






 博客主要包含两部分内容,一是使用datetime模块初始化start_day和end_day两个日期,且强调其它时间数据生成用该模块方法编程,不能用calendar模块;二是参考“三国演义”词频统计程序,实现对《红楼梦》出场人物的频次统计,还可将结果用词云显示。
博客主要包含两部分内容,一是使用datetime模块初始化start_day和end_day两个日期,且强调其它时间数据生成用该模块方法编程,不能用calendar模块;二是参考“三国演义”词频统计程序,实现对《红楼梦》出场人物的频次统计,还可将结果用词云显示。
1.初始化start_day,end_day两个日期
from datetime import datetime
start_day=datetime(2019,4,1)
end_day=datetime(2019,4,30)
其它时间数据生成要用datetime或date模块的方法编程实现
2.不能使用calendar模块生成
from datetime import datetime
startday=datetime(2019,4,1)
endday=datetime(2019,4,30)
count = 0
print("2019年四月\n")
print("周一\t周二\t周三\t周四\t周五\t周六\t周日")
for i in range (0,30):
i=i+1
print(i,end="\t")
count=count+1
if count%7==0:
print("\n")
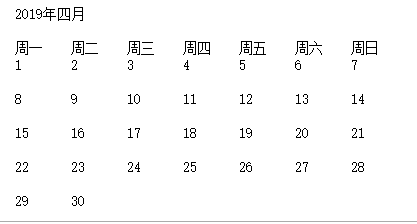
2:
1.参考“三国演义”词频统计程序,实现对红楼梦出场人物的频次统计。
2.(可选)
将红楼梦出场人物的频次统计结果用词云显示。
import jieba
excludes = {"什么", "一个", "我们", "那里", "你们", "如今", "起来", "说道", "姑娘", "这里",
"知道", "出来", "他们", "众人", "自己", "一面", "太太", "只见", "怎么", "两个",
"没有", "不是", "不知", "这个", "这样", "听见", "进来", "咱们", "告诉", "就是",
"东西", "王夫人", "袭人", "奶奶", "回来", "只是", "老爷", "大家","只得","打发",
"丫头", "这些", "不敢", "出去", "平儿", "所以", "薛姨妈","不过", "的话","不好",
"姐姐", "鸳鸯", "一时", "不能", "过来", "心里", "二爷","如此", "今日", "银子",
"几个", "答应", "二人", "还有", "只管", "这么", "说话","一回", "那边","这会子",
"这话","外头","瞧瞧", "跟前", "已经","谁知","难道","不肯","自然","今儿","屋里",
"那些","罢了","听说","小丫头","邢夫人","如何","问道","看见","紫鹃","妹妹","人家",
"不用","媳妇","香菱","原来","一声","一句","家里","不得","到底","进去","姊妹","别人",
"回去","丫鬟","过去","连忙","心中","方才","还是","婆子","尤氏","里头","小厮","哥哥",
"不成","身上","只有","有人","起身","于是","一件","这是","果然","明白","那个","一日",
"怎么样","跟前","已经","谁知","有些","喜欢","不如","主意","只怕","不必","越发","明儿",
"薛蟠","好些","吩咐","贾赦","况且","便是","母亲","上来"}
txt = open(r"C:\Users\Administrator\Desktop\红楼梦.txt", "r", encoding='utf8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
elif word=="怡红公子"or word=="宝玉"or word=="宝二爷":
rword="贾宝玉"
elif word=="林黛玉"or word=="黛玉道":
rword="黛玉"
elif word=="薛宝钗"or word=="宝姐姐"or word=="蘅芜君"or word == "宝丫头" or word == "宝姑娘":
rword="宝钗"
elif word== "凤姐"or word=="琏二奶奶"or word=="凤哥儿"or word=="凤丫头"or word=="凤姐儿" :
rword="王熙凤"
elif word=="贾母":
rword="老太太"
elif word=="贾探春":
rword="探春"
elif word=="刘姥姥":
rword="刘姥姥"
elif word=="贾惜春"or word=="惜春":
rword="惜春"
elif word == "晴雯":
rword = "晴雯"
elif word == "湘云":
rword = "湘云"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1 #词汇加入字典
for word in excludes:
del(counts[word]) #从字典中删除无用词
items = list(counts.items())#字典转换为列表
items.sort(key=lambda x:x[1], reverse=True)
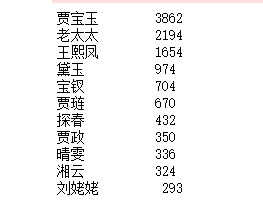
for i in range(11): #出现的词频统计
word, count = items[i] #将键和值分别赋予列表word和count
print ("{0:<10}{1:>5}".format(word, count))#0:<10左对齐,宽度10,”>5"右对齐

















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









