



一、Python函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
面向对象:对函数进行分类和封装,让开发“更快更好更强...”
注:函数式编程最重要的是增强代码的重用性和可读性
二、定义一个函数
1、你可以定义一个由自己想要功能的函数,以下是简单的规则:
①、函数代码块以def关键词开头,后接函数标识符名称和圆括号()。
②、任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
③、函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
④、函数内容以冒号起始,并且缩进。
⑤、Return[expression]结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
2、语法
|
1
2
3
4
|
def
functionname( parameters ):
"函数_文档字符串"
function_suite
return
[expression]
|
默认情况下,参数值和参数名称是按函数声明中定义的的顺序匹配起来的。
3、实例
|
1
2
3
4
|
def
printme():
name
=
'hetan'
print
(name)
return
|
三、函数调用
定义一个函数只给了函数一个名称,指定了函数里包含的参数,和代码块结构。
这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从Python提示符执行。
如下实例调用了printme()函数:
|
1
2
3
4
5
6
7
|
def
printme():
name
=
'hetan'
print
(name)
return
printme()
f
=
printme
f()
|
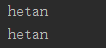
注:函数名也可以赋值,赋值后的变量也可以用词函数
四、函数的参数
以下是调用函数时可使用的正式参数类型:
①、必备参数
②、命名参数
③、缺省参数
④、不定长参数
1、必备参数
必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
|
1
2
3
4
5
|
def
printme(name):
name
=
name
print
(name)
return
printme(
'hetan'
)
|

调用printme()函数,你必须传入一个参数,不然会出现语法错误:
|
1
2
3
4
|
def
printme(name):
print
(name)
return
printme()
|

2、命名参数
命名参数和函数调用关系紧密,调用方用参数的命名确定传入的参数值。你可以跳过不传的参数或者乱序传参,因为Python解释器能够用参数名匹配参数值。用命名参数调用printme()函数:
|
1
2
3
4
|
def
printme(name,age):
print
(name,age)
return
printme(age
=
25
,name
=
'hetan'
)
|
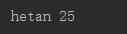
3、缺省参数
调用函数时,缺省参数的值如果没有传入,则被认为是默认值。下例会打印默认的age,如果age没有被传入:
|
1
2
3
4
5
|
def
printme(name,age
=
25
):
print
(name,age)
return
printme(age
=
35
,name
=
'hetan'
)
printme(name
=
'hetan'
)
|
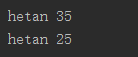
4、不定长参数
①、序列
|
1
2
3
|
def
show(
*
args):
print
(args)
show(
11
,
12
,
13
)
|
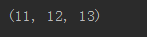
②、字典
|
1
2
3
|
def
show1(
*
*
kwargs):
print
(kwargs)
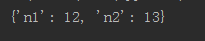
show1(n1
=
12
,n2
=
13
)
|
③、序列和字典
|
1
2
3
4
|
def
show2(
*
args,
*
*
kwargs):
print
(args,
type
(args))
print
(kwargs,
type
(kwargs))
show2(
11
,
22
,
33
,n3
=
12
,n4
=
15
)
|

五、内置函数
1、abs()绝对值函数
|
1
2
|
print
(
abs
(
-
1
))
print
(
abs
(
1
))
|

2、all()集合中的元素都为真的时候为真,特别的,若为空串返回为True。
|
1
2
3
4
5
6
|
li
=
[
'name'
,
'age'
]
li1
=
[]
li2
=
[
'name'
,[]]
print
(
all
(li))
print
(
all
(li1))
print
(
all
(li2))
|

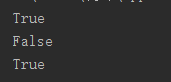
3、any()集合中的元素有一个为真的时候为真,特别的,若为空串返回为False。
|
1
2
3
4
5
6
|
li
=
[
'name'
,
'age'
]
li1
=
[]
li2
=
[
'name'
,[]]
print
(
any
(li))
print
(
any
(li1))
print
(
any
(li2))
|
4、chr()返回整数对应的ASCII字符
ord()返回字符对应的ASC码数字编号
|
1
2
|
print
(
chr
(
65
))
print
(
ord
(
'A'
))
|

5、bin(x)将整数x转换为二进制字符串
|
1
|
print
(
bin
(
10
))
|

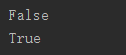
6、bool(x)返回x的布尔值
|
1
2
|
print
(
bool
(
0
))
print
(
bool
(
1
))
|
7、dir()不带参数时,返回当前范围内的变量、方法和定义的类型列表,带参数时,返回参数的属性、方法列表。
|
1
2
|
print
(
dir
())
print
(
dir
(
list
))
|

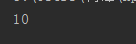
8、divmod()分别取商和余数
|
1
|
print
(
divmod
(
10
,
3
))
|

9、enumerate()返回一个可枚举的对象,该对象的next()方法将返回一个tuple
|
1
2
3
|
name
=
[
'hetan'
,
'liuyao'
,
'wudonghang'
]
for
i,j
in
enumerate
(name,
1
):
print
(i,j)
|

10、eval()将字符串str当成有效的表达式来求值并返回计算结果。
|
1
2
3
|
name
=
'[[1,2], [3,4], [5,6], [7,8], [9,0]]'
a
=
eval
(name)
print
(a)
|

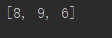
11、filter(function, iterable)函数可以对序列做过滤处理,就是说可以使用一个自定的函数过滤一个序列,把序列的每一项传到自定义的过滤函数里处理,并返回结果做过滤。最终一次性返回过滤后的结果。参数function:返回值为True或False的函数,可以为None,参数iterable:序列或可迭代对象。
|
1
2
3
4
5
6
|
def
guolvhanshu(num):
if
num>
5
and
num<
10
:
return
num
seq
=
(
12
,
50
,
8
,
17
,
65
,
14
,
9
,
6
,
14
,
5
)
result
=
filter
(guolvhanshu,seq)
print
(
list
(result))
|
12、hex(x)将整数x转换为16进制字符串。
|
1
|
print
(
hex
(
20
))
|

13、id()返回对象的内存地址
|
1
|
print
(
id
(
'hetan'
))
|

14、len()返回对象的长度
|
1
2
|
seq
=
(
12
,
50
,
8
,
17
,
65
,
14
,
9
,
6
,
14
,
5
)
print
(
len
(seq))
|
15、map(function, iterable)遍历每个元素,执行function操作
|
1
2
3
4
5
6
|
def
guolvhanshu(num):
num
=
num
+
100
return
num
seq
=
(
12
,
50
,
8
,
17
,
65
,
14
,
9
,
6
,
14
,
5
)
result
=
map
(guolvhanshu,seq)
print
(
list
(result))
|

16、oct()八进制转换
|
1
|
print
(
oct
(
87
))
|

17、range()产生一个序列,默认从0开始
|
1
|
print
(
list
(
range
(
10
)))
|

18、reversed()反转
|
1
2
3
4
|
li
=
list
(
range
(
10
))
li1
=
reversed
(li)
print
(li)
print
(
list
(li1))
|

19、round()四舍五入
|
1
2
|
print
(
round
(
4.6
))
print
(
round
(
4.5
))
|

20、sorted()队集合排序
|
1
2
|
seq
=
(
12
,
50
,
8
,
17
,
65
,
14
,
9
,
6
,
14
,
5
)
print
(
sorted
(seq))
|

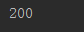
21、sum()对集合求和
|
1
2
|
seq
=
(
12
,
50
,
8
,
17
,
65
,
14
,
9
,
6
,
14
,
5
)
print
(
sum
(seq))
|
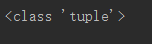
22、type()返回该object的类型
|
1
2
|
seq
=
(
12
,
50
,
8
,
17
,
65
,
14
,
9
,
6
,
14
,
5
)
print
(
type
(seq))
|
23、vars()返回对象的变量,若无参数与dict()方法类似。
|
1
2
|
print
(
vars
())
print
(
vars
(
list
))
|
运行结果太多,就不展示了
24、zip()zip函数接受任意多个(包括0个和1个)序列作为参数,返回一个tuple列表。具体意思不好用文字来表述,直接看示例:
示例1:
|
1
2
3
4
5
|
x
=
[
1
,
2
,
3
]
y
=
[
4
,
5
,
6
]
z
=
[
7
,
8
,
9
]
xyz
=
zip
(x, y, z)
print
(x,y,z)
|

示例2:
|
1
2
3
4
|
x
=
[
1
,
2
,
3
]
y
=
[
4
,
5
,
6
,
7
]
xy
=
zip
(x, y)
print
(
list
(xy))
|

示例3:
|
1
2
3
4
5
6
|
x
=
[
1
,
2
,
3
]
y
=
[
4
,
5
,
6
]
z
=
[
7
,
8
,
9
]
xyz
=
zip
(x, y, z)
u
=
zip
(
*
xyz)
print
(
list
(u))
|

一般认为这是一个unzip的过程,它的运行机制是这样的:
在运行zip(*xyz)之前,xyz的值是:[(1, 4, 7), (2, 5, 8), (3, 6, 9)]
那么,zip(*xyz) 等价于 zip((1, 4, 7), (2, 5, 8), (3, 6, 9))
所以,运行结果是:[(1, 2, 3), (4, 5, 6), (7, 8, 9)]
注:在函数调用中使用*list/tuple的方式表示将list/tuple分开,作为位置参数传递给对应函数(前提是对应函数支持不定个数的位置参数)
示例4:
|
1
2
3
|
x
=
[
1
,
2
,
3
]
r
=
zip
(
*
[x]
*
3
)
print
(
list
(r))
|

示例5:
它的运行机制是这样的:
[x]生成一个列表的列表,它只有一个元素x
[x] * 3生成一个列表的列表,它有3个元素,[x, x, x]
zip(* [x] * 3)的意思就明确了,zip(x, x, x)
六、open函数
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的辅助方法才可以调用它进行读写。
①、打开文件
语法:文件句柄 = open('文件路径','模式')
读写模式的类型有:
rU 或 Ua 以读方式打开, 同时提供通用换行符支持 (PEP 278)
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+ 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
注:1、使用'W',文件若存在,首先要清空,然后(重新)创建
2、使用'a'模式 ,把所有要写入文件的数据都追加到文件的末尾,即使你使用了seek()指向文件的其他地方,如果文件不存在,将自动被创建。
②、文件操作
1、close()关闭文件
2、fileno()文件描述符
3、flush()刷新文件内部缓冲区
4、isatty()判断文件是否是同意tty设备
5、next()获取下一行数据,不存在,则报错。
6、read()读取指定字符数据
|
1
2
3
4
|
f
=
open
(
'test.log'
,
'r'
,encoding
=
'utf-8'
)
ret
=
f.read(
3
)
f.close()
print
(ret)
|

7、readinto()读取到缓冲区,不要用,3.x将被遗弃
8、readline()仅读取一行数据
|
1
2
3
4
|
f
=
open
(
'test.log'
,
'r'
,encoding
=
'utf-8'
)
ret
=
f.readline()
f.close()
print
(ret)
|

9、readlines()读取所有数据,并根据换行保存至列表
|
1
2
3
4
|
f
=
open
(
'test.log'
,
'r'
,encoding
=
'utf-8'
)
ret
=
f.readlines()
f.close()
print
(ret)
|

10、seek()指定文件中指针位置,按字节移动
|
1
2
3
4
5
|
f
=
open
(
'test.log'
,
'r'
,encoding
=
'utf-8'
)
f.seek(
5
)
ret
=
f.readlines()
f.close()
print
(ret)
|

11、tell()获取当前指针位置,按字节显示
|
1
2
3
4
5
6
7
|
f
=
open
(
'test.log'
,
'r'
,encoding
=
'utf-8'
)
f.seek(
5
)
print
(f.tell())
ret
=
f.readlines()
print
(f.tell())
f.close()
print
(ret)
|

12、truncate()截断数据,仅保留指定之前的数据。
|
1
2
3
4
5
6
7
|
f
=
open
(
'test.log'
,
'r+'
,encoding
=
'utf-8'
)
print
(f.readlines())
f.seek(
0
)
f.truncate(
5
)
ret
=
f.readline()
f.close()
print
(ret)
|

13、write()写操作
|
1
2
3
4
5
6
|
f
=
open
(
'test.log'
,
'r+'
,encoding
=
'utf-8'
)
print
(f.readlines())
f.write(
'asdasfasf'
)
f.seek(
0
)
print
(f.readlines())
f.close()
|

14、writelines()将一个字符串列表写入文件,3.x将弃用。
15、xreadlines()可用于逐行读取文件,非全部,3.x将弃用。
3、管理上下文
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
|
1
2
|
with
open
(
'test.log'
,
'r'
,encoding
=
'utf-8'
) as f:
print
(f.readlines())
|

如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
|
1
2
|
with
open
(
'test.log1'
) as f1,
open
(
'test.log2'
) as f2:
pass
|
七、lambda表达式
学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即:
|
1
2
3
4
5
6
7
|
if
1
=
=
1
:
name
=
'hetan'
else
:
name
=
'liuyao'
print
(name)
name
=
'hetan'
if
1
=
=
1
else
'liuyao'
print
(name)
|

对于简单的函数,也存在一种简便的表示方式,即:lambda表达式
|
1
2
3
4
5
|
def
func(arg):
return
arg
+
1
print
(func(
123
))
func1
=
lambda
arg:arg
+
1
print
(func1(
123
))
|


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









