



 该博客围绕中文长篇小说文本分析作业展开,包括从文件读取待分析文本,安装jieba,更新词库、生成词频统计、排序、排除停用词并输出词频最大TOP20保存到文件,最后生成词云,还给出了作业要求和参考链接。
该博客围绕中文长篇小说文本分析作业展开,包括从文件读取待分析文本,安装jieba,更新词库、生成词频统计、排序、排除停用词并输出词频最大TOP20保存到文件,最后生成词云,还给出了作业要求和参考链接。
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2773
一.下载一篇中文长篇小说并从文件中读取待分析文本
f = open('xiaoshuo.txt', 'r', encoding='utf-8')
# 通过文件读取字符串 str
str = f.read()
f.close()
print(str)
二.安装jieba

三.
(1)更新词库,加入所分析对象的专业词汇。
(2)生成词频统计
(3)排序
(4)排除语法型词汇,代词、冠词、连词等停用词。
(5)输出词频最大TOP20,把结果存放到文件里
import jieba
f=open('白夜行.txt','r',encoding='utf-8')
lines=f.read()
f.close()
sep = ',。?!;:“”‘’-——<_/>'
for en in sep:
lines=lines.replace(en, '')
lines = list(jieba.cut_for_search(lines)) strSet = set(lines) #print(len(strSet), strSet) strDict = dict() for word in strSet: strDict[word] = lines.count(word) #print(len(strDict), strDict) wcList = list(strDict.items()) #print(wcList) wcList.sort(key=lambda x: x[1], reverse=True) #print(wcList) for i in range(20): print(wcList[i])

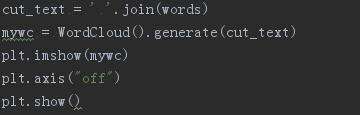
四.生成词云

















 2390
2390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









