






 本文介绍了R语言中PCA主成分分析的统计学背景,包括协方差和相关系数的概念,接着通过实例讲解了PCA的过程,如载入数据、主成分分析、结果解读,并展示了如何画主成分的碎石图和散点图。通过分析,前两个主成分的累积方差贡献率达到96.36%,可用于数据降维。
本文介绍了R语言中PCA主成分分析的统计学背景,包括协方差和相关系数的概念,接着通过实例讲解了PCA的过程,如载入数据、主成分分析、结果解读,并展示了如何画主成分的碎石图和散点图。通过分析,前两个主成分的累积方差贡献率达到96.36%,可用于数据降维。
微信公众号:生信小知识
关注可了解更多的教程及生信知识。问题或建议,请公众号留言;
R语言 PCA主成分分析
前言统计学背景知识协方差相关系数函数总结实例讲解1.载入原始数据2.作主成分分析3.结果解读4.画主成分的碎石图并预测5.PCA结果绘制后记
前言
PCA分析大家肯定经常看到,但是你真的懂PCA分析的结果吗?
图我也会看,我只是不是很清楚PCA背后输出结果的解读而已。正好看到一篇不错的博客,就把主要的知识点记录下 。
reference:
http://www.cnblogs.com/longzhongren/p/4300593.html
https://www.zhihu.com/question/20852004
223.主成分分析PCA
统计学背景知识
协方差
可以通俗的理解为:两个变量在变化过程中是同方向变化?还是反方向变化?同向或反向程度如何?
你变大,同时我也变大,说明两个变量是同向变化的,这时协方差就是正的。
你变大,同时我变小,说明两个变量是反向变化的,这时协方差就是负的。
从数值来看,协方差的数值越大,两个变量同向程度也就越大。反之亦然。
从公式出发来理解一下:
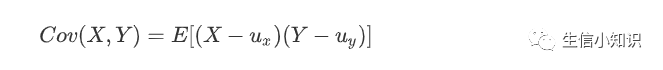
公式简单翻译一下是:如果有X,Y两个变量,每个时刻的“X值与其均值之差”乘以“Y值与其均值之差”得到一个乘积,再对这每时刻的乘积求和并求出均值(其实是求“期望”,但就不引申太多新概念了,简单认为就是求均值了)。
具体例子可以去知乎详细查看:
https://www.zhihu.com/question/20852004
相关系数
对于相关系数,我们从它的公式入手。一般情况下,相关系数的公式为:

翻译一下:就是用X、Y的协方差除以X的标准差和Y的标准差。
所以,相关系数也可以看成协方差:一种剔除了两个变量量纲影响、标准化后的特殊协方差。
既然是一种特殊的协方差,那它:
1、也可以反映两个变量变化时是同向还是反向,如果同向变化就为正,反向变化就为负。
2、由于它是标准化后的协方差,因此更重要的特性来了:它消除了两个变量变化幅度的影响,而只是单纯反应两个变量每单位变化时的相似程度。
具体例子可以去知乎详细查看:
https://www.zhihu.com/question/20852004
函数总结
注意:这里的输入数据,rownames是样本名,colnames是样本的特征。(与正常数据正好相反,需要用t()来转置数据)
princomp()主成分分析 可以从相关阵或者从协方差阵做主成分分析fviz_pca_ind对princomp()结果进行展示summary()提取主成分信息loadings()显示主成分分析或因子分析中载荷的内容predict()预测主成分的值screeplot()画出主成分的碎石图biplot()画出数据关于主成分的散点图和原坐标在主成分下的方向
实例讲解
现有30名中学生身高、体重、胸围、坐高数据,对身体的四项指标数据做主成分分析。
1.载入原始数据
# 清空环境
rm(list = ls())
options(stringsAsFactors = F)
# 准备数据
if (T) {
test X1=c(148, 139, 160, 149, 159, 142, 153, 150, 151, 139,
140, 161, 158, 140, 137, 152, 149, 145, 160, 156,
151, 147, 157, 147, 157, 151, 144, 141, 139, 148),
X2=c(41, 34, 49, 36, 45, 31, 43, 43, 42, 31,
29, 47, 49, 33, 31, 35, 47, 35, 47, 44,
42, 38, 39, 30, 48, 36, 36, 30, 32, 38),
X3=c(72, 71, 77, 67, 80, 66, 76, 77, 77, 68,
64, 78, 78, 67, 66, 73, 82, 70, 74, 78,
73, 73, 68, 65, 80, 74, 68, 67, 68, 70),
X4=c(78, 76, 86, 79, 86, 76, 83, 79, 80, 74,
74, 84, 83, 77, 73, 79, 79, 77, 87, 85,
82, 78, 80, 75, 88, 80, 76, 76, 73, 78)
)
rownames(test) "student_",1:30)
colnames(test) "height","weight","chest","sit-h")
}
2.作主成分分析
# PCA分析
if (T) {
test.prTRUE)
summary(test.pr,loadings=TRUE)
}
# Importance of components:
# Comp.1 Comp.2 Comp.3 Comp.4
# Standard deviation 1.8817805 0.55980636 0.28179594 0.25711844
# Proportion of Variance 0.8852745 0.07834579 0.01985224 0.01652747
# Cumulative Proportion 0.8852745 0.96362029 0.98347253 1.00000000
#
# Loadings:
# Comp.1 Comp.2 Comp.3 Comp.4
# height 0.497 0.543 0.450 0.506
# weight 0.515 -0.210 0.462 -0.691
# chest 0.481 -0.725 -0.175 0.461
# sit-h 0.507 0.368 -0.744 -0.232
结果解读:
Standard deviation 标准差 其平方为方差=特征值
Proportion of Variance 方差贡献率
Cumulative Proportion 方差累计贡献率
由结果显示:前两个主成分的累计贡献率已经达到96.36%,可以舍去另外两个主成分,达到降维的目的。
因此可以得到函数表达式:
Z1 = 0.497*height + 0.515*weight + 0.481*chest + 0.507*sit-h
Z2 = 0.543*height - 0.210*weight - 0.725*chest + 0.368*sit-h
注意要点:
princomp()函数中:
cor是逻辑变量,当cor=TRUE表示用样本的相关矩阵R做主成分分析,当cor=FALSE表示用样本的协方差阵S做主成分分析
summary()函数中:
loading是逻辑变量,当loading=TRUE时表示显示loading 的内容,loadings的输出结果为载荷是主成分对应于原始变量的系数,即Q矩阵
3.结果解读
这里我们可以看一看得到的test.pr变量的结构:
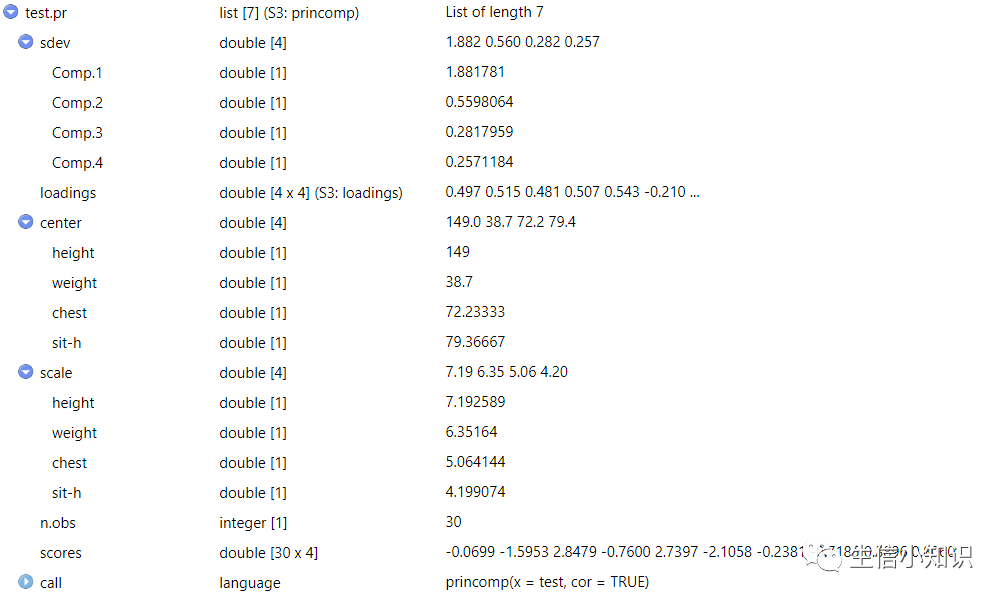
sdev是标准偏差
center是每列计算是减去的均值
scores即降维之后的结果
我们可以利用函数来验证下scores的结果到底是什么意思:
library(factoextra)
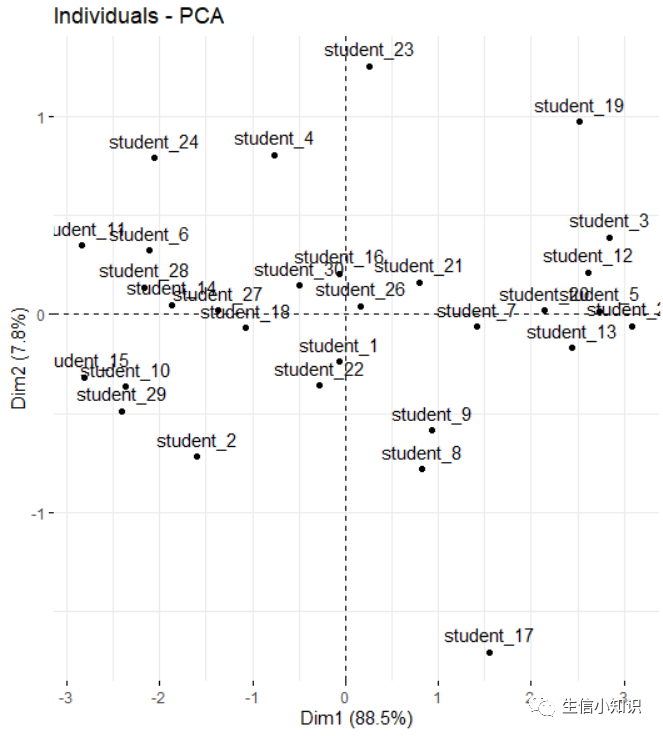
# PCA结果图
fviz_pca_ind(test.pr)
# 手动画散点图
ggplot(as.data.frame(test.pr$scores),aes(Comp.1,Comp.2)) + geom_point()
PCA结果图:
手动画散点图:
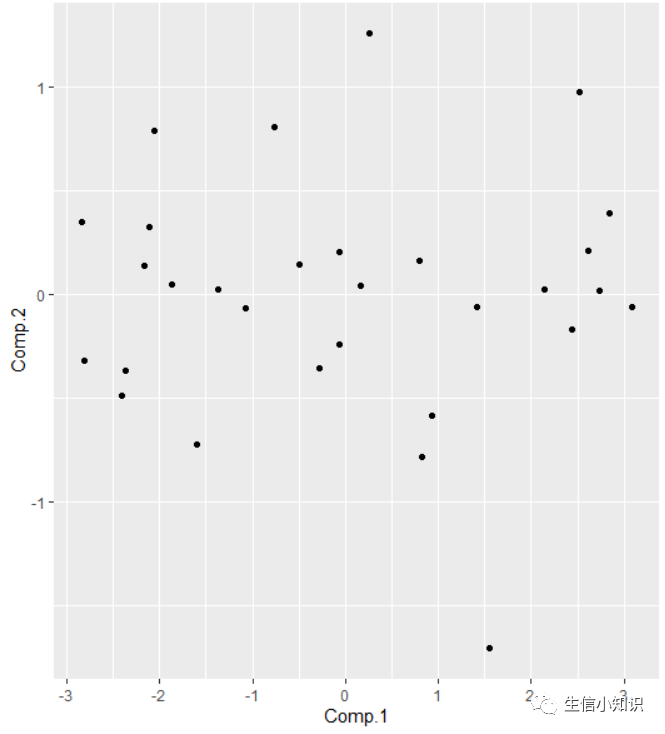
可以看到,这两者的结果图是一样的!
4.画主成分的碎石图并预测
screeplot(test.pr,type="lines")
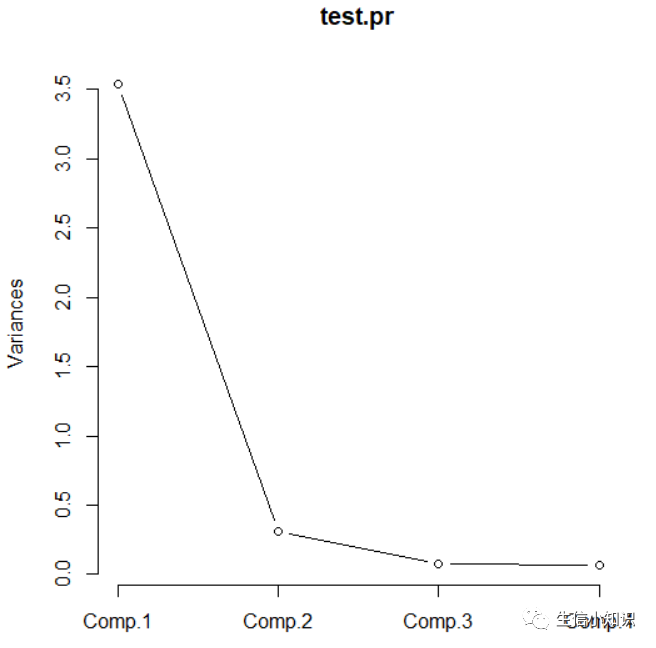
5.PCA结果绘制
主要用到的函数是fviz_pca_ind,这个函数来自factoextraR包,所以需要先安装&加载才可使用,下面记录下关于这个函数最常用的几个选项:
Usage
fviz_pca_ind(X, axes = c(1, 2), geom = c("point", "text"),
geom.ind = geom, repel = FALSE, habillage = "none", palette = NULL,
addEllipses = FALSE, col.ind = "black", fill.ind = "white",
col.ind.sup = "blue", alpha.ind = 1, select.ind = list(name = NULL, cos2
= NULL, contrib = NULL), ...)
Arguments
# geom——指定图形上是只显示点,还是同时也显示标签。默认同时显示。
# palette——自行指定颜色
# addEllipses——加95%置信椭圆
# col.ind——每个点的颜色
# legend.title——指定legend的名字
下面看实例:
fviz_pca_ind(test.pr,
geom.ind = "point",
col.ind = as.character(c(rep("Normal",15),rep("Tumor",15))),
palette = c("red", "black"),
addEllipses = T,
legend.title = "Groups")
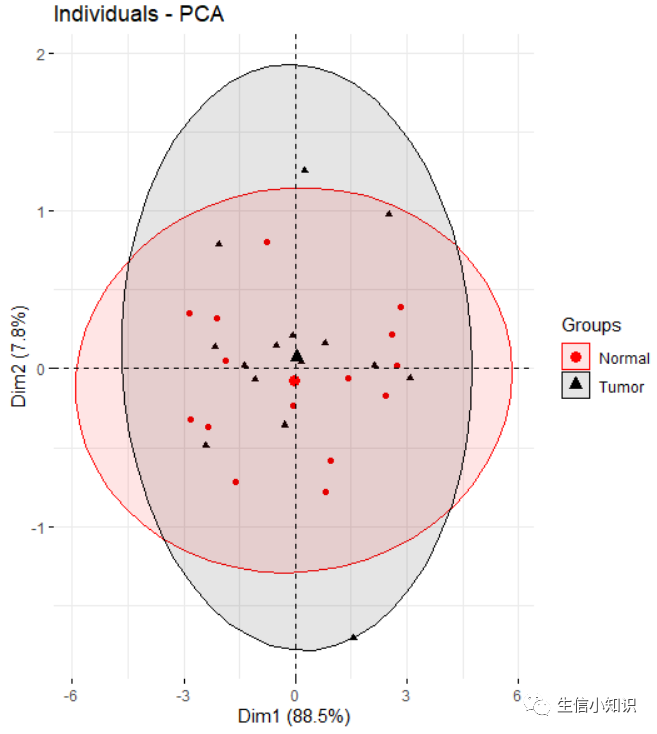
是有点丑了,不过也是为了方便理解这个函数每个参数的意义。
后记
稍微整理了下,感觉对PCA怎么画有了更多了解,虽然之前画过,但是都是跑流程,从没有关注具体结果,所以,看似简单,但是却不熟悉。

















 1705
1705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









