







 对抗训练,源于2015年的Ian Goodfellow等人的工作,旨在通过加入对抗样本强化模型的鲁棒性。尽管这种方法提高了模型对对抗攻击的抵御能力,但也可能导致精度下降。2017年,Aleksander Madry等人提出使用PGD攻击进行对抗训练,证明了这种方法可以创建稳健的模型。然而,对抗训练存在速度慢和精度损失的问题。近年来,研究者们探讨了对抗训练与数据增强的关系,以及它作为正则化方法的角色,甚至将其与1991年的双反向传播概念相联系。尽管存在挑战,对抗训练已成为对抗防御研究的主流方法。
对抗训练,源于2015年的Ian Goodfellow等人的工作,旨在通过加入对抗样本强化模型的鲁棒性。尽管这种方法提高了模型对对抗攻击的抵御能力,但也可能导致精度下降。2017年,Aleksander Madry等人提出使用PGD攻击进行对抗训练,证明了这种方法可以创建稳健的模型。然而,对抗训练存在速度慢和精度损失的问题。近年来,研究者们探讨了对抗训练与数据增强的关系,以及它作为正则化方法的角色,甚至将其与1991年的双反向传播概念相联系。尽管存在挑战,对抗训练已成为对抗防御研究的主流方法。
在科学研究中,从方法论上来讲,都应“先见森林,再见树木”。当前,人工智能学术研究方兴未艾,技术迅猛发展,可谓万木争荣,日新月异。对于AI从业者来说,在广袤的知识森林中,系统梳理脉络,才能更好地把握趋势。为此,我们精选国内外优秀的综述文章,开辟“综述专栏”,敬请关注。
作者:知乎—Greene地址:https://www.zhihu.com/people/greene-31
01
什么是对抗训练?对抗训练(Adversarial Training)最初由 Ian Goodfellow 等人[1]提出,作为一种防御对抗攻击的方法,思路非常简单直接,将生成的对抗样本加入到训练集中去,做一个数据增强,让模型在训练的时候就先学习一遍对抗样本;为了加速对抗样本的生成过程以便于训练,他们同时提出了著名的 FGSM 攻击,假设损失函数在样本点处为局部线性,快速生成  范数限制下的对抗样本:
范数限制下的对抗样本:

后续有研究发现 FGSM 对抗训练并不是总能增强模型的对抗稳健性[2] (Adversarial Robustness),这也很好理解,因为 FGSM 这种单次线性构造对抗样本的方式显然生成的不是最优的对抗样本,另一方面这个方法设计之初也是为了快,而不是好。
2017年,Aleksander Madry[3] 等人提出使用更强的 PGD 攻击来进行对抗训练,并且在文中证明对抗训练可以获得一个稳健的模型。他们将对抗训练整理成了一个min-max优化问题:
寻找一个模型(以参数  表示),使得其能够正确分类扰动
表示),使得其能够正确分类扰动  在一定范围
在一定范围  内的对抗样本,即
内的对抗样本,即

其中  表示原始数据和对应的标签,
表示原始数据和对应的标签,  表示数据的分布,
表示数据的分布,  是损失函数。
是损失函数。
当内层达到最优的时候,他们证明在内层问题的最优解上求解外层问题可以获得整个问题的最优解,当然,实际实现时求解的都是近似最优。
彼时对抗训练并不是防御对抗攻击唯一的方法,还有诸如 Defensive Distillation[4]、Thermometer Encoding[5]、Pixel Defend[6]、对输入进行随机化处理[7]等看起来也很有前景的方法,但是接下来大部分都被证明本质是对模型进行了 Gradient Masking[8],即将模型的梯度进行了混淆,这样大部分白盒的攻击方法都不能有效利用梯度来进行攻击,但通过重建梯度或者使用较强的黑盒攻击方法,这些模型依然可以被攻破。
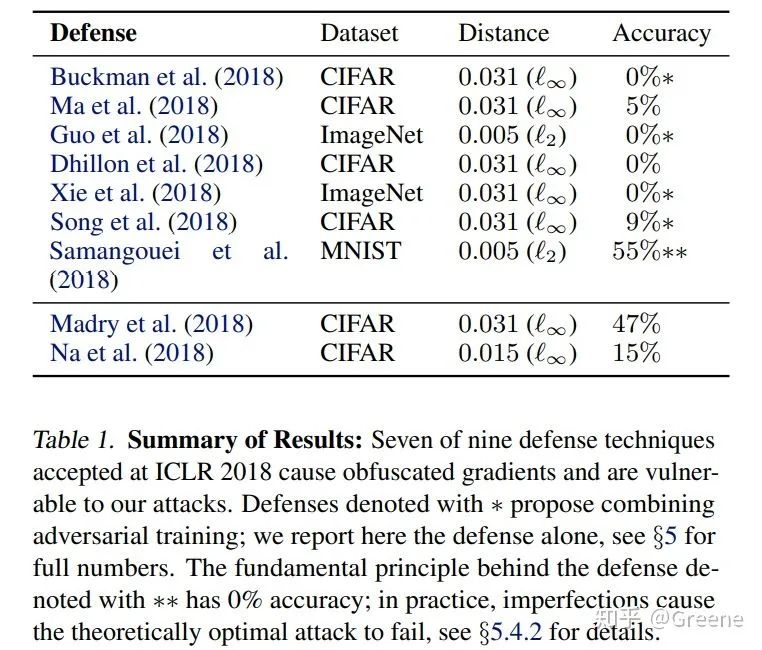
Anish Athalye 等人的评估结果 (没错,大部分研究还停留在CIFAR-10)
2018年,Anish Athalye 等人[9][10]对ICLR中展示的11种对抗防御方法进行了评估,最后他们只在基于对抗训练的两种方法上没有发现混淆梯度的迹象,自此之后,对抗训练成为对抗防御研究的主流。
对抗训练本身有两个显著的问题,一个是速度极慢,假设针对每个样本进行10次PGD对抗攻击来获得对
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









