




 本文详细介绍了使用Hadoop进行大数据处理的过程,包括对爬虫获取的Python岗位CSV数据进行预处理,删除重复值和无效数据,然后上传到HDFS,再导入到Hive数据仓库进行多维度的分析,如城市、工作年限和学历等需求分布。
本文详细介绍了使用Hadoop进行大数据处理的过程,包括对爬虫获取的Python岗位CSV数据进行预处理,删除重复值和无效数据,然后上传到HDFS,再导入到Hive数据仓库进行多维度的分析,如城市、工作年限和学历等需求分布。
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
前言
本次作业是在《爬虫大作业》的基础上进行的,在《爬虫大作业》中,我主要对拉勾网python岗位的招聘信息进行的数据爬取,最终得到了2641条数据存在一个名为lagoupy.xls中。本次作业的任务主要有以下三点:
1.对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
2.把hdfs中的文本文件最终导入到数据仓库Hive中,在Hive中查看并分析数据
3.用Hive对爬虫大作业产生的进行数据分析(10条以上的查询分析)
数据预处理
由于我们爬取下来的数据并不是全部都是我们所要的,或者是有一些数据需要进行加工才可以用到,这时候数据的预处理就必不可少了,原始的数据如下图所示。

1.删除重复值
如果数据中存在重复记录, 而且重复数量较多时, 势必会对结果造成影响, 因此我们应当首先处理重复值。打开lagoupy.xls文件,选中岗位id这一列数据,选择数据——>删除重复值,对重复值进行删除,删除重复值后,我们可以发现,数据从原来的2641条变成2545条。
2.过滤无效数据
由于某些数据对我们的数据分析并无用处,所以对于这一部分数据我们可以不要,在这里发布时间是无效数据,所以我们可以直接删除这一列。
3.添加序号
由于我们的数据是要存进数据库的,所以在这里我添加了序号这一列,给我们的数据进行编号,以便于后期我们对数据的分析。此外,为了方便后续的工作,我在这里将文件另存为csv格式,需要注意的是:在保存类型中我们选择CSV UTF-8(逗号分隔)。
经过上述几个步骤后,我们最终可以得到一个经过数据预处理的csv文件,如下图所示。

大数据分析
1.对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
首先,我们需要在本地中创建一个/usr/local/bigdatacase/dataset文件夹,具体的步骤为:
① cd /usr/local
② sudo mkdir bigdatacase
③ cd bigdatacase/
④ sudo mkdir dataset
⑤ cd dataset/
如下图所示:

其次,我们把lagoupy.csv文件放到下载这个文件夹中,并使用命令把lagoupy.csv文件拷贝到我们刚刚所创建的文件夹中,具体步骤如下:
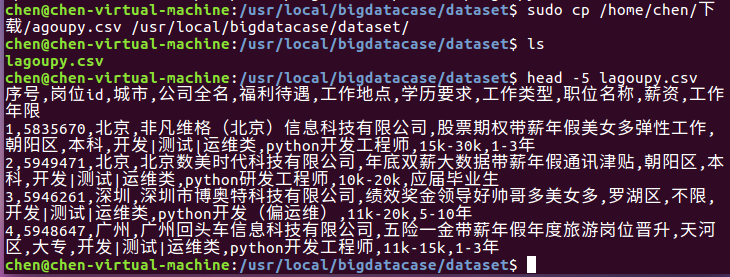
① sudo cp /home/chen/下载/lagoupy.csv /usr/local/bigdatacase/dataset/ #把lagoupy.csv文件拷到刚刚所创建的文件夹中
② head -5 lagoupy.csv #查看这个文件的前五行
如下图所示:
对CSV文件进行预处理生成无标题文本文件,步骤如下:
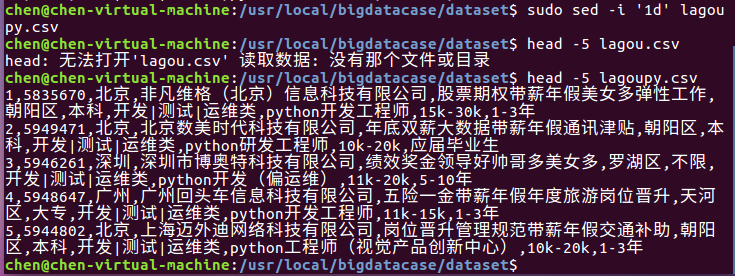
① sudo sed -i '1d' lagoupy.csv #删除第一行记录
② head -5 lagoupy.csv #查看前五行记录
如下图所示:
接着,启动hadoop,步骤如下:
① start-all.sh #启动hadoop
② jps #查看hadoop是否启动成功
如下图所示:

最后,我们把本地的文件上传至HDFS中,步骤如下:
① hdfs dfs -mkdir -p /bigdatacase/dataset #在hdfs上新建/bigdatacase/dataset
② hdfs dfs -ls /
③ hdfs dfs -put ./lagoupy.csv /bigdatacase/dataset #把本地文件lagoupy.csv上传至hdfs中
④ hdfs dfs -ls /bigdatacase/dataset #查看
⑤ hdfs dfs -cat /bigdatacase/dataset/lagoupy.csv | head -5 #查看hdfs中lagoupy.csv的前
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2651
2651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









