






 本文深入探讨MapReduce框架的高级应用,包括自定义排序、TopK算法、自定义分区函数、数据去重、输入格式选择、MapReduce中的Join操作以及小文件合并策略。通过具体实例,解析各种场景下技术细节与最佳实践。
本文深入探讨MapReduce框架的高级应用,包括自定义排序、TopK算法、自定义分区函数、数据去重、输入格式选择、MapReduce中的Join操作以及小文件合并策略。通过具体实例,解析各种场景下技术细节与最佳实践。
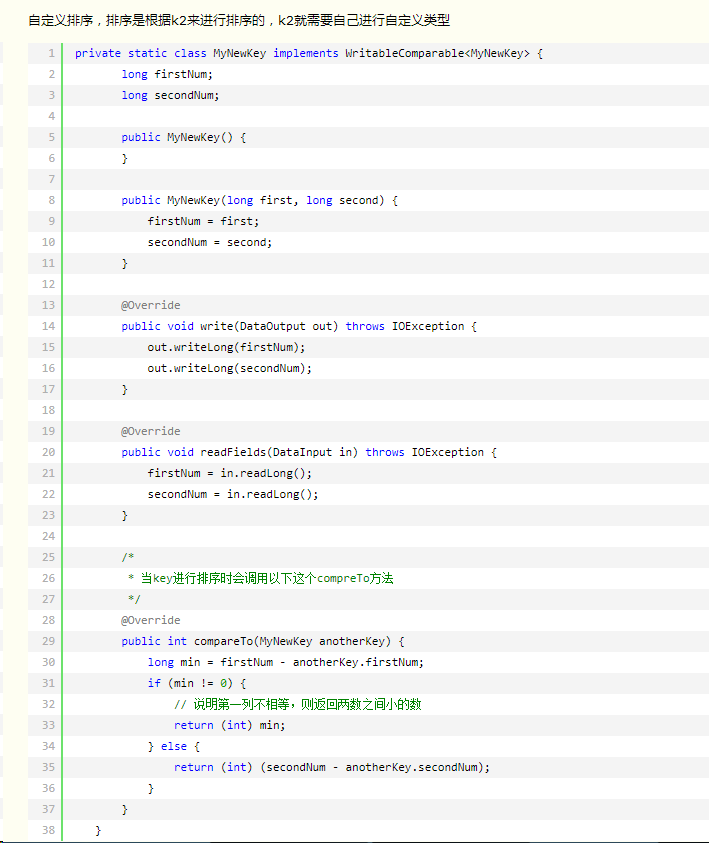
①自定义按某列排序,二次排序
writablecomparable中的compareto方法
②topk
a利用treemap,缺点:map中的key不允许重复:https://blog.youkuaiyun.com/u010660276/article/details/50967054
b封装mapper<key,value>中的key实现writablecompareable接口,实现排序https://blog.youkuaiyun.com/lzm1340458776/article/details/43228191
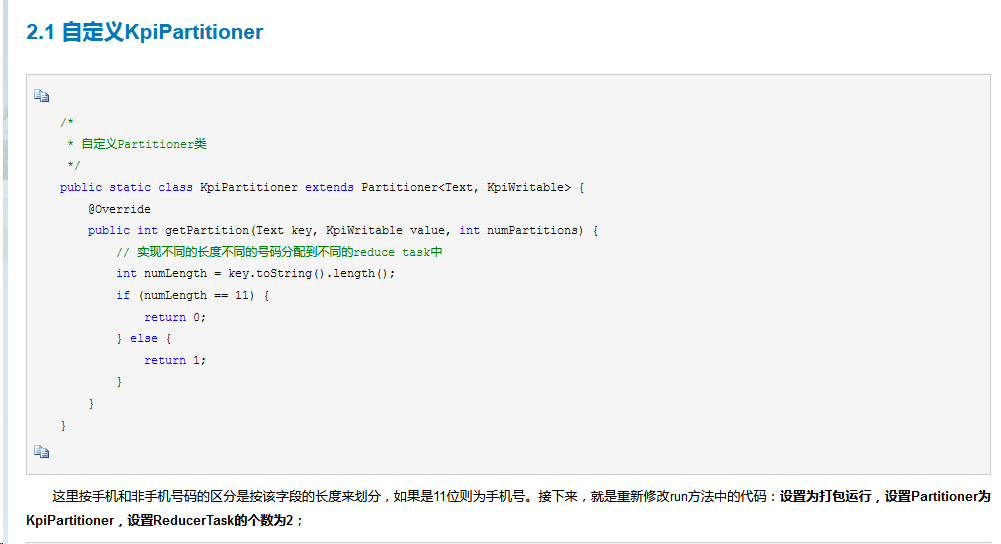
③自定义分区函数:实现按省份输出信息
分区的目的:将相同的key值放到一个reduce中处理,将reduce处理完的数据按key分别存到不同的文件中
④数据去重
由于在map阶段之后会将相同key的value分组,分组之后的每一个key都是唯一的,消除数据去重时可以将数据直接作为map的key然后输出,map之后就会是唯一的,在reduce阶段直接输出就可。
⑤常用的输入格式:https://blog.youkuaiyun.com/u011812294/article/details/63262624
⑥mapreduce中的join:map端join和reduce端join(将需要连接操作的表同时或者选择小的加载到内存中)
map端join和reduce端join举例:https://blog.youkuaiyun.com/litianxiang_kaola/article/details/71598632
https://blog.youkuaiyun.com/guxin0729/article/details/84035513
map端join:在map的setup()中将小的表加入hashmap中,(指定小表path将表存入话说hashmap中)(在setup中读取小文件)
map()中实现读取一行将条件去匹配hashmap中的值,构造join表类
在main()中只需要指定inputmapperpath为map()中需要读取的大文件即可
reduce端join:mapper中将条件作为key,join的类为value
reducer中创建ArrayList,然后实现join
两者的对比:https://blog.youkuaiyun.com/weixin_39979119/article/details/85041438
如何选择:
reduce端join,当两个文件的大小差距较大时,会产生数据倾斜,在reducer中需要结合List
map端join,仅适用于大小表或者小小表关联
⑦小文件合并

















 9253
9253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









