



 Elastic-Job是一种分布式调度解决方案,用于解决大数据量处理时的定时任务分片问题。通过将任务分发到不同的机器上,每台机器处理特定的数据分片,实现并行处理。本文介绍了Elastic-Job的基本概念、实例代码及如何利用Zookeeper进行任务分片。
Elastic-Job是一种分布式调度解决方案,用于解决大数据量处理时的定时任务分片问题。通过将任务分发到不同的机器上,每台机器处理特定的数据分片,实现并行处理。本文介绍了Elastic-Job的基本概念、实例代码及如何利用Zookeeper进行任务分片。
Elastic-Job是一个分布式调度解决方案,它解决了什么问题呢?
如果你需要定时对数据进行处理,但由于数据量实在太大了,一台机器处理不过来,于是用两台机器处理,第一台处理 id 为奇数的数据,第二台处理 id 为偶数的数据,elastic job 可以优雅地对任务进行分片,拿到分片的机器才能执行定时任务。
概念:instance,sharding,leader
1. 定时任务程序是 instance。
public class MyElasticJob implements SimpleJob { public void execute(ShardingContext sc) { System.out.println(sc.getShardingItem()); // 0, 1 System.out.println(sc.getShardingParameter()); // A, B System.out.println(sc.getShardingTotalCount()); // 2 if (0 == sc.getShardingItem()) { System.out.println("hello yinyinyin!"); // 处理 id 为偶数的数据 } else if (1 == sc.getShardingItem()) { System.out.println("hello yanyanyan!"); // 处理 id 为奇数的数据 } } }
2. elastic job 依赖 zk 对任务进行分片:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:reg="http://www.dangdang.com/schema/ddframe/reg" xmlns:job="http://www.dangdang.com/schema/ddframe/job" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.dangdang.com/schema/ddframe/reg http://www.dangdang.com/schema/ddframe/reg/reg.xsd http://www.dangdang.com/schema/ddframe/job http://www.dangdang.com/schema/ddframe/job/job.xsd"> <!--配置作业注册中心 --> <reg:zookeeper id="regCenter" server-lists="127.0.0.1:2181" namespace="dd-job" base-sleep-time-milliseconds="1000" max-sleep-time-milliseconds="3000" max-retries="3" /> <!-- 配置作业A--> <job:simple id="myElasticJob" class="util.MyElasticJob" registry-center-ref="regCenter" cron="0 0/1 * * * ?" overwrite="true" sharding-total-count="2" sharding-item-parameters="0=A,1=B" /> </beans>
zk 中定时任务的视图:
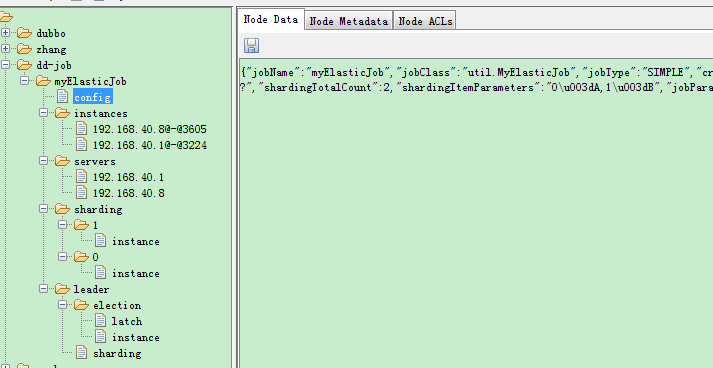
在 192.168.40.8 和 192.168.40.1 上分别有定时任务程序,定时任务有 2 个分片, 1 和 0。先注册到 zk 的 instance 是 leader,它负责对任务进行分片。leader/election 的 instance 节点是瞬时的,它记录了 leader 的信息。
如果是 leader 下线,会触发 leader 重新选举,如果有机器下线,会触发定时任务的重新分片。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









