






 提出RotationNet模型,利用多视图图像输入同时估计物体姿态与类别。该模型可在部分多视图条件下工作,并通过姿态对齐获得跨类别共享的视图特征表示,在多个数据集上取得了最佳性能。
提出RotationNet模型,利用多视图图像输入同时估计物体姿态与类别。该模型可在部分多视图条件下工作,并通过姿态对齐获得跨类别共享的视图特征表示,在多个数据集上取得了最佳性能。
Author
一作: Asako Kanezaki 是个漂亮的小姐姐, AIST 日本东京的研究所

Abstract
提出了RotationNet,用multi-view图片作为输入,同时估计物体的姿态和类别
它是用部分的multi-view图片做inference,这个性质使得它很实用,因为很多场景都只有部分的view
同时,论文提出的pose alignment的方法可以获得不同类别共享的的view-specific feature representations
RotationNet在ModelNet datasets 10- 40-class中都获得了SOTA
同时在object pose estimation中也获得了SOTA, 即使它在没有已知pose标签的数据集上训练
Introduction
However, in real-world scenarios, objects can often only be observed from limited viewpoints due to occlusions,which makes it difficult to rely on multi-view representations that are earned with the whole circumference(本文主要解决的问题: 当没有全围表示时,怎么用有限的view point images来学习特征)
object classification 和 viewpoint estimation时一个紧密相关的问题对,所以可以进行互补
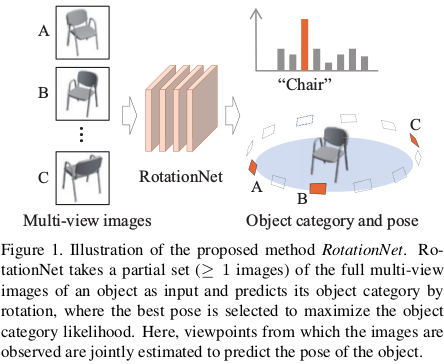
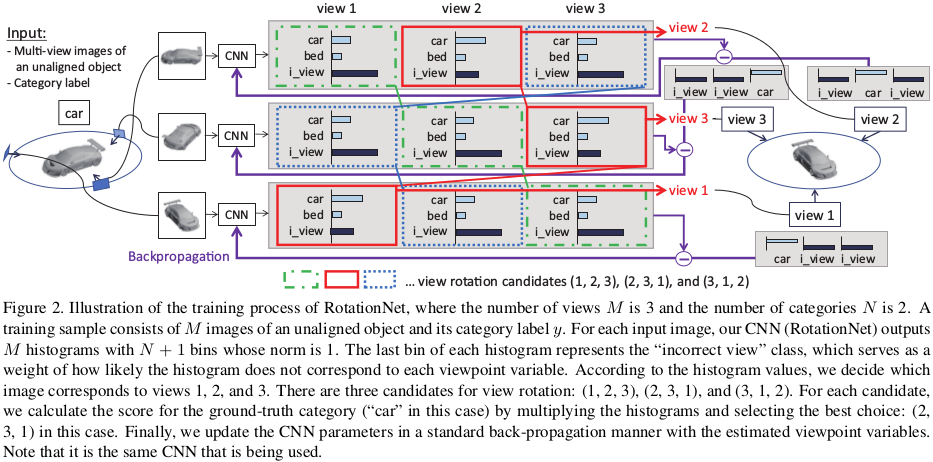
不是很看的懂,挖坑待填(等CVPR accepted list出来,看大神解读)

















 1865
1865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









