






 本文深入解析梯度下降算法,探讨其在机器学习中的应用。强调了梯度更新的同步性,学习率对收敛速度的影响,以及如何通过特征缩放提高算法效率。同时,介绍了批处理和小批量梯度下降的区别,提供了选择合适学习率的建议。
本文深入解析梯度下降算法,探讨其在机器学习中的应用。强调了梯度更新的同步性,学习率对收敛速度的影响,以及如何通过特征缩放提高算法效率。同时,介绍了批处理和小批量梯度下降的区别,提供了选择合适学习率的建议。
梯度更新是要同时更新,如下图所示:θ0和θ1同时更新,而不是更新完一个后再更新另一个。

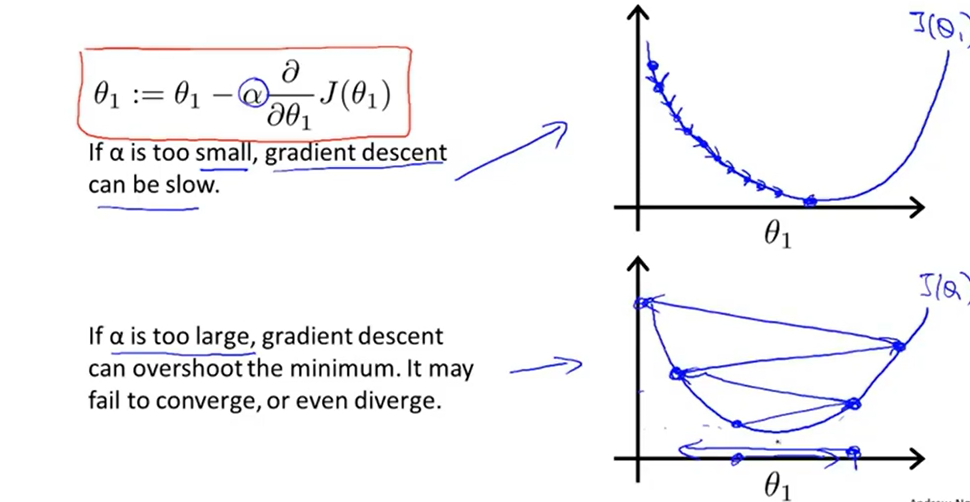
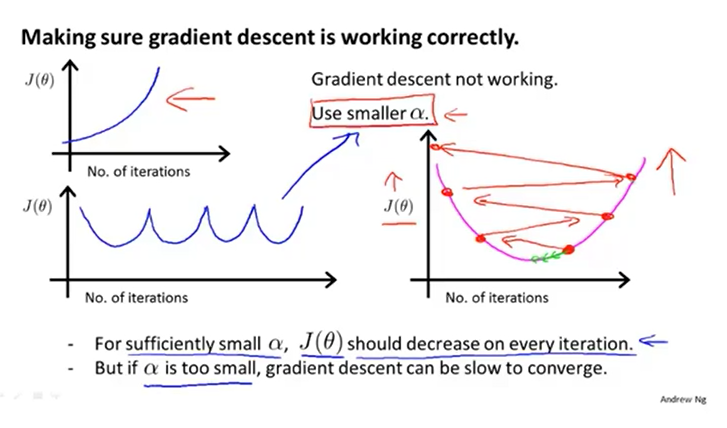
学习率α过小,梯度下降较慢,训练时间增长。若学习率α过大,梯度下降会越过最低点,难以得到最优的结果,导致难以收敛或发散。
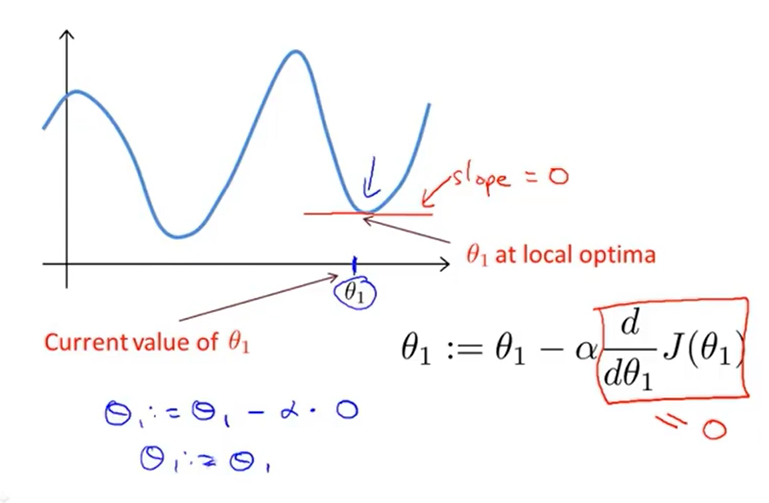
如果参数值已是局部最优,进行梯度下降计算时导数是0,梯度下降不会作任何操作,参数不改变
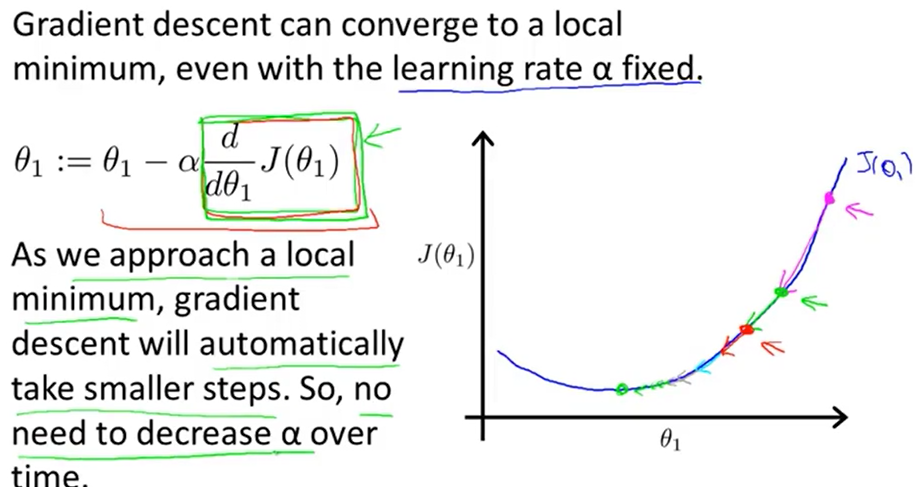
在梯度下过程中无需修改学习率,因为在接近局部最有点时导数项会变小,梯度下降的步幅也会随之比变小。
梯度下降中batch:指计算一次梯度下降就使用全部的训练集数据
mini batch :指计算一次梯度下降时使用了一小部分训练集数据

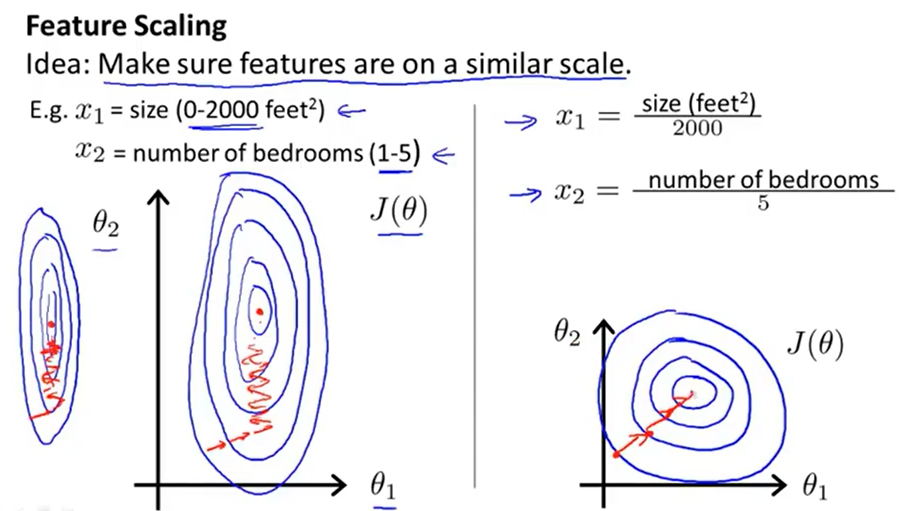
多元特征的梯度下降时,进行特征缩放,可将梯度下降的速度提高,通常将特征的取值缩放至大约-1到1之间
使用小的学习率,一般0.001,0.003,0.01,0.03,0.1,0.3,1等

















 4848
4848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









