 Hive词频统计与数据分析
Hive词频统计与数据分析







 本文介绍如何使用Hive对爬虫作业产生的文本文件进行词频统计,并对CSV文件进行数据分析的过程。首先演示了英文词频统计的具体步骤,包括上传文件到HDFS、创建表及执行统计等;随后对爬取的校园新闻CSV文件进行了处理,从文件上传到HDFS到数据导入Hive表并进行分析。
本文介绍如何使用Hive对爬虫作业产生的文本文件进行词频统计,并对CSV文件进行数据分析的过程。首先演示了英文词频统计的具体步骤,包括上传文件到HDFS、创建表及执行统计等;随后对爬取的校园新闻CSV文件进行了处理,从文件上传到HDFS到数据导入Hive表并进行分析。
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
1.启动hadoop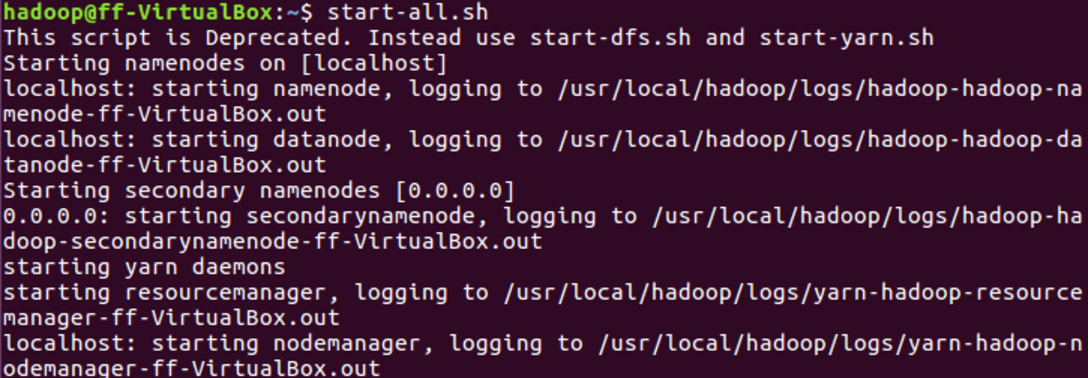
2.Hdfs上创建文件夹并查看
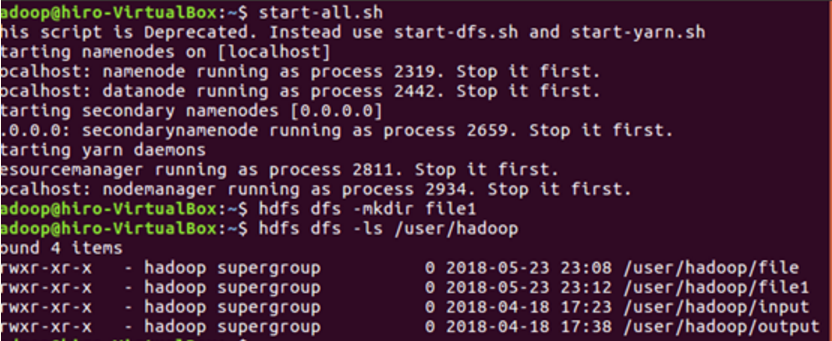
上传英文词频统计文本至hdfs

启动Hive
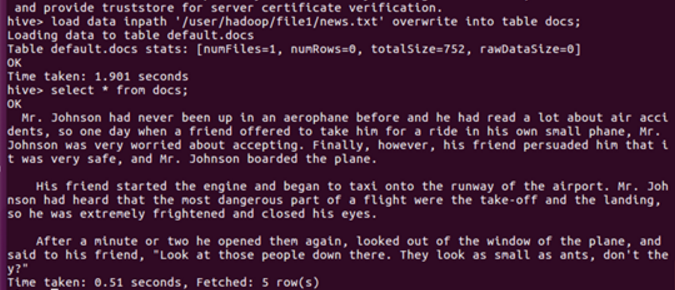
导入文件内容到表docs并查看
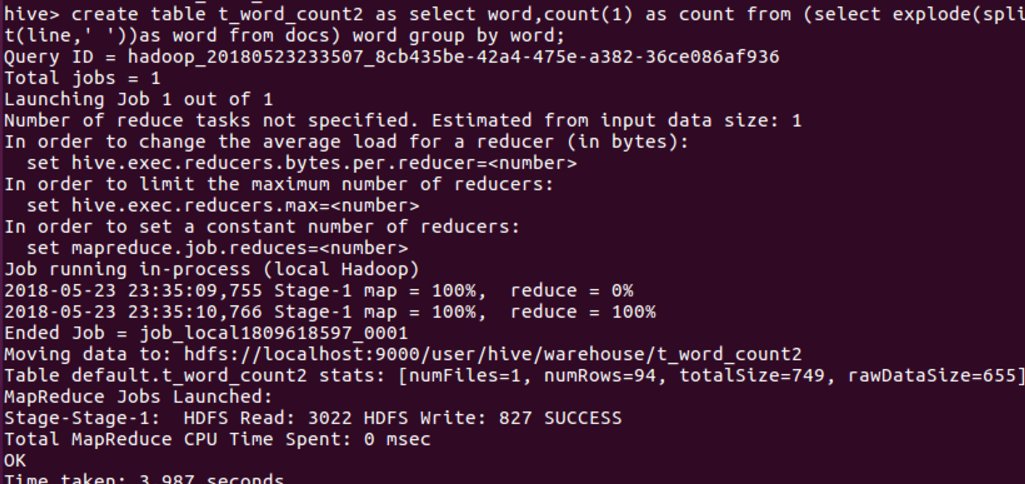
进行词频统计,结果放在表t_word_count2里
查看统计结果

二、用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
1.将做过的爬取校园新闻生成的Excel文件先转换为文本文件,编码改为UTF-8,然后转换为csv文件,通过qq邮箱在虚拟机的Linux系统下载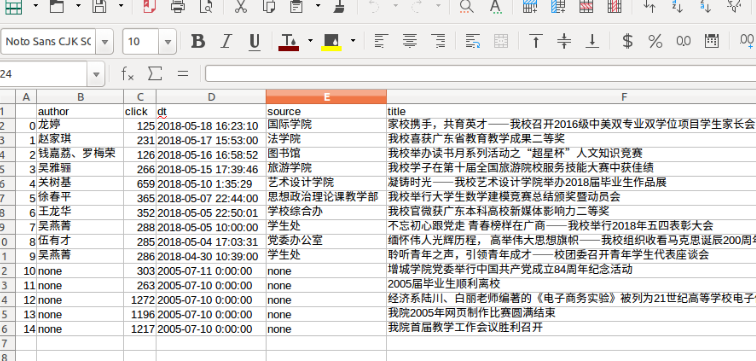
2.删除文件的第一条数据并查看
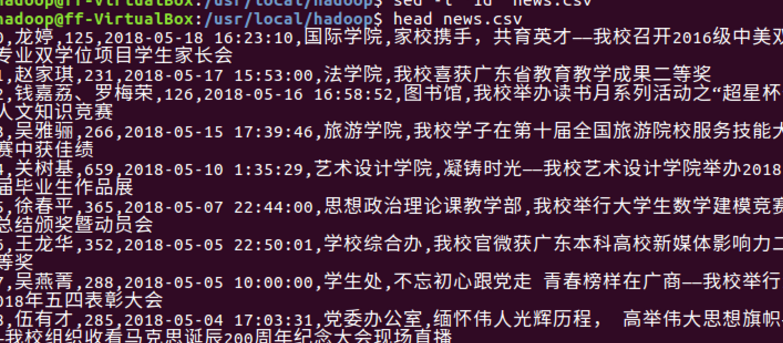
3.上传文件到hdfs

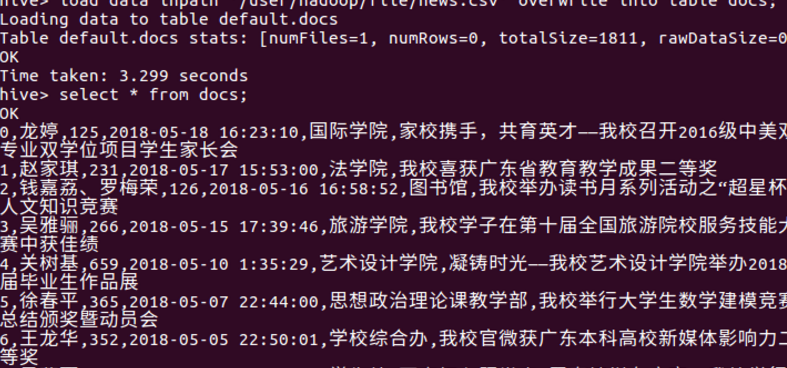
4.启动hive后,导入文件内容到表到docs中并查看

















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









