






 本文深入解析word2vec,包括其工作原理、与n-gram模型的对比、词向量的生成方式,以及CBOW和Skip-Gram两种模型的运作机制。同时介绍了word2vec如何通过霍夫曼树和Hierarchical softmax优化传统神经网络,实现高效计算。
本文深入解析word2vec,包括其工作原理、与n-gram模型的对比、词向量的生成方式,以及CBOW和Skip-Gram两种模型的运作机制。同时介绍了word2vec如何通过霍夫曼树和Hierarchical softmax优化传统神经网络,实现高效计算。
word2vec是google在2013年推出的NLP工具,特点是将所有的词向量化,这样词与词之间就可以定量地度量 它们之间的关系,挖掘之间的联系。
与n-gram模型相比,神经概率语言模型有什么优势呢?
- 词语之间的相似性可以通过词向量来体现
比如:在某个语料库中 s1 = "A dog is running in the room"出现了10000次, s2="A cat is running in the room"只出现了一次,按照n-gram, p(s1)肯定远大于p(s2),由神经概率语言模型算得的p(s1)和p(s2)是大致相等的。原因在于:(1)在神经概率语言模型中假定了“相似的”词对应的词向量也是相似的(2)概率函数关于词向量是光滑的,即词向量中的一个小变化对概率的影响也只是一个小变化 - 基于词向量的模型自带平滑化功能,p(w|context(w)) 为0时
词向量
- one-hot representation
就是用一个很长的向量来表示一个词,向量的长度为词典的大小N,向量的分量只有一个1,其他全为0,1的位置对应该词在词典中的索引。(缺点:容易导致维数灾难) - Distributed representation
通过训练将某种语言中的某一个词映射成一个固定长度的短向量。所有这些词向量构成词向量空间,而每一个向量则视为该空间的一个点,在这个空间引入“距离”
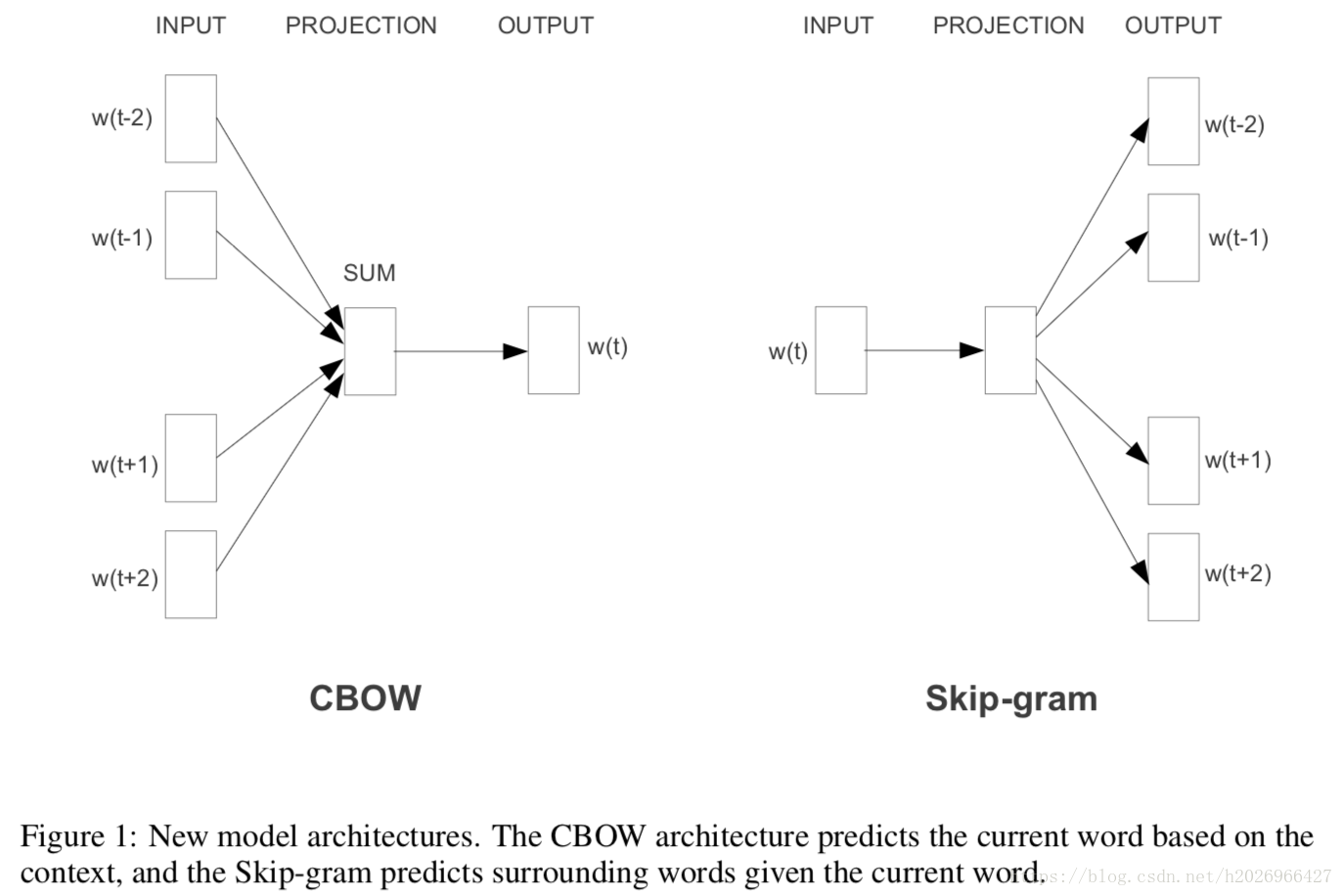
1. CBOW(输出中心词)
CBOW(continus bag of words)模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量
我们上下文大小取值为4,特定的这个词是"learning",也就是我们需要的输出词向量,上下文对应的词有8个,前后各4个,这8个词是我们模型的输入。由于CBOW使用的是词袋模型,因此这8个词都是平等的,也就是与关注的词之间的距离无关,只要在上下文之内即可。这样我们这个CBOW的例子里,我们的输入是8个词向量,输出是所有词的softmax概率(训练的目标是期望训练样本特定词对应的softmax概率最大),对应的CBOW神经网络模型输入层有8个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某8个词对应的最可能的输出中心词时,我们可以通过一次DNN前向传播算法并通过softmax激活函数找到概率最大的词对应的神经元即可
2. Skip-Gram(输出上下文词)
输入是特定一个词的词向量,而输出是特定词对应的上下文词向量。与CBOW相反
CBOW通常适用于小型数据,而Skip-gram在大型预料中表现更好,两个模型结构如图:
3. 霍夫曼树
霍夫曼树是word2vec的基础, word2vec使用了CBOW和Skip-Gram来训练模型,得到词向量,但没有使用传统的DNN模型。最先优化使用的数据结构是霍夫曼树来代替隐藏层和输出层的神经元,霍夫曼树的叶子节点起到输出层神经元的作用,叶子节点即为词汇表的大小,而内部节点则为起到隐藏层神经元的作用。
带权路径长度:若为树中节点赋予一个具有某种含义的(非负)数值,则这个数值称为该节点的权。集诶大拿的带权路径长度是指,从跟节点到该节点之间的路径长度与该节点的权的乘积
树的带权路径长度:树的带权路径长度规定为所有叶子节点的带权路径长度之和
给定n个权值作为n个叶子节点的权,构造一棵二叉树,,若它的带权路径长度达到最小,则这样的二叉树为最优二叉树,也称Huffman树(节点个数为n-1)。
霍夫曼树的建立过程:
输入:权值为(w_1,w_2,...w_n)的N个节点
输出:对应的霍夫曼树
1)将(w_1,w_2,...w_n)看作是n棵树的森林,每个树仅有一个节点
2)在森林中选择根节点权值最小的两棵树进行合并,得到一个新的树,这两颗树分别作为新树的左右子树。新树的根节点权重为左右子树的根节点权重之和
3)将之前的根节点权值最小的两棵树从森林删除,并把新树加入森林
4)重复步骤2)和3)直到森林只有一棵树为止
注意:二叉树的两个子树是分左右的,并且将权值大的节点作为左子树的节点
那么霍夫曼树有什么好处呢?一般得到霍夫曼树后我们会对叶子节点进行霍夫曼编码,由于权重高的叶子节点越靠近根节点,而权重低的叶子节点会远离根节点,这样我们的高权重节点编码值较短,而低权重值编码值较长。这保证的树的带权路径最短
4. word2vec改进传统的神经网络:基于Hierarchical softmax 和基于Negative Sampling
4.1 基于Hierarchical softmax
应用传统的神经网络最大的问题在于从隐藏层到输出层的softmax的计算量很大,因为要计算所有词的softmax概率,再去找概率最大的值。word2vec对此作出了改进
- 对于从输入层到隐藏层的映射,没有采取神经网络的线性变换加激活函数的方法,而是采用简单的对所有输入词向量求和并取平均的方法
- 从隐藏层到输出的softmax层。为了避免要计算所有词的softmax,word2vec采用了霍夫曼树来代替从隐藏层到输出softmax层的映射。
缺点: 如果我们的训练样本里的中心词w是一个很生僻的词,那么就得在霍夫曼树中辛苦的向下走很久
- 4.2 基于Negative Sampling
Negative Sampling由于没有采用霍夫曼树,每次只是通过采样neg个不同的中心词做负例,就可以训练模型
参考:
1. https://blog.youkuaiyun.com/h2026966427/article/details/80368320
2. word2vec-中的数学原理详解

















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









