






 该项目模仿wc.exe工具,提供字符、单词和行数统计,扩展功能包括代码行、空行和注释行计数,支持图形界面操作。
该项目模仿wc.exe工具,提供字符、单词和行数统计,扩展功能包括代码行、空行和注释行计数,支持图形界面操作。
github地址
https://github.com/Pryriat/Word_Counter
项目说明
wc.exe 是一个常见的工具,它能统计文本文件的字符数、单词数和行数。这个项目要求写一个命令行程序,模仿已有wc.exe 的功能,并加以扩充,给出某程序设计语言源文件的字符数、单词数和行数。
实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。
具体功能要求:
程序处理用户需求的模式为:wc.exe [parameter][file_name]基本功能列表:
wc.exe -c file.c//返回文件 file.c 的字符数wc.exe -w file.c//返回文件 file.c 的词的数目wc.exe -l file.c//返回文件 file.c 的行数扩展功能:
-s递归处理目录下符合条件的文件。-a返回更复杂的数据(代码行 / 空行 / 注释行)。
空行:本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如“{”。
代码行:本行包括多于一个字符的代码。
注释行:本行不是代码行,并且本行包括注释。一个有趣的例子是有些程序员会在单字符后面加注释:
} //注释在这种情况下,这一行属于注释行。
[filename]:文件或目录名,可以处理一般通配符。
- 高级功能:
-x 参数。这个参数单独使用。如果命令行有这个参数,则程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、行数等全部统计信息。
- 需求举例:
wc.exe -s -a *.c
返回当前目录及子目录中所有*.c文件的代码行数、空行数、注释行数。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 20 |
| Estimate | 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | 300 | 340 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 60 |
| Design Spec | 生成设计文档 | 10 | 10 |
| Design Review | 设计复审 (和同事审核设计文档) | 0 | 0 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| Design | 具体设计 | 20 | 20 |
| Coding | 具体编码 | 100 | 110 |
| Code Review | 代码复审 | 40 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 100 | 100 |
| Reporting | 报告 | 50 | 80 |
| Test Report | 测试报告 | 10 | 10 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 60 |
| 合计 | 360 | 440 |
解题思路描述
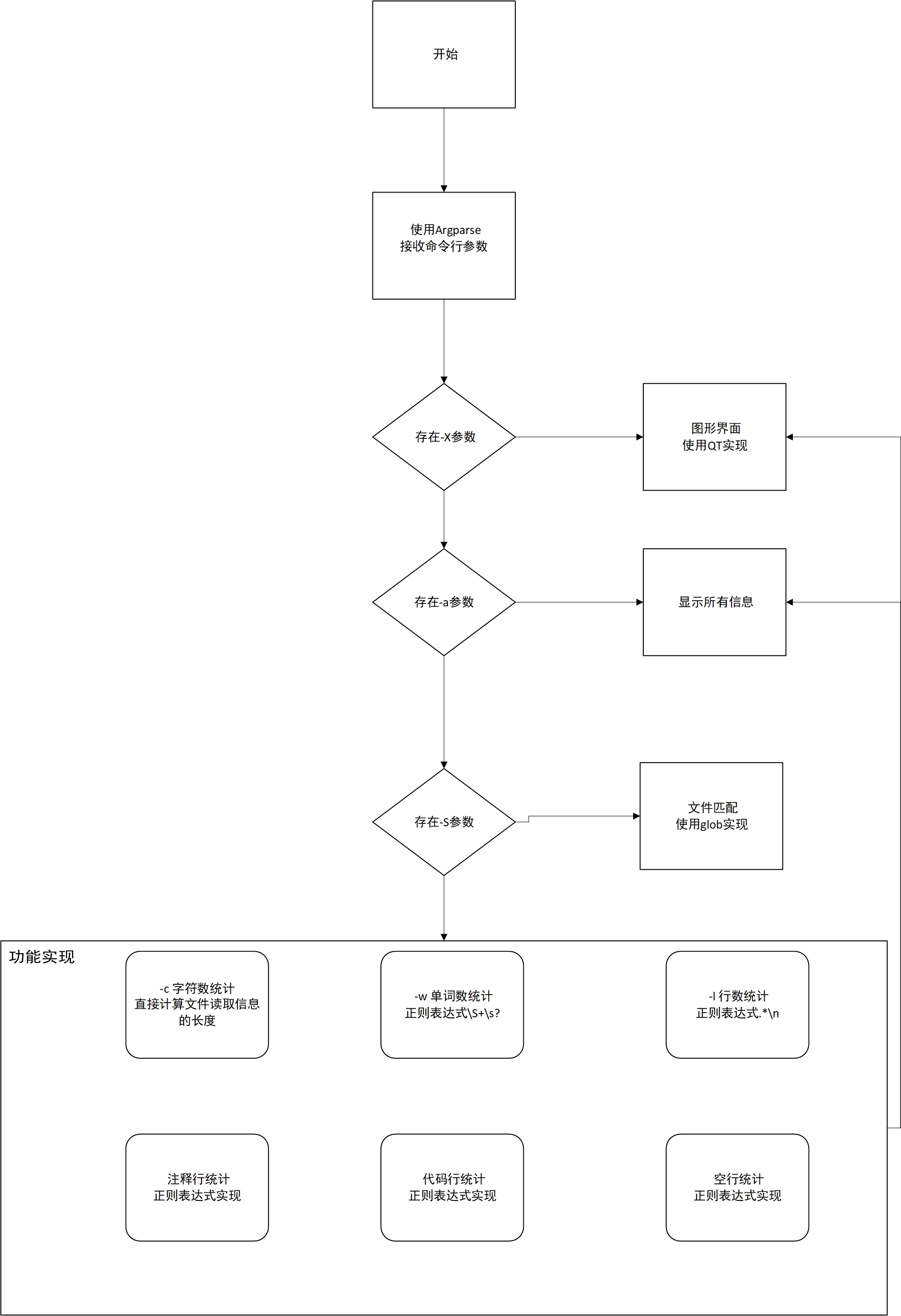
设计实现过程
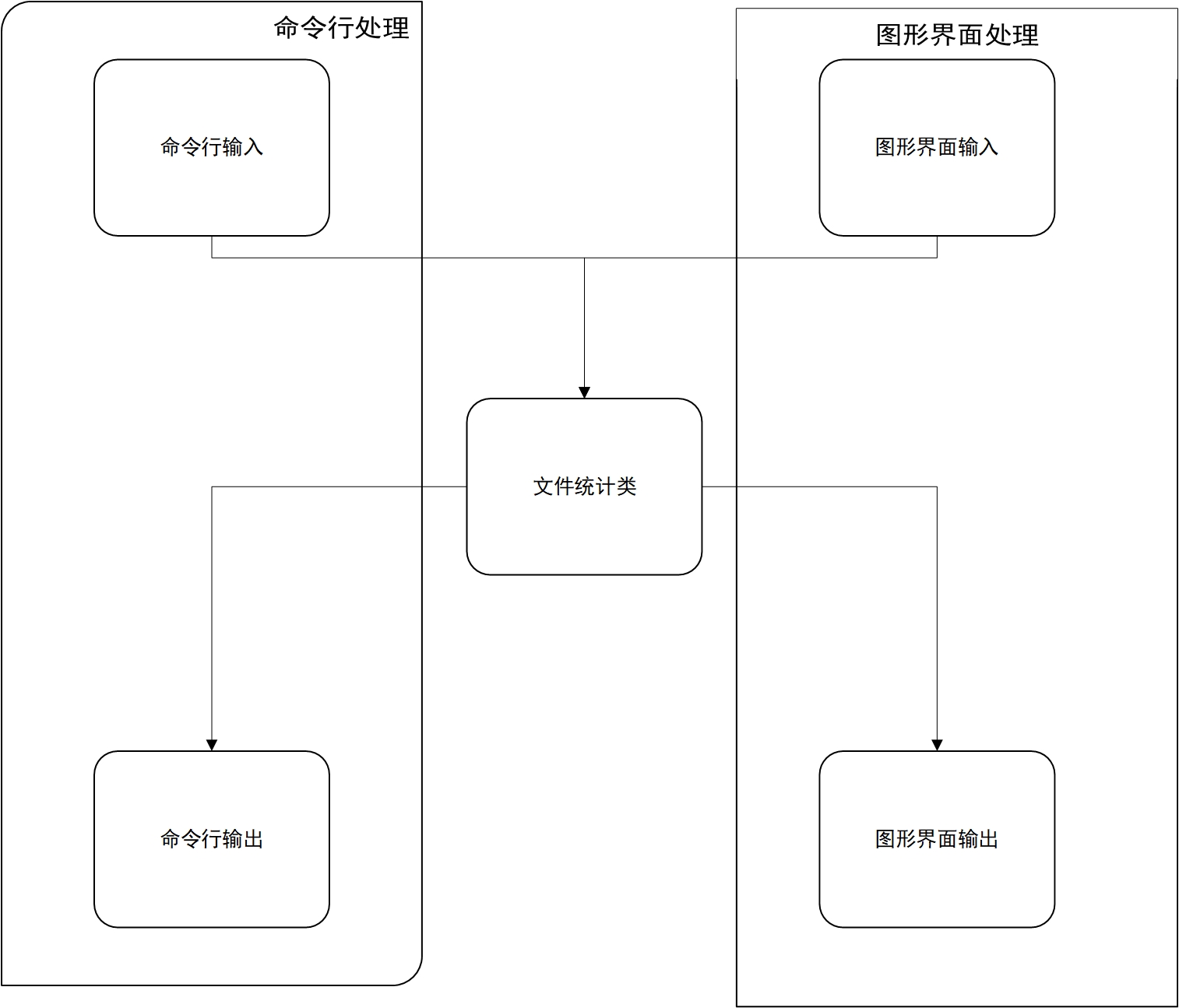
代码说明
控制台输入输出
#coding = UTF-8
from wc_class import word_counter
from ui_class import wc_ui
import argparse
import sys
from PyQt5.QtWidgets import *
from PyQt5.Qt import *
from PyQt5.QtGui import *
from PyQt5.QtCore import *
opt = {}
if len(sys.argv) == 1:
sys.argv.append('-h')# 如果未输入参数,则自动添加执行-h
parser = argparse.ArgumentParser(description='Word_Counter by Chenobyl',add_help=True)
parser.add_argument('-c',help='character counts',action="store_true")
parser.add_argument('-w',help='word counts',action="store_true")
parser.add_argument('-l',help='line counts',action="store_true")
parser.add_argument('-a',help='extra informations',action="store_true")
parser.add_argument('-s',help='match files',action="store_true")
parser.add_argument('-x',help='',action="store_true")
parser.add_argument('-f',default=None,help='input file')
args = parser.parse_args()#参数提取
for x,y in args._get_kwargs():
opt[x]=y
a = word_counter(opt)
if opt['x']:
app = QApplication(sys.argv)
u = wc_ui()
u.show()
sys.exit(app.exec())
elif opt['s']:
a.file_select()
else:
a.file_process(opt['f'])文件统计类
#coding = UTF-8
import re
import codecs
import getopt
import sys
import glob
class word_counter:
def __init__(self,opt):#用于存储文件统计结果的属性
self.char_num = 0
self.word_num = 0
self.lines = 0
self.nullline = 0
self.single_comment = 0
self.multi_comment = 0
self.code_line = 0
self.is_null = False
self.file = ''
self.opt=opt
def isnull(self,string):
'''
判断文件是否为空
'''
null_pattern = re.compile('.|\s')#判断文件是否有字符
tmp_result = null_pattern.findall(string)
if len(tmp_result) == 0:
return True
return False
def char_count(self,string):
'''
文件字符数统计
'''
return len(string)
def word_count(self,string):
'''
文件单词数统计
'''
word_pattern = re.compile('\S+\s?')#匹配模式:非空白+空白=单词
tmp_result = word_pattern.findall(string)
return len(tmp_result)
def line_count(self,string):
'''
文件行数统计、空行统计与代码行统计
'''
null_line = 0
code_line = 0
sepcial_pattern = re.compile('.*\n?')
tmp_result = sepcial_pattern.findall(string)
for lines in tmp_result:
if len(lines.strip()) == 0 or (len(lines.strip()) == 1 and lines.strip() in ['{','}','#','/','\\','(',')']):#规定中的空白行规则
null_line += 1
elif len(lines.strip())>=1 and lines[0]!= '/':
code_line += 1
return (len(tmp_result)-1,null_line-1,code_line)
def single_comment_count(self,string):
'''
单行注释统计
'''
re_pattern = re.compile('//')
del_pattern = re.compile('"[^"]*//[^"]*"')#排除双引号内情况
multi_in_single_pattern = re.compile('/\*.*')#排除多行注释内情况
tmp_result1 = re_pattern.findall(string)
tmp_result2 = del_pattern.findall(string)
for lines in tmp_result1:
if len(multi_in_single_pattern.findall(lines)) == 1:
self.multi_comment -= 1
print('sig',len(tmp_result1) - len(tmp_result2))
return len(tmp_result1) - len(tmp_result2)
def multi_comment_count(self,string):
'''
多行注释统计
'''
multi_lines = 0
del_lines = 0
multi_pattern = re.compile('/\*+[^\*]+\*/')
single_in_multi_pattern = re.compile('//.*')#排除单行注释内情况
del_pattern = re.compile('"[^"]*/\*[^"]*\*/')#排除双引号内情况
tmp_result = multi_pattern.findall(string)
for result1 in tmp_result:
self.single_comment -= len(single_in_multi_pattern.findall(result1))
for x in result1:
if x == '\n':
multi_lines+=1
del_result = del_pattern.findall(string)
for x in del_result:
if x == '\n':
del_lines += 1
return multi_lines - del_lines
def file_process(self,file):
'''
文件处理主函数
'''
with codecs.open(file, 'r', 'utf-8') as f:
self.file_string = f.read()
print('file:'+file,end=' ')
if self.isnull(self.file_string):
print('null file!')
return
else:
self.multi_comment += self.multi_comment_count(self.file_string)
self.single_comment += self.single_comment_count(self.file_string)
self.char_num += self.char_count(self.file_string)
self.word_num += self.word_count(self.file_string)
(self.lines,self.nullline) = self.line_count(self.file_string)
(self.lines,self.nullline,self.code_line) = self.line_count(self.file_string)
if self.opt['a'] :
print('character:'+str(self.char_num),end = ' ')
print('words:'+str(self.word_num),end=' ')
print('lines:'+str(self.lines),end=' ')
print('code_line:'+str(self.code_line),end=' ')
print('null_line:'+str(self.nullline),end=' ')
print('comment_line:'+str(self.single_comment+self.multi_comment))
else:
if not (self.opt['c'] or self.opt['w'] or self.opt['l']):
print('Please input command\n')
return
if self.opt['c']:
print('character:'+str(self.char_num),end = ' ')
if self.opt['w']:
print('words:'+str(self.word_num),end=' ')
if self.opt['l']:
print('lines:'+str(self.lines),end=' ')
def file_select(self):#文件匹配
print(self.opt['f'])
file_list = glob.glob(self.opt['f'])
for x in file_list:
self.file_process(x)图形界面类
from PyQt5.QtWidgets import *
from PyQt5.Qt import *
from PyQt5.QtGui import *
from PyQt5.QtCore import *
from wc_class import word_counter
class wc_ui(QDialog):
def __init__(self, parent=None):#控件初始化
super().__init__()
self.opt = opt = {'a':True}
self.wc = word_counter(self.opt)
self.setWindowTitle('Word Counter by Chernobyl')
self.file_label = QLabel()
self.is_null_label = QLabel('isnull:')
self.character_label = QLabel('character:')
self.word_label = QLabel('word:')
self.line_label = QLabel('line:')
self.null_line_label = QLabel('null_line:')
self.code_line_label = QLabel('code_line:')
self.comment_line_label = QLabel('comment_line:')
self.mainlayout = QVBoxLayout()
self.file_button = QPushButton('select file')
self.file_button.clicked.connect(self.selectfile)
self.mainlayout.addWidget(self.file_label)
self.mainlayout.addWidget(self.is_null_label)
self.mainlayout.addWidget(self.character_label)
self.mainlayout.addWidget(self.word_label)
self.mainlayout.addWidget(self.line_label)
self.mainlayout.addWidget(self.null_line_label)
self.mainlayout.addWidget(self.code_line_label)
self.mainlayout.addWidget(self.comment_line_label)
self.mainlayout.addWidget(self.file_button)
self.setLayout(self.mainlayout)
def selectfile(self):#选择文件,并获取所有信息,更新控件的显示值
file_name = QFileDialog.getOpenFileName(self,"select file ","C:\\","c source files(*.c);;cpp source files(*.cpp);;header files(*.h)")
self.wc.file_process(file_name[0])
self.file_label.setText('file: %s'%(file_name[0]))
self.is_null_label.setText('isnull: %s'%(str(self.wc.is_null)))
self.character_label.setText('character: %d'%(self.wc.char_num))
self.word_label.setText('word: %d'%(self.wc.word_num))
self.line_label.setText('line: %d'%(self.wc.lines))
self.code_line_label.setText('code_line: %d'%(self.wc.code_line))
self.comment_line_label.setText('comment_line: %d'%(self.wc.single_comment+self.wc.multi_comment))
self.null_line_label.setText('null_line: %d'%(self.wc.nullline))运行截图
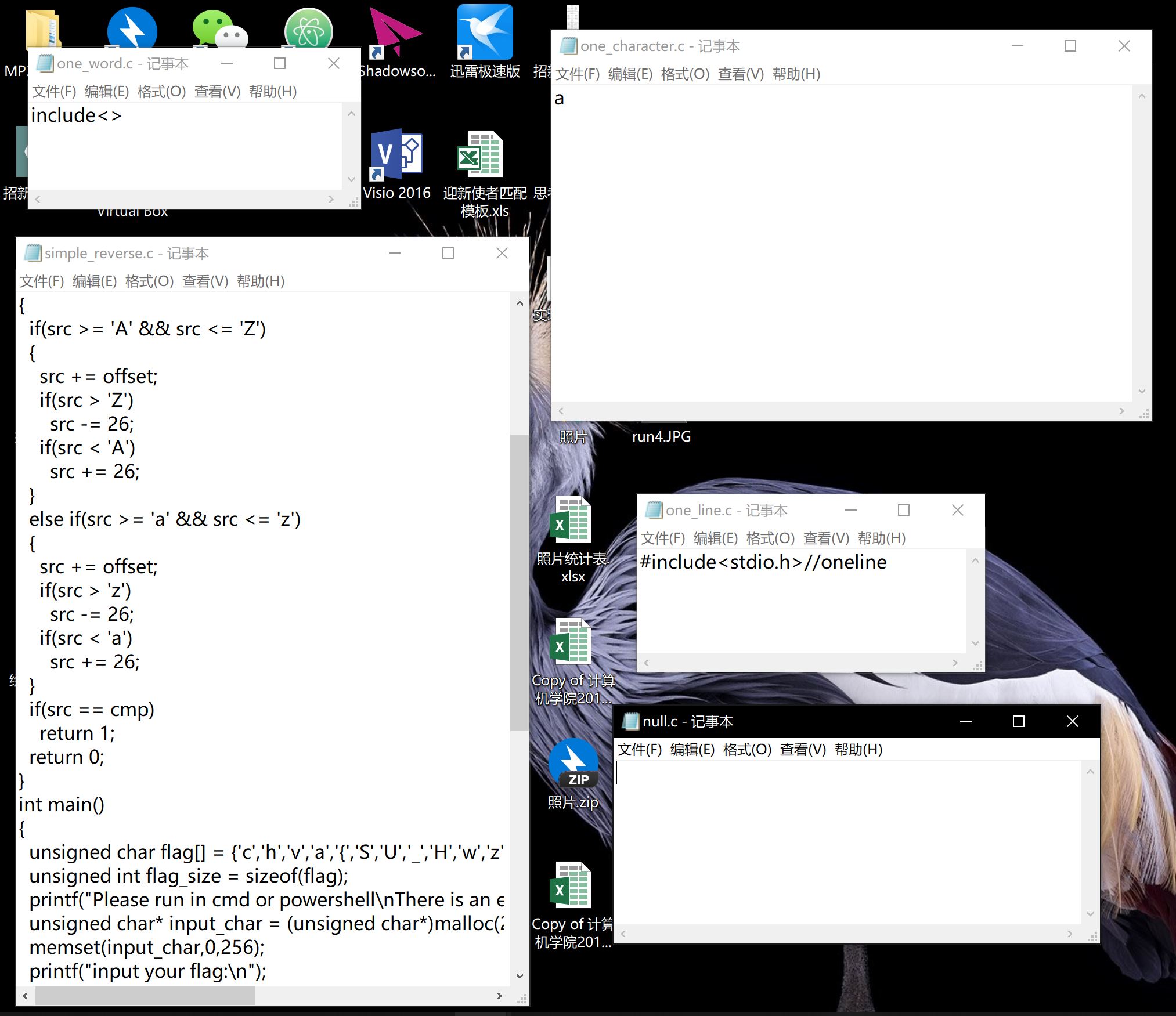
- 按照题目要求所创建的5个文件——空白、一个字母、一个单词、一整行、普通文件。截图如下
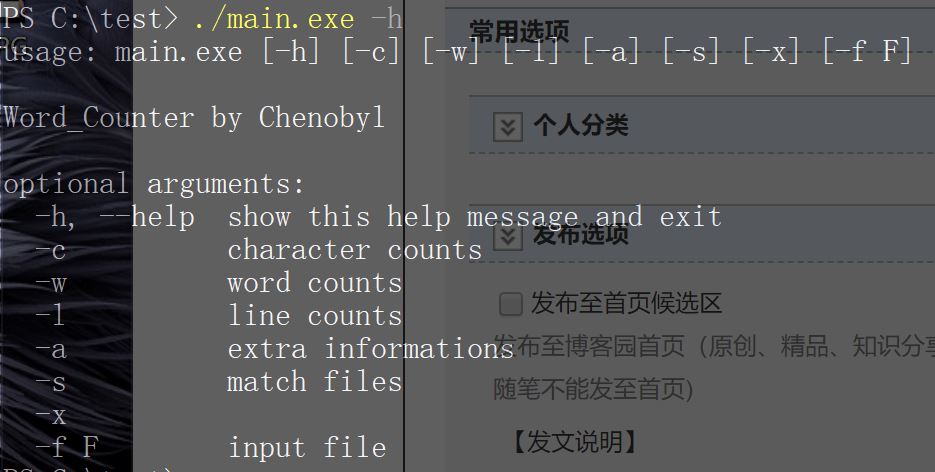
软件帮助界面如下
- 使用ubuntu内置的wc工具结果如下。注意,猜测wc工具的匹配规则为结尾有换行符算作一行——这是个bug,因为示例一行文件中虽然结尾无换行符,但应算作一行
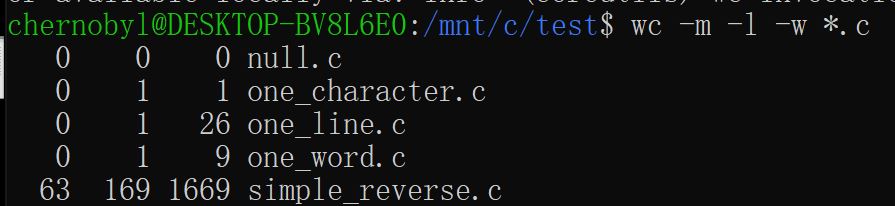
- 使用自己实现的wc工具结果如图

图形界面截图如下
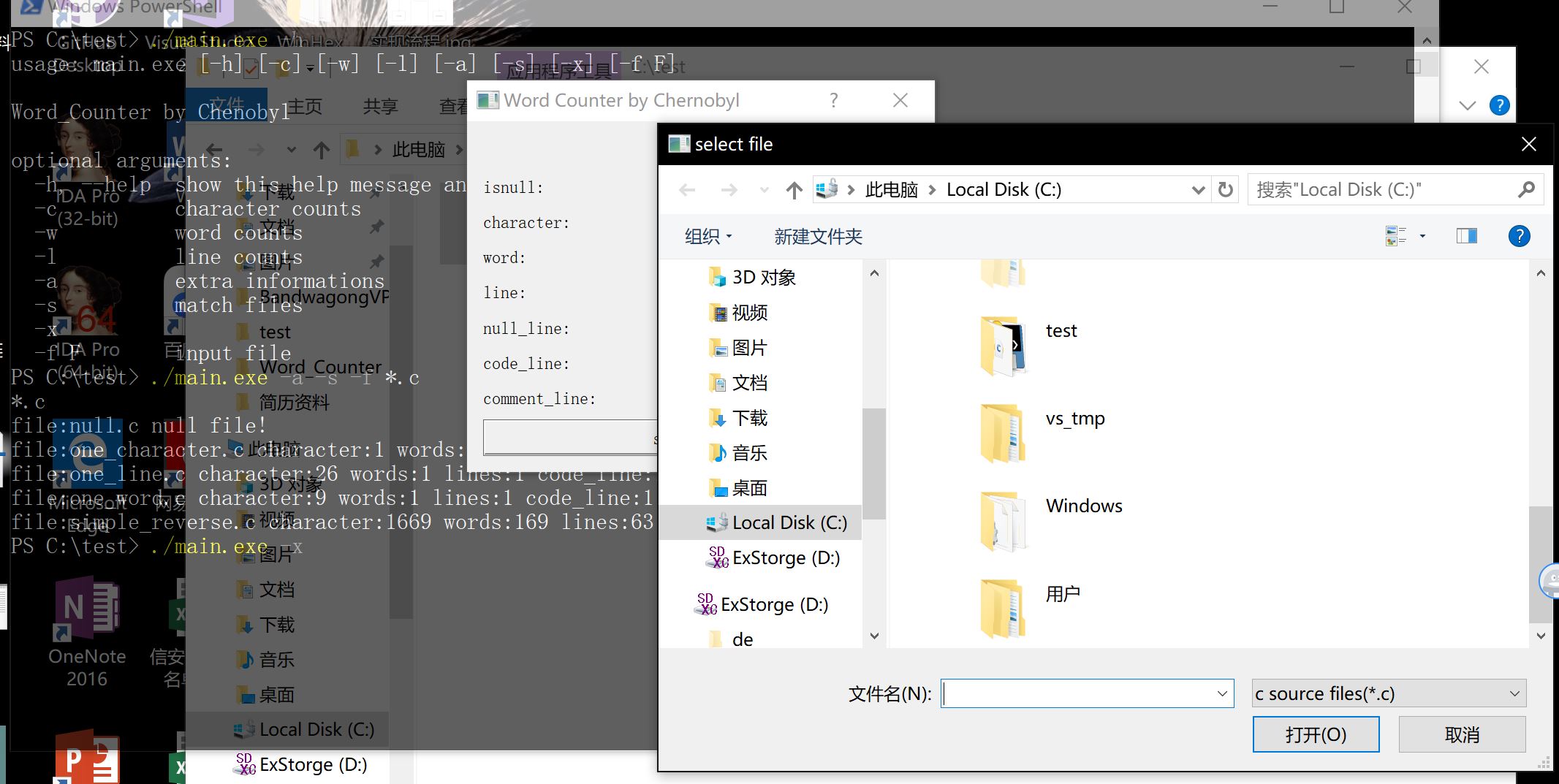
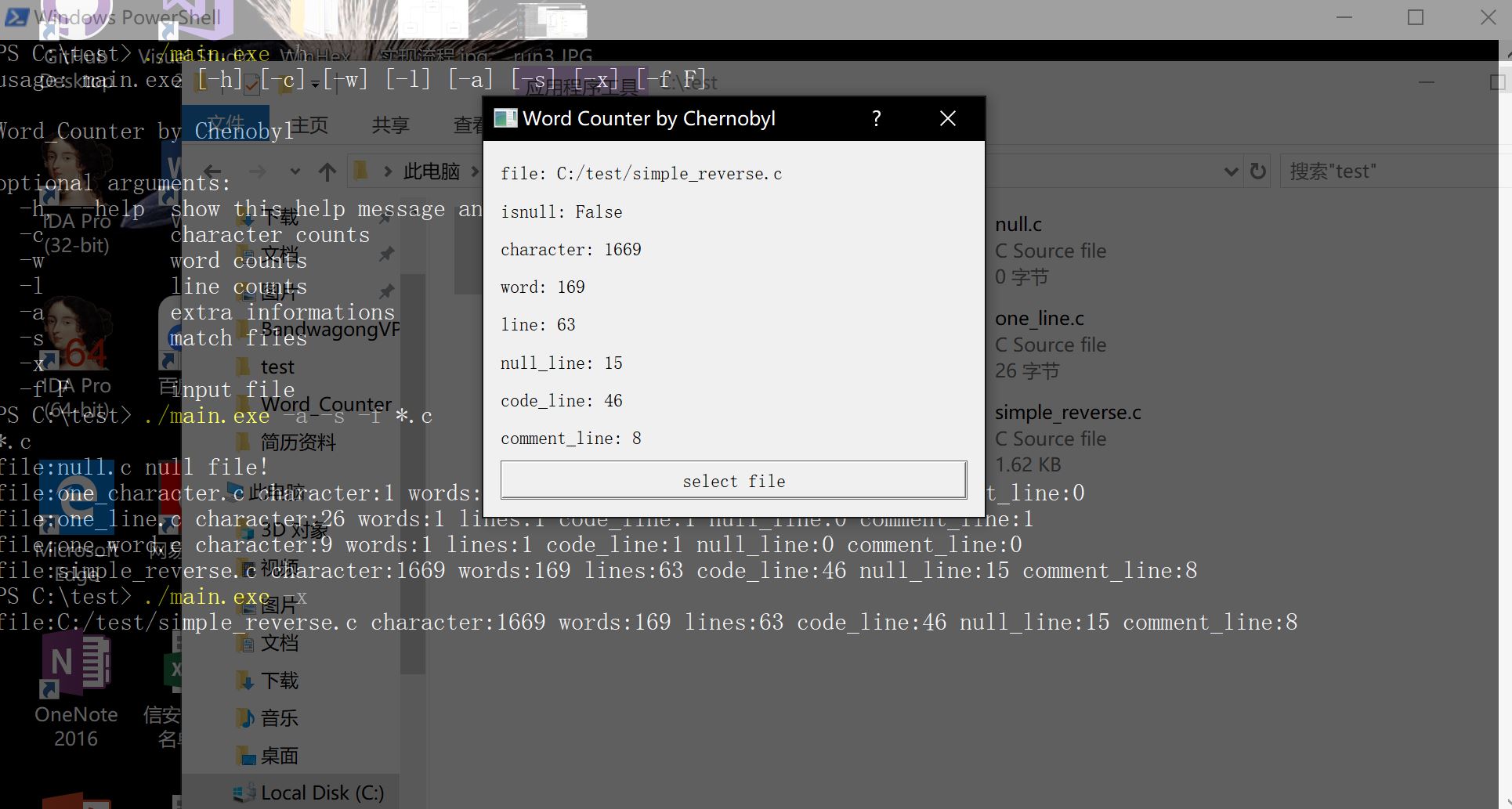
项目小结
- 发现了在进行软件项目时的诸多问题,如进度管控、功能实现、debug等
- 发现了wc工具的"bug"
- 熟悉了python的图形界面编写和程序打包

















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









