






 该博客记录了将爬虫大作业产生的csv文件上传到HDFS,查看数据集内容并处理成txt文件,再将hdfs中的文本文件导入数据仓库Hive,最后在Hive中查看并分析数据,得出这是一部非常好看的经典电影的结论。
该博客记录了将爬虫大作业产生的csv文件上传到HDFS,查看数据集内容并处理成txt文件,再将hdfs中的文本文件导入数据仓库Hive,最后在Hive中查看并分析数据,得出这是一部非常好看的经典电影的结论。
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
一、将爬虫大作业产生的csv文件上传到HDFS

二、查看数据集内容
查看评论前五条数据:

处理数据:
编辑dealdata.sh文件处理转化成txt
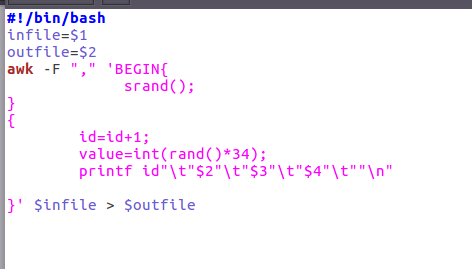
三、把hdfs中的文本文件最终导入到数据仓库Hive中

四、在Hive中查看并分析数据
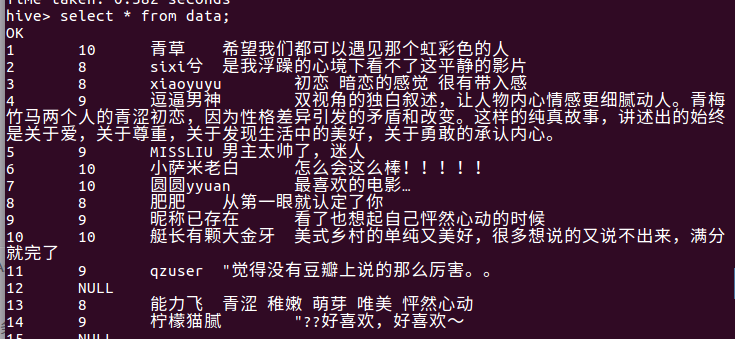
查看数据:
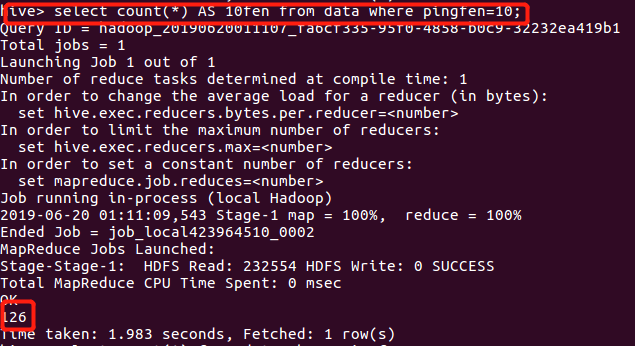
查看评分数据是10的人数:
查看评分数据9和8的人数分别是:
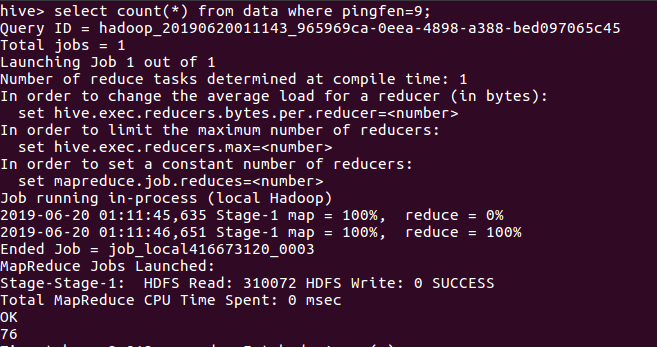
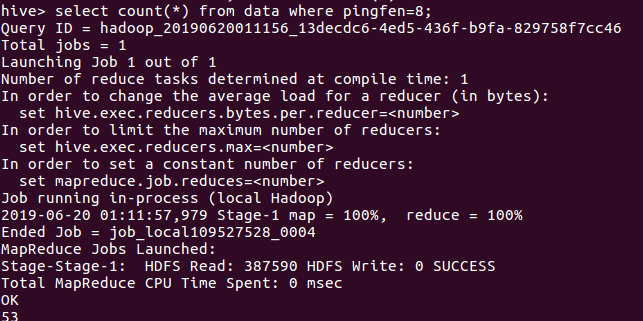
分析:数据有324条,十分好评的人数将近一半,评分为八九十的人数加起来有255人,约占有78.9%的人数。可以看出这是一部及其好看的经典电影。
总结:
通过这次数据的爬取,我学习到很多东西。也可爬取我自己喜欢的东西。一些经典的老电影。从数据说明这是一部非常好看的经典电影。

















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









