



 本文详细介绍ELK(Elasticsearch, Logstash, Kibana)日志管理系统在实际项目中的部署与应用,涵盖从环境搭建、配置调整到集群部署的全过程。针对日志收集、分析、可视化等环节,提出解决方案,提升问题定位效率。
本文详细介绍ELK(Elasticsearch, Logstash, Kibana)日志管理系统在实际项目中的部署与应用,涵盖从环境搭建、配置调整到集群部署的全过程。针对日志收集、分析、可视化等环节,提出解决方案,提升问题定位效率。
传统日志管理问题快速到底
在项目初期的时候,大家都是赶着上线,一般来说对日志没有过多的考虑,当然日志量也不大,所以用 log4j 就够了,随着应用的越来越多,日志散落在各个服务器的 logs 文件夹下,确实有点不大方便。当我们需要日志分析的时候你大概会这么做:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但是这样的方式有很多问题:
1、日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询
2、应用太多,面临数十上百台应用时你该怎么办
3、随意登录服务器查询log对系统的稳定性及安全性肯定有影响
4、如果使用人员对Linux不太熟练那面对庞大的日志无从下手
ELK 简介
ELK 是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。
1、ElasticSearch
这是一个基于 Lucene 的分布式全文搜索框架,可以对 logs 进行分布式存储,有点像 hdfs。此为 ELK 的核心组件,日志的分析以及存储全部由 es 完成。
2、LogStash
它可以流放到各自的服务器上收集 Log 日志,通过内置的 ElasticSearch 插件解析后输出到 ES 中。
3、Kibana
它可以多维度的展示es中的数据。这也解决了用mysql存储带来了难以可视化的问题。他提供了丰富的UI组件,简化了使用难度。
ELK 作用
1、日志统一收集,管理,访问。查找问题方便安全
2、使用简单,可以大大提高定位问题的效率
3、可以对收集起来的 log 进行分析
4、能够提供错误报告,监控机制
ELK 架构选择
一般使用普通架构即可
普通架构
1、ElasticSearch:核心 提供查询,全文检索
2、Kibana:页面展示,及方便查询
3、Logstash:收集日志 主要有过滤功能,格式化,和其他个性化需求
使用场景:
能解决 50G 以下的 log,这个 50G 指的是 es 里面的总量。此时一般 es 所在的机器配置是 8G,es 比较吃 cpu 内存
高级架构
1、ElasticSearch:核心 提供查询,全文检索
2、Kibana:页面展示,及方便查询
3、FileBeat :轻量级收集日志系统,速度快,稳定不占资源
4、Redis:缓冲,防止把 es 搞垮了,和 kafka 二者取其一
5、Kafka:消息中间件,可缓存大数据量,日志一般存半个月
使用场景:
适用于一天产生几十G日志
推荐算法模型–》元数据来源于 log,redis 和 kafka 还有优势是做推荐的时候,可以即分发给 es 也分发给推荐算法
ELK 部署
下载地址:
https://www.elastic.co/cn/products
本次安装的版本信息:
JDK1.8
elasticsearch-6.2.2
logstash-5.6.3
kibana-5.2.0
elasticSearch 部署
下载的包传到服务器上解压后
修改 es 的配置
cd elasticsearch-6.2.2/config/
vi elasticsearch.yml
要修改的内容如下
1 # 集群名称 配置集群使用-非集群不配
2 #cluster.name: my-application
3 # 这个节点的名称
4 node.name: node-1
5 # 数据存放目录-注意启动 elasticsearch 的用户必须有该目录的读写权限
6 path.data: /usr/tkz/es_6.2.2/data
7 # 日志存放目录-注意启动 elasticsearch 的用户必须有该目录的读写权限
8 path.logs: /usr/tkz/es_6.2.2/logs
9 # Lock the memory on startup:
10 bootstrap.memory_lock: false
11 # 解决启动异常:ERROR: bootstrap checks failed
12 bootstrap.system_call_filter: false
13 # 允许访问的ip 0.0.0.0表示允许所有
14 network.host: 0.0.0.0
15 # 允许外部访问的http端口
16 http.port: 9200
17 # 安装elastic-head插件需要-作用是跨域
18 http.cors.enabled: true
19 http.cors.allow-origin: "*"
修改 linux 配置
elasticSearch 不允许 root 用户启动,新建用户用于启动 elasticSearch
# 创建 elasticsearch 用户组
groupadd elasticsearch
创建用户,-g 代表把 elasticsearch 用户分配到 elasticsearch 用户组中,-p 代表给 elasticsearch 用户设置密码为 123456;
useradd elasticsearch -g elasticsearch -p 123456
# 赋权限
chown elasticsearch:elasticsearch -R /usr/tkz/es_6.2.2/elasticsearch-6.2.2
es5.0 后修改 limit 限制,不修改启动会报错(注意:整个修改完之后需要使用 elasticsearch 用户重新登录)
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
vi /etc/security/limits.conf
# 下面的 elasticsearch 是上面创建的 elasticsearch 用户名称
# 格式: username hard nofile 65536
elasticsearch hard nofile 65536
elasticsearch soft nofile 65536
解决 max number of threads [1024] for user [apps] is too low, increase to at least [2048] 报错(这个我没有碰到这个问题,并且也没有这个文件)
vi /etc/security/limits.d/90-nproc.conf
修改
* soft nproc 1024
为
* soft nproc 2048
解决 max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144] 报错
echo 'vm.max_map_count=262144'>> /etc/sysctl.conf
sysctl -p
启动测试
启动
#切换到 elasticsearch 用户
su elasticsearch
./elasticsearch-6.2.2/bin/elasticsearch
开放端口
vi /etc/sysconfig/iptables
# 在打开的文件中加入如下内容
-A INPUT -p tcp -m state --state NEW -m tcp --dport 9200 -j ACCEPT
# 重启防火墙
service iptables restart
浏览器访问测试:
http://10.0.54.131:9200/
出现一串包含版本信息的 json 即为安装成功
logstash 部署
解压,在config目录建:logstash.conf,输入以下内容
vi logstash.conf
配置包含 input ,filter,output 三大块
其中 input 是吸取 logs 文件下的所有 log 后缀的日志文件
filter 是一个过滤函数,配置则可进行个性化过滤
output 配置了导入到 hosts 为 127.0.0.1:9200 的 elasticsearch 中,每天一个索引
input {
file {
type => "log"
path => "/logs/*.log"
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug { }
}
elasticsearch {
hosts => "127.0.0.1"
index => "log-%{+YYYY.MM.dd}"
}
}
start_position:
是监听的位置,默认是 end,即一个文件如果没有记录它的读取信息,则从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用 end 就可以了;相反,beginning 就会从一个文件的头开始读取。但是如果记录过文件的读取信息,则不会从最开始读取。重启读取信息不会丢失 bin 目录下启动 logstash 了,配置文件设置为config/logstash.conf
启动命令:
./logstash -f ../config/logstash.conf
配置不同的 logpath
在 config 目录下建立多个 .conf 文件,每个文件指定不同 path
指定启动目录:
./logstash -f ../config
kibana 部署
这个安装比较简单,解压后在 kibana.yml 文件中指定一下你需要读取的 elasticSearch 地址和可供外网访问的 bind 地址就可以了
vi kibana-5.2.0-linux-x86_64/config/kibana.yml
修改内容如下:
server.host: "0.0.0.0"
# 如果是集群则配置master节点
elasticsearch.url: http://localhost:9200
启动
./bin/kibana
开放端口
vi /etc/sysconfig/iptables
# 在打开的文件中加入如下内容
-A INPUT -p tcp -m state --state NEW -m tcp --dport 5601 -j ACCEPT
# 重启防火墙
service iptables restart
浏览器访问测试:
http://kibana所在机器ip:5601/
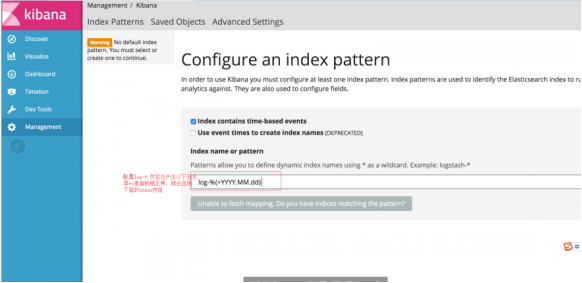
创建索引:
进入之后,在左侧栏菜单最后一项,创建索引,进入时没有创建按钮
我们在本机的 /logs 文件夹下创建一个简单的 1.log 文件,内容为 “hello world”,然后在 kibana 上将 logstash- 改成 log ,Create 按钮就会自动出来
插件安装
elastic-head 插件
下载
https://github.com/mobz/elasticsearch-head/archive/master.zip
解压
unzip elasticsearch-head-master.zip
#没有zip命令的可以安装一下
#yum install -y unzip zip
执行命令
curl --silent --location https://rpm.nodesource.com/setup | bash -
如果没安装 nodejs 的话需要安装
yum install -y nodejs
如果 node.js 版本过低,则需要升级
升级 node.js
# 第一步:首先安装 n 模块:
npm install -g n
# 第二步:升级node.js到最新稳定版
n stable
修改配置
cd elasticsearch-head-master
npm install grunt --save-dev
# 如果失败升级下node
npm install
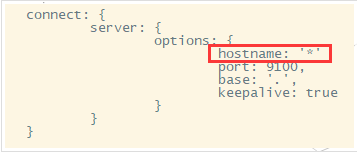
vi Gruntfile.js
在 connect 节点下 增加 hostname 属性,设置为* 注意加,号
修改 head 链接
vi elasticsearch-head-master/_site/app.js
将
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200";
把localhost修改成自己es的服务器地址
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://192.168.x.x:9200";
如果之前没在es的配置文件中配置以下内容的话,配置下(我上面es已经配置)
http.cors.enabled: true
http.cors.allow-origin: "*"
运行
cd elasticsearch-head-master/node_modules/grunt/bin
./grunt server &
开放端口
vi /etc/sysconfig/iptables
# 在打开的文件中加入如下内容
-A INPUT -p tcp -m state --state NEW -m tcp --dport 9100 -j ACCEPT
# 重启防火墙
service iptables restart
浏览器访问测试:
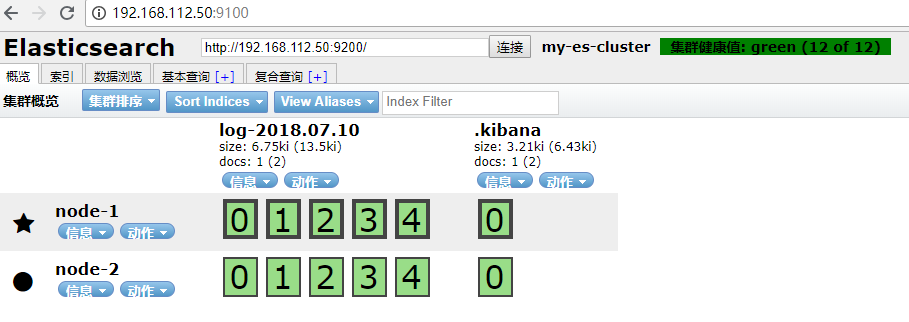
http://插件所在服务器ip:9100
elasticSearch 集群部署
以上配置完成后,elk已经可以正常使用,这里在记录下es集群的部署,这里在一台机器上部署集群,上面已经部署好的es为主节点,其 elasticsearch.yml 的配置内容如下:
1 #-----------------cluster集群新加配置------------------
2 # 集群名称 注意一个集群里面的机器一定要保持一致
3 cluster.name: "my-es-cluster"
4 # 尽量配置机器差作为主节点 注意只有两个节点的话第二个请配置为false
5 node.master: true
6 node.data: true
7 http.enabled: true
8 transport.tcp.port: 9300
9 # 单播(unicast)协议,指定要发现的节点信息了,可以不指定端口[默认9300]
10 discovery.zen.ping.unicast.hosts: ["192.168.112.50","192.168.112.50:8300"]
11 #默认是1看到的具有master节点资格的最小数量,然后才能在集群中做操作。官方的推荐值是(N/2)+1,如果只有2个节点设为1
12 discovery.zen.minimum_master_nodes: 1
13 # ping的超时时间,如果网络差则延长
14 # discovery.zen.ping.timeout: 60s
15 # 设置集群中自动发现其他节点时ping连接的超时时间
16 # discovery.zen.ping.timeout: 180s
17 #-------------cluster集群在单机基础上可能要修改配置------------------
18 # 这个节点的名称 同一个集群里面的名字不能相同
19 node.name: node-1
20 # 数据存放目录-注意启动elasticsearch的用户必须有该目录的权限
21 path.data: /tmp/elasticsearch/data
22 # 日志存放目录-注意启动elasticsearch的用户必须有该目录的权限
23 path.logs: /tmp/elasticsearch/logs
24 # 允许外部访问的端口
25 http.port: 9200
26 #-----------------单机和集群不变的配置------------------
27 bootstrap.memory_lock: false
28 # 解决启动异常:ERROR: bootstrap checks failed
29 bootstrap.system_call_filter: false
30 # 允许访问的ip 0.0.0.0表示允许所有
31 network.host: 0.0.0.0
32 # head插件跨域
33 http.cors.enabled: true
34 http.cors.allow-origin: "*"
复制一份主节点的 es 或重新解压一份 es,修改其 elasticsearch.yml 的配置内容如下:
1 #-----------------cluster集群新加配置------------------
2 # 集群名称 注意一个集群里面的机器一定要保持一致
3 cluster.name: "my-es-cluster"
4 # 尽量配置机器差作为主节点 注意只有两个节点的话第二个请配置为false
5 node.master: false
6 node.data: true
7 http.enabled: true
8 transport.tcp.port: 8300
9 # 单播(unicast)协议,指定要发现的节点信息了,可以不指定端口[默认9300]
10 discovery.zen.ping.unicast.hosts: ["192.168.112.50","192.168.112.50:8300"]
11 #默认是1看到的具有master节点资格的最小数量,然后才能在集群中做操作。官方的推荐值是(N/2)+1,如果只有2个节点设为1
12 discovery.zen.minimum_master_nodes: 1
13 # ping的超时时间,如果网络差则延长
14 # discovery.zen.ping.timeout: 60s
15 # 设置集群中自动发现其他节点时ping连接的超时时间
16 # discovery.zen.ping.timeout: 180s
17 #-------------cluster集群在单机基础上可能要修改配置------------------
18 # 这个节点的名称 同一个集群里面的名字不能相同
19 node.name: node-2
20 # 数据存放目录-注意启动elasticsearch的用户必须有该目录的权限
21 path.data: /tmp/elasticsearch/data-node2
22 # 日志存放目录-注意启动elasticsearch的用户必须有该目录的权限
23 path.logs: /tmp/elasticsearch/logs-node2
24 # 允许外部访问的端口
25 http.port: 8200
26 #-----------------单机和集群不变的配置------------------
27 bootstrap.memory_lock: false
28 # 解决启动异常:ERROR: bootstrap checks failed
29 bootstrap.system_call_filter: false
30 # 允许访问的ip 0.0.0.0表示允许所有
31 network.host: 0.0.0.0
32 # head插件跨域
33 http.cors.enabled: true
34 http.cors.allow-origin: "*"
如果一台机器内存不够,可以修改 es 的内存配置,例如这里可以将 master 内存改小一点
cd config
vi jvm.options
将 2G 改为 1G
-Xms1g
-Xmx1g
为了方便查看我将上面 es 的文件夹做了重命名,因此给 elasticsearch 重新授权
chown elasticsearch:elasticsearch -R /app/elasticsearch-node1
chown elasticsearch:elasticsearch -R /app/elasticsearch-node2
添加公作节点使用的外部端口
vi /etc/sysconfig/iptables
# 在打开的文件中加入如下内容
-A INPUT -p tcp -m state --state NEW -m tcp --dport 8200 -j ACCEPT
# 重启防火墙
service iptables restart
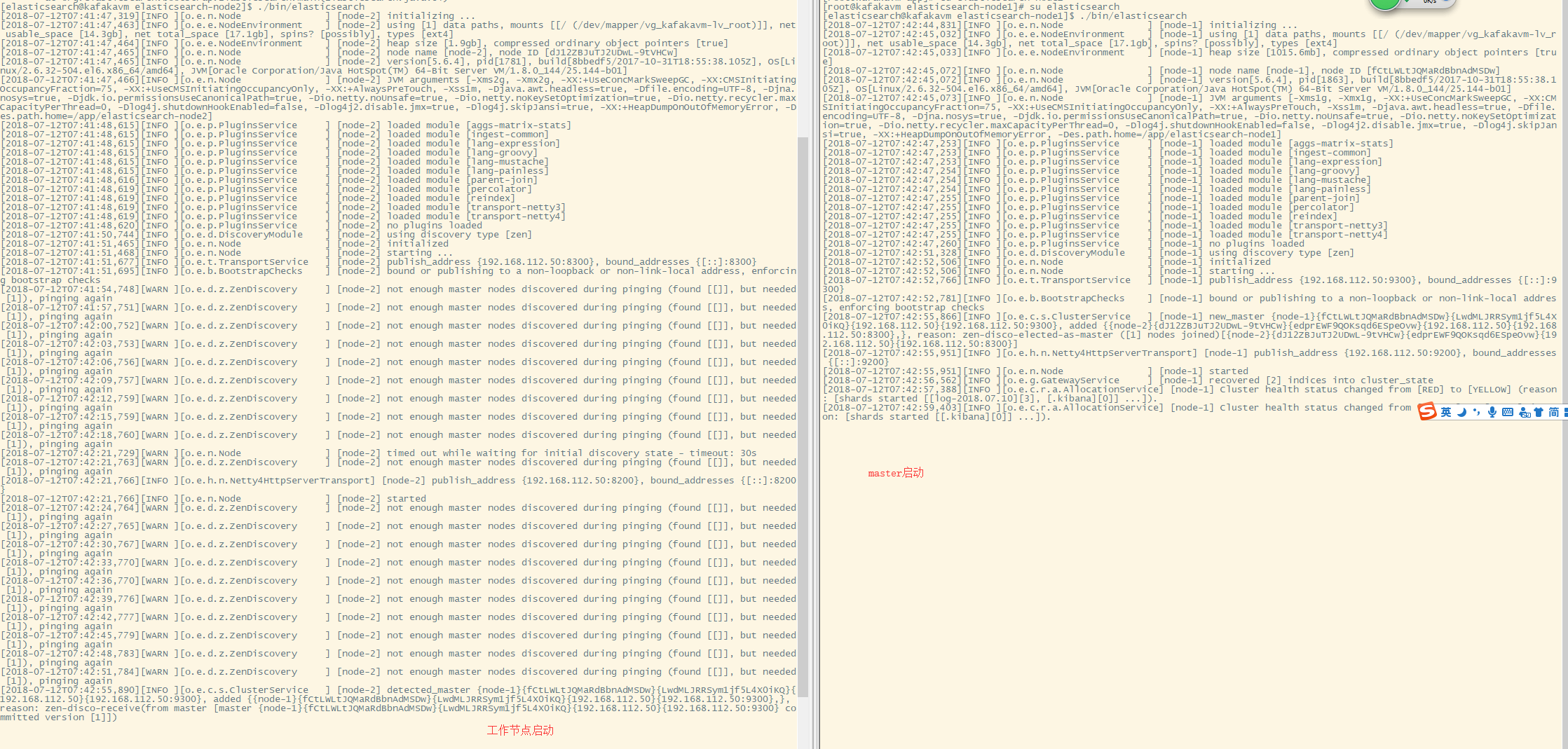
启动工作节点,在启动 master 节点
su elasticsearch
# 分别切换到两个es的安装目录,启动
./bin/elasticsearch
成功启动后控制台打印
启动 head 插件,在浏览器访问


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









