






 本文详细介绍了Merge排序算法的动机、伪代码实现及运行时间分析,通过实例展示了如何使用Merge排序对数组进行升序排序,并深入探讨了其复杂度与效率。
本文详细介绍了Merge排序算法的动机、伪代码实现及运行时间分析,通过实例展示了如何使用Merge排序对数组进行升序排序,并深入探讨了其复杂度与效率。
<!doctype html>
algo-C1-Introduction
Merge Sort:一.Motivation and Examplewhy study merge sort?The Sorting ProblemExample:二.Pseudocode:Pseudocode for Merge:Merge Sort Running Time:Running Time of Merge:Running Time of Merge SortRecall:三.AnalysisClaim:Question1:Question2Proof of claim
Merge Sort:
一.Motivation and Example
why study merge sort?
- Good introduction to divide & conquer
- Calibrate your preparation
- Motivates guiding principles for algorithm analysis(worst-case and asymptotic analysis)
- Analysis generalizes to “Master Method"
The Sorting Problem
Input: array of n numbers, unsorted. (5 4 1 8 7 2 6 3)
Output: same numbers, sorted in increasing order (1 … 8)
Example:
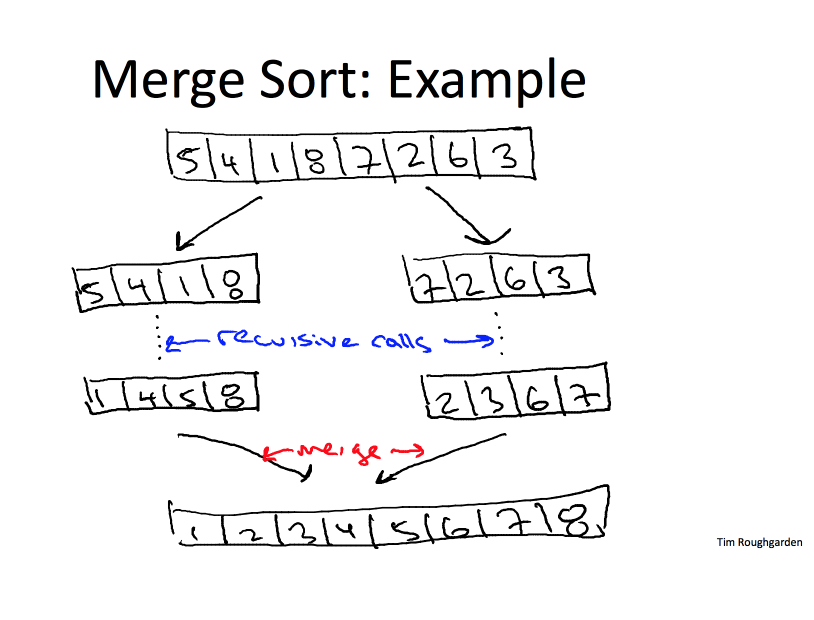
二.Pseudocode:
- recursively sort 1st half of input array
- recursively sort 2nd half of input array
- merge two sorted sublists into one[ ignores base cases]
Pseudocode for Merge:

Merge Sort Running Time:
Key Question: running time of MergeSort on array of n numbers?
[Running time ~ #of mines of code executed ]
Running Time of Merge:
running time of merge on array of m numbers is <= 4m + 2 <= 6m(since m >= 1)
Running Time of Merge Sort
Claim: MergeSort requires <=
operations for sort n numbers
Recall:
of times you divide by 2 until you get a number that drops below one
So if you plug in 32 you got to divide five time by two get down to one.
三.Analysis
Claim:
For every Input array of n numbers, Merge Sort produces a sorted output array and uses at most 6nlog_2n + 6n operations.
Proof of calim (assuming n = power of 2):
Question1:
how many levels does this recursion tree have.===>
beacause: {level0, level1……. level(log2n)} === > (log_2n - 0) + 1 ===>
Question2
at each level j = 0,1 ,2 , log_2n, there are 2^j subproblems, each of size n / 2^j.
第二个的原因很简单, 这颗递归树的第j层的子问题有 2^j 个, 例如第0层是1个, 第1层是两个, 由此类推, 所以每个的大小都是n / 2^j.
Proof of claim
第j层总的合并程序中所含有的指令次数是 <= 2 ^j * 6(n / 2^j) = 6n.也就是所每一层的合并程序内部所做的指令次数都是固定的, 为6n次, 所以对于这课共有log2n + 1个层的数, 总的操作次数为6n( log2n + 1) = 6nlog_2n + 6n.

















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









