 Python数据处理与Hadoop/Hive数据分析
Python数据处理与Hadoop/Hive数据分析







 该博客介绍了一系列数据处理与分析操作。先将Python爬取的数据传到Linux,制作预处理脚本,替换数据中的逗号。接着启动Hadoop集群和Hive,将数据上传到HDFS并导入表中。还进行了多项统计,如评论条数、好评率、特定角色出现频率及不同城市评论数等。
该博客介绍了一系列数据处理与分析操作。先将Python爬取的数据传到Linux,制作预处理脚本,替换数据中的逗号。接着启动Hadoop集群和Hive,将数据上传到HDFS并导入表中。还进行了多项统计,如评论条数、好评率、特定角色出现频率及不同城市评论数等。
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
1、把python爬取的数据传到linux
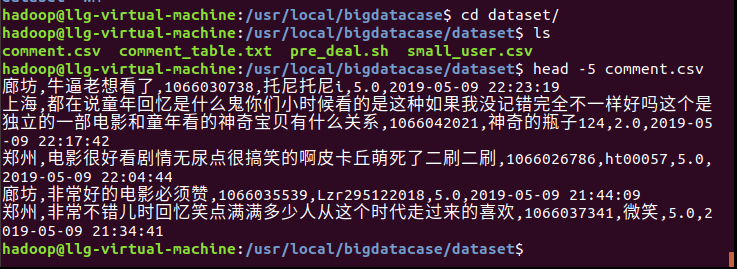
2.制作预处理脚本
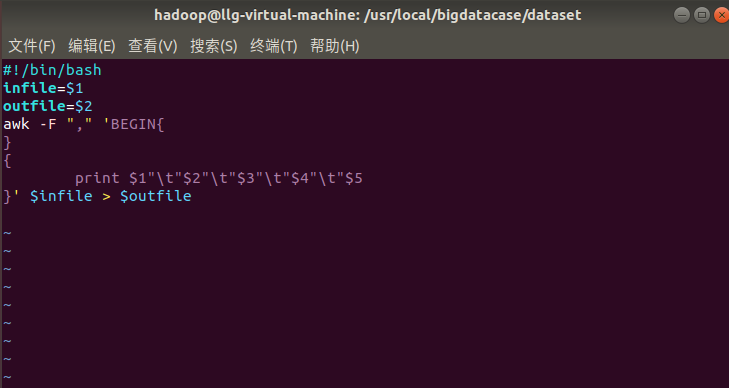
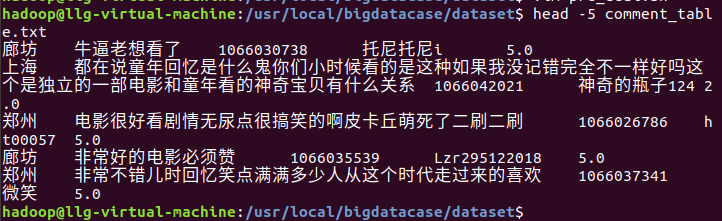
3、把数据的逗号代替为 \t转义字符
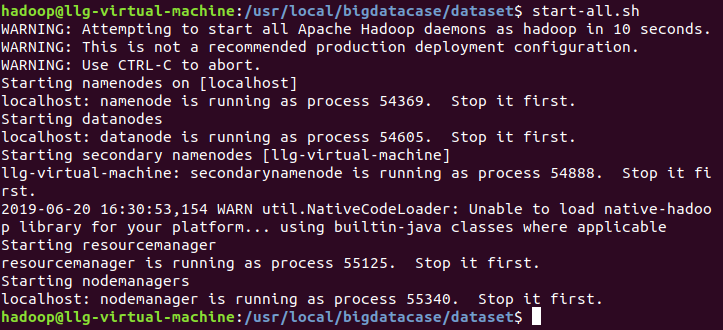
4、启动hadoop集群
5、把数据文件上传到hdfs
6、启动hive
7、使用bdlab数据库

8、创建表并把hdfs的数据导入表中

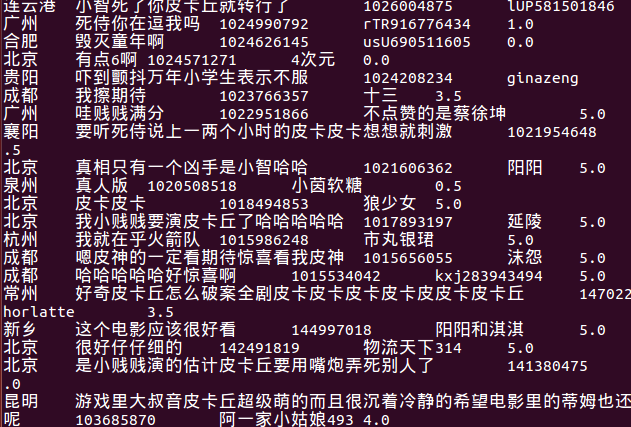
9、统计数据一共有105989条
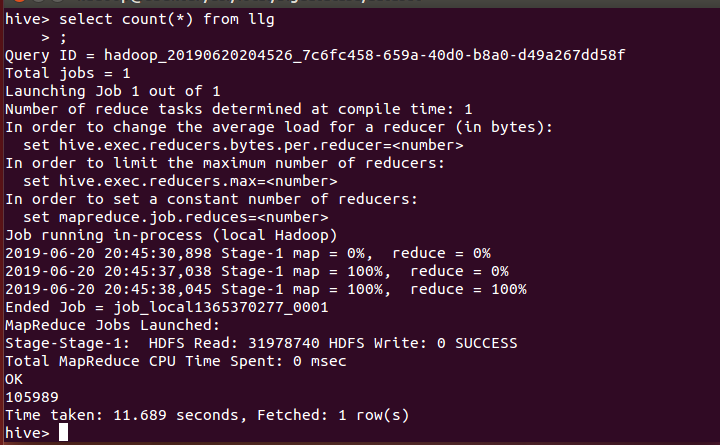
10、统计出不是同一用户评论的条数
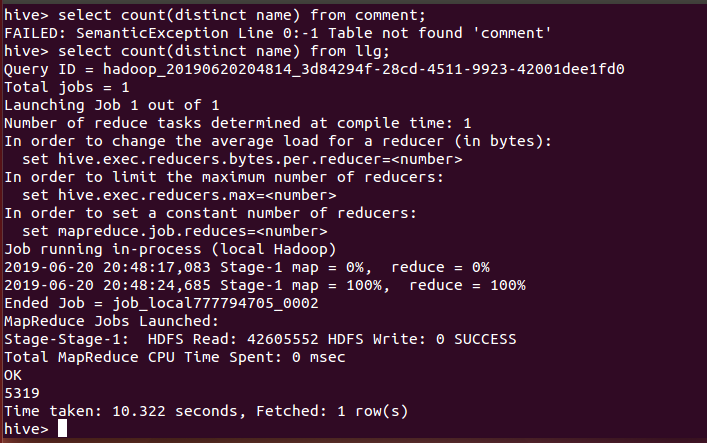
11、列出前10名观众分数和时间

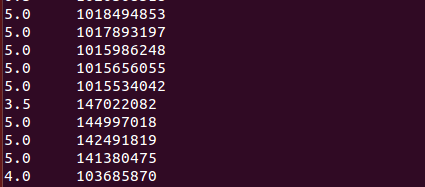
12、列出前10名观众的评论


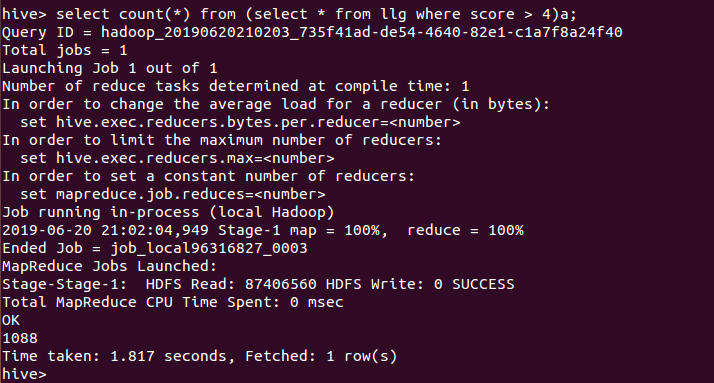
13、统计评论分数大于4分(总5分)的评论条数,大部分是大于4分,说明
《宝可梦》的好评率很高。
14、统计出皮卡丘出现频率
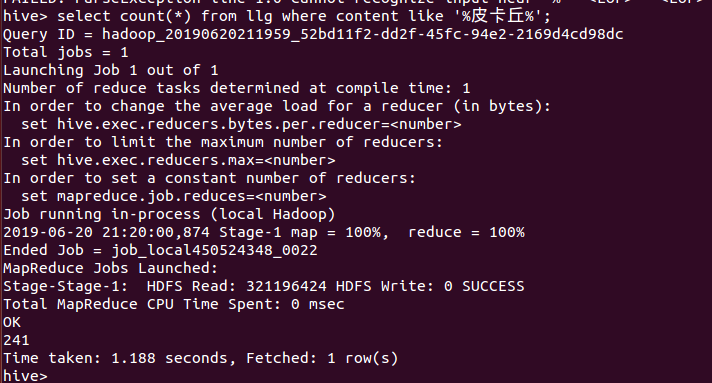
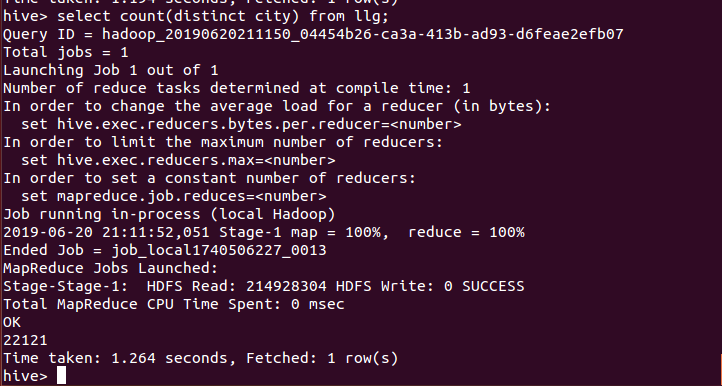
15、列出多少个城市
16、统计北京的评论数
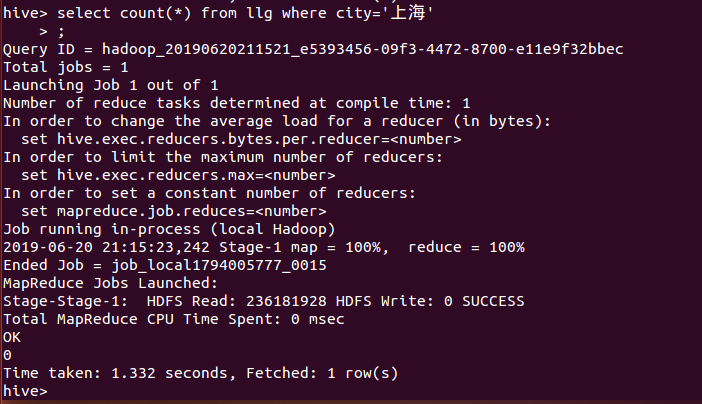
17、统计上海的评论数
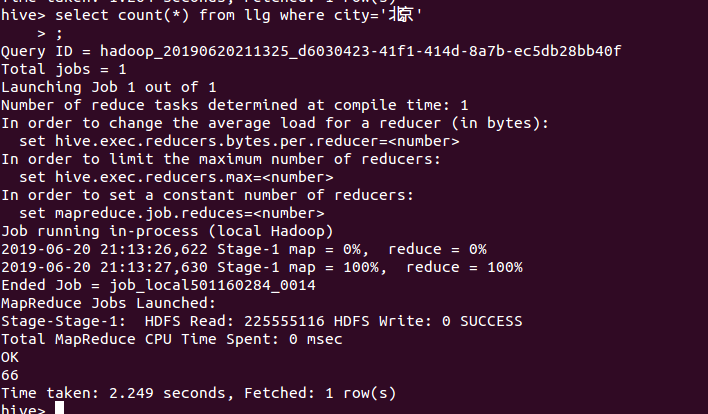
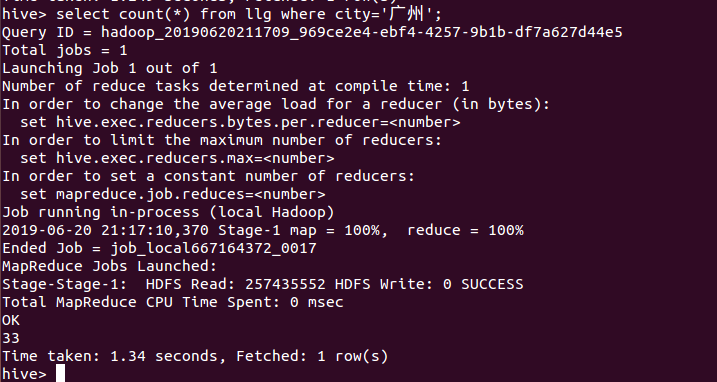
18、统计广州的评论数
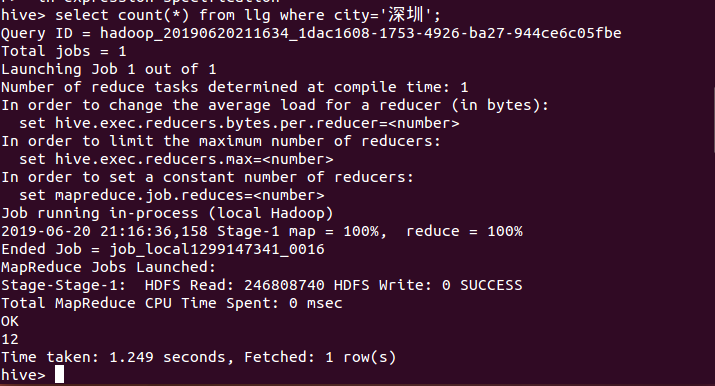
19、统计深圳的评论数

















 2657
2657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









