






 本文通过数学推导详细解释了神经网络中梯度消失与梯度爆炸的问题,并介绍了LSTM解决这些问题的方法。
本文通过数学推导详细解释了神经网络中梯度消失与梯度爆炸的问题,并介绍了LSTM解决这些问题的方法。
链接:https://www.zhihu.com/question/49812013/answer/148825073
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简单地说,根据链式法则,如果每一层神经元对上一层的输出的偏导乘上权重结果都小于1的话( ),那么即使这个结果是0.99,在经过足够多层传播之后,误差对输入层的偏导会趋于0(
),那么即使这个结果是0.99,在经过足够多层传播之后,误差对输入层的偏导会趋于0( )。下面是数学推导推导。
)。下面是数学推导推导。
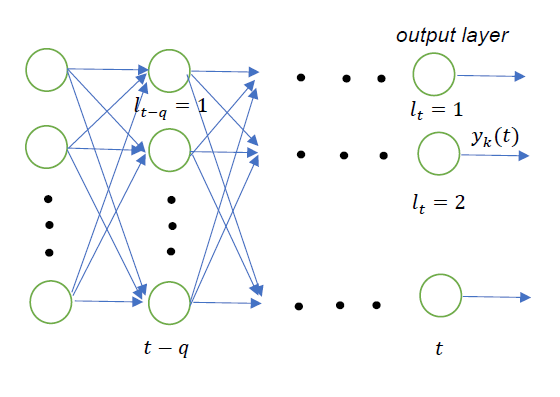
假设网络输出层中的第 个神经元输出为
个神经元输出为 ,而要学习的目标为
,而要学习的目标为 。这里的
。这里的 表示时序,与输入无关,可以理解为网络的第 层。
表示时序,与输入无关,可以理解为网络的第 层。
若采用平方误差作为损失函数,第 个输出神经元对应的损失为 
将损失 对输出求偏导
对输出求偏导 
根据链式法则,我们知道,第 层的梯度可以根据第 层的梯度求出来
层的梯度可以根据第 层的梯度求出来

这里用 表示第 层的第 个神经元,
表示第 层的第 个神经元, 表示第 层的第 个神经元。
表示第 层的第 个神经元。
进一步,第 层的梯度可以由第
层的梯度可以由第 层的梯度计算出来
层的梯度计算出来

这实际上是一个递归嵌套的式子,如果我们对 做进一步展开,可以得到式子
做进一步展开,可以得到式子
![\vartheta_{i}(t-q)=y_{i}'(t-q)\sum_{j}w_{ij}[y_{j}'(t-q+1)\sum_{k}w_{jk}\vartheta_{k}(t-q+2))]](https://i-blog.csdnimg.cn/blog_migrate/038998d09dd65075c23559f3f888a728.png)
最终,可以一直展开到第 层。
把所有的加法都移到最外层,可以得到

 表示的是第 层中神经元的下标(即第 层第 个神经元),
表示的是第 层中神经元的下标(即第 层第 个神经元), 表示第 层的下标。
表示第 层的下标。 对应输出层,
对应输出层, 对应第 层。实际上展开式就是从网络的第 层到 层,每一层都取出一个神经元来进行排列组合的结果。这个式子并不准确,因为 时实际是损失 对输出层的偏导,即
对应第 层。实际上展开式就是从网络的第 层到 层,每一层都取出一个神经元来进行排列组合的结果。这个式子并不准确,因为 时实际是损失 对输出层的偏导,即
 ,
,
并没有应用权重 ,把它修正一下
,把它修正一下

这样,我们就得到了第 层和第 层的梯度之间的关系

在上面的式子中,由于加法项正负号之间可能互相抵消。因此,比值的量级主要受最后的乘法项影响。如果对于所有的 有
有

则梯度会随着反向传播层数的增加而呈指数增长,导致梯度爆炸。
如果对于所有的 有

则在经过多层的传播后,梯度会趋向于0,导致梯度消失。
LSTM就是为了解决以上两个问题提出的方法之一,它强制令 。 LSTM如何来避免梯度弥撒和梯度爆炸? - 知乎
有兴趣可以参考Long Short Term Memory 一文 。上面的推导过程大体上也参考自这篇论文。
Reference:
Graves, Alex. Long Short-Term Memory. Supervised Sequence Labelling with Recurrent Neural Networks. Springer Berlin Heidelberg, 2012:1735-1780.

















 3183
3183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









