






 本文介绍了Python中数据存储的基本方法,包括使用文件进行简单的数据存储、利用json和pickle进行序列化与反序列化,以及使用shelve模块进行更为灵活的数据操作。
本文介绍了Python中数据存储的基本方法,包括使用文件进行简单的数据存储、利用json和pickle进行序列化与反序列化,以及使用shelve模块进行更为灵活的数据操作。
Python数据存取
一般的方式
写
[root@python3 day3]# cat test.py
#!/usr/local/python3/bin/python3
dic=str({'read':'book'})
f=open('test','w')
f.write(dic)
[root@python3 day3]# python3 test.py
[root@python3 day3]# ll
total 8
-rw-r--r-- 1 root root 16 Apr 7 16:01 test
-rw-r--r-- 1 root root 90 Apr 7 16:00 test.py
[root@python3 day3]# cat test
{'read': 'book'}[root@python3 day3]# 读
[root@python3 day3]# cat read.py
#!/usr/local/python3/bin/python3
f=open('test','r')
data=f.read()
print(data['read']) ##文件中的并不是字典,无法这样使用
[root@python3 day3]# python3 read.py
Traceback (most recent call last):
File "read.py", line 4, in <module>
print(data['read'])
TypeError: string indices must be integers
[root@python3 day3]# cat read.py
#!/usr/local/python3/bin/python3
f=open('test','r')
data=f.read()
print(eval(data)['read']) ##通过eval转换成字典来操作
[root@python3 day3]# python3 read.py
book
序列化的引入
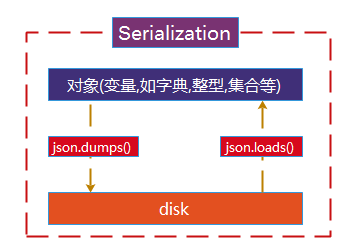
描述:我们把对象(变量,如字典,整型,集合等)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling, flattening等等.(使用write写到文本,不能把字典类型存储到磁盘上,所以需要一个序列化)
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling
json
描述:如果要在不同编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输.json不仅是标准格式,并且比XML更快,而且可以直接在web页面中读取,非常方便.
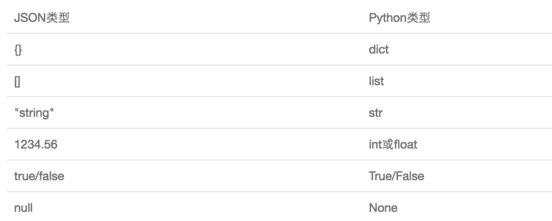
json表示的对象就是标准的Javascript语言对象,json和python内置的类型对应如下:
json两个方法dumps(加载进去)和load(加载回来)
序列化的过程
a.加载进去:通过转换成json的格式存入到磁盘
[root@python3 test1]# cat json_dumps.py
#!/usr/local/python3/bin/python3
import json
dic={'name':'reid','age':'20'}
data=json.dumps(dic) #转换,json.dumps(要转换的对象)
f=open('jsonfile','w')
f.write(data)
f.close
[root@python3 test1]# cat jsonfile
{"name": "reid", "age": "20"} ##是json自带的格式,并不了字典b. 取数据:(通过loads方法把json格式从文本中取出原来对象的类型)
[root@python3 test1]# cat json_loads.py
#!/usr/local/python3/bin/python3
import json
f=open('jsonfile','r')
data=f.read()
data=json.loads(data) ##使用loads方法加载回来
print(data['name'])
[root@python3 test1]# python3 json_loads.py
reid
json的dump和load方法
dump
[root@python3 json_dump_load]# vim json_dump.py
#!/usr/local/python3/bin/python3
import json
dic={'name':'reid','age':'19'}
import json
dic={'name':'reid','age':'19'}
f=open('json_test','w')
#data=json.dumps(dic) ##这两行是做一个序列化,再把结果写入文本
#f.write(data)
json.dump(dic,f) #第一个参数是要转入的对象,第二个参数是文件句柄,这行代码相当于上两行
f.close
[root@python3 json_dump_load]# python3 json_dump.py
[root@python3 json_dump_load]# cat json_test
{"name": "reid", "age": "19"}[root@python3 json_dump_load]# load
[root@python3 json_dump_load]# cat json_load.py
#!/usr/local/python3/bin/python3
import json
f=open('json_test','r')
#data=f.read()
#data=json.loads(data)
data=json.load(f) #直接写参数f
print(data['name'])
[root@python3 json_dump_load]# python3 json_load.py
reid
pickle的引入
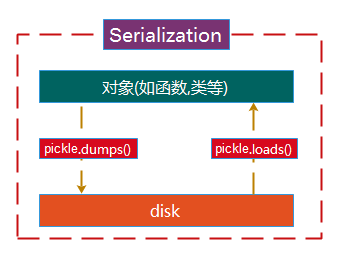
场景:json无法做更高级的转换,如函数和类
[root@python3 function]# cat json_not_fuc.py
#!/usr/local/python3/bin/python3
import json
def f():
print('function')
data=json.dumps(f) ####json转换
[root@python3 function]# python3 json_not_fuc.py
Traceback (most recent call last):
TypeError: Object of type 'function' is not JSON serializable使用pickle操作
写入
[root@python3 pickledir]# cat pickletest.py
#!/usr/local/python3/bin/python3
import pickle
def f():
print('function')
data=pickle.dumps(f)
filepickle=open('pickle_test','wb') ##写进去的要是字节类型,也就是字串,b是字节,不加默认是写入string
filepickle.write(data)
filepickle.close()
[root@python3 pickledir]# python3 pickletest.py
[root@python3 pickledir]# cat pickle_test
c__main__ ##pickle的显示方式
f取出
描述:使用pickle序列化一个函数对象,如函数为f,它指向一块内存地址,生成pickle_test的文本可以传输给其他的电脑使用,但是在其他电脑取出来的是只是一个变量,因为内存地址在原本的电脑上,可能够调用就要两个电脑都有公共的部分函数f
[root@python3 pickledir]# cat pickle_loads.py
#!/usr/local/python3/bin/python3
import pickle
f=open('pickle_test','rb')
data=f.read()
data=pickle.loads(data)
data()
[root@python3 pickledir]# python3 pickle_loads.py
Traceback (most recent call last):
File "pickle_loads.py", line 6, in <module>
data()
TypeError: '_io.BufferedReader' object is not callable ##调用时,内存地址已经发生变化 公共的部分加入
[root@python3 pickledir]# cat pickle_loads.py
#!/usr/local/python3/bin/python3
import pickle
def f(): ##
print('function') ##
filep=open('pickle_test','rb')
data=filep.read()
data=pickle.loads(data)
data()
[root@python3 pickledir]# python3 pickle_loads.py
shelve模块
描述:shelve模块比pickle模块简单,只有 只有一个open函数,返回类似字典的对象,可读可写,key必须为字符串,而值可以是python所支持的数据类型.json和pickle中的方法对于修改上不灵活,而shelve弥补了这点.
存值
[root@python3 shelve]# cat shelve_test.py
#!/usr/local/python3/bin/python3
import shelve
f=shelve.open('test') #可以加上r,正则中保持原生的字符串,避免一些错误
f['info']={'name':'tom','hobby':'running'}
[root@python3 shelve]# ll
total 16
-rw-r--r-- 1 root root 115 Apr 7 21:00 shelve_test.py
-rw-r--r-- 1 root root 16 Apr 7 21:01 test.bak
-rw-r--r-- 1 root root 55 Apr 7 21:01 test.dat
-rw-r--r-- 1 root root 16 Apr 7 21:01 test.dir取值
[root@python3 shelve]# cat shelve_test.py
#!/usr/local/python3/bin/python3
import shelve
f=shelve.open('test')
#f['info']={'name':'tom','hobby':'running'}
data=f.get('info')
print(data)
[root@python3 shelve]# python3 shelve_test.py
{'name': 'tom', 'hobby': 'running'}
字典对象中get方法的使用
In [1]: d={'name':'jerry','hobby':'jogging'}
In [2]: d['name']
Out[2]: 'jerry'
In [3]: d.get('name') ###
Out[3]: 'jerry'
In [4]: d.get('sex','male') #sex是没有,然后返回一个male
Out[4]: 'male'

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









