失函数构成及尺度不变性的实现。
本文详细介绍了Fast R-CNN的结构原理,包括输入、深度网络处理过程、ROI pooling层的功能及其反向传播机制、mini-batch设置、损失函数构成及尺度不变性的实现。
Fast RCNN的结构:
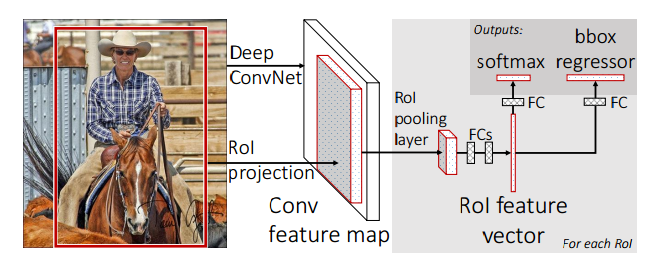
先从这幅图解释FAST RCNN的结构。首先,FAST RCNN的输入是包含两部分,image以及region proposal(在论文中叫做region of interest,ROI)。Image经过深度网络(deep network)之后得到feature map,然后可以从feature map中找到ROI在其中的投射projection得到每个patch,但论文没有提及怎么在map中寻找对应的patch,估计可以通过位置关系找到(猜想,因为deep ConvNet 之后相对的位置是不变的)。
把每个patch经过ROI pooling layer,再经过一系列的full connected layer后,分别完成了两个任务的预估:一是类别的预测softmax,一个是bounding box的预测。
在softmax的预测输出是类别的概率分布,而bounding box 预测为每个类别都输出预测回归方程计算的四个参数![]() (如上篇总结《Rich feature hierarchies for accurate object detection and semantic segmentation》中学习的四个参数,但论文中好像直接就是代表中心坐标以及长宽)。
(如上篇总结《Rich feature hierarchies for accurate object detection and semantic segmentation》中学习的四个参数,但论文中好像直接就是代表中心坐标以及长宽)。
ROI pooling layer:
ROI pooling layer其实是一个max pooling layer。假设有两个超参数H、W,把输入的patch划分成H*W个小方格,假设投影的每个ROI的patch为h*w,则每个小子方格的大小没h/H*w/W,而在每个方格中,执行的是max pooling layer 的操作。
在这里有必要继续的讨论一下在这个ROI pooling layer怎样反向误差传播。
首先要明白的是,BP算法其实应用的就是导数的链式法则,很巧妙地解决了误差的传播问题。如下公式:
![]()
其中aj代表卷积层的输入,而如果经过一个激活函数之后,得到zj=h(aj),其实zj才是下一层的输入,而对k求和代表所有包含zj作为输入的神经元。因此,可以得到公式![]() ,
,![]() 而就是误差。
而就是误差。
对应到pooling层,假设输入层的元素值xi,对应卷积层的i位置,![]() 对应的是第r个ROI的layer,它经过ROI pooling层后在对应输出到j位置。而xi是子窗口中的最大值。把一般的求误差的公式对应到ROI pooling中,
对应的是第r个ROI的layer,它经过ROI pooling层后在对应输出到j位置。而xi是子窗口中的最大值。把一般的求误差的公式对应到ROI pooling中,
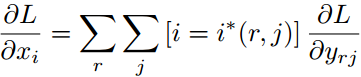
其中i*(r,j)表示第r个ROI从第i的输入(如果是子窗口中的最大像素值)对应到输出的第j的位置。而sigma(r)是因为某个像素可能落在多个ROI中。
Mini-batch:
当使用pre-trained网络的参数去初始化Fast RCNN网络时,需要三个改变。第一,把最后一层的max pooling使用ROI pooling层去替代;第二、最后一层fc层以及softmax层用softmax层和bounding box预测层替代;第三,输入包含两种数据:image以及ROI。
batch就是完成一次训练的数据集,这里对参数进行tune,就是有监督训练对参数进行微调(使用的是SGD,随机梯度下降法)。mini batch是通过随机采样得到的,首先随机选择N张图片,然后每张图片随机采样R/N个ROI。论文采用R=128,N=2。
今天想明白了一个batch是怎么完成一次训练。我开始以为是一次输入一个batch的数据集,其实不是的,一次处理的依然是一张的图片,而在最后输出层计算这张图片的产生的loss,把batch里的图片全部输入到网络里,就产生了loss的和LOSS,这时可以使用这个LOSS去执行BP算法,微调网络中的参数。
同样的,当IOU至少是0.5的才有可能是带有类别标志的,而0.1到0.5的认为是背景,而低于0.1的act as a heuristic for hard example mining(这里我也想不明白)。
损失函数:
损失函数由两部分组成,分别是类别误差函数以及定位误差:
![]()
(@2016/8/17 : 训练时每个ROI输入时应该都是有label的,这取决于它与label的IOU,如上小节所述。估计训练时的样本只会有一个bounding box)
其中类别误差取类别概率的负对数作为误差函数![]() 。而第二项定位误差,在真实类别u>=1时才有意义,u=0时表示背景。Bounding box的目标为v,如上文提到,它有四个参数
。而第二项定位误差,在真实类别u>=1时才有意义,u=0时表示背景。Bounding box的目标为v,如上文提到,它有四个参数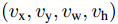 ,于是定位误差为:
,于是定位误差为:![]()
其中,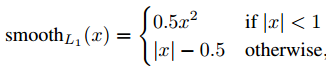 ,而且
,而且![]() 。
。
尺度不变性:
论文中实现尺度不变性是通过把图像固定。
随机梯度下降法:

@ 2016 /08/21 更新。
现在神经网络里用的SGD都是指min-batch SGD,找了一个例子from http://www.cnblogs.com/maybe2030/p/5089753.html#_label2


















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









