






对象序列化主要有两种作用
1, 使用序列化保存对象状态保文件中,当需要时从文件中读出重构状态
web服务器中的Session对象就是很需要序列化的对象,当用户访问量很大时,session对象也不断增多,如果session全部保存在内存中,内存可能负载很大,这时就需要将一小部分生存周期还存在的session存入硬盘,当用户再登录时,就可将seeion对象反序列化,从而继续使用
2, 使用序列化保存对象状态保文件中,当需要时从文件中读出重构状态
使用序列化在网络中传送对象
网络传输中都是以二进制序列的方式传输,当要传输一个类对象时,需要将类对象一字节流的形式进行传输
若要将类对象序列化,则需要将类实现 java.io.Serlializablej接口
序列化包含两部分
一个是序列化,另一个是反序列化。ObjectOutputStream 的 WriteObject()方法负责将对象序列化保存到文件中,而ObjectInputStream的ReadObject()则负责将对象从文件中反序列化过来进行重构。
我们来看下以下一段代码
import java.io.*;
public class TestSerializable {
public static void main(String[] args) {
Employee em = new Employee("tom",5000);
Manager mr = new Manager("kimo",80000);
mr.setSectary(em);
Employee[] ems = new Employee[2];
ems[0]=em;
ems[1]=mr;
try {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(".\\test.txt"));
oos.writeObject(ems);
oos.close();
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(".\\test.txt"));
Employee[] staff=(Employee[])ois.readObject();
ois.close();
staff[0].addSalary(20);
for(int i=0;i<staff.length;i++) {
System.out.println(staff[i]);
}
}
catch (Exception e) {
e.printStackTrace();
}
}
}
class Employee implements Serializable{
//private String age;
String name;
double salary;
public Employee(String name,double salary) {
this.name = name;
this.salary = salary;
}
public void addSalary(double percent) {
double raise=salary*percent/100;
salary += raise;
}
public String toString() {
return this.getClass().getName()+"["+"name:"+name+"salary:"+salary+"]";
}
}
class Manager extends Employee {
private Employee sectary;
public Manager(String name,double salary) {
super(name,salary);
sectary=null;
}
public void setSectary(Employee sectary) {
this.sectary = sectary;
}
public String toString() {
return this.getClass().getName()+"["+"name:"+super.name+"salary:"+super.salary+"sectary:"+this.sectary+"]";
}
}
结果如下:成功读取对象在文件中保存的状态
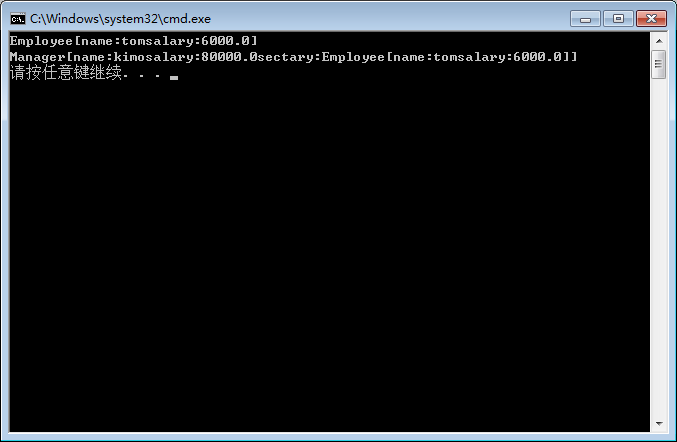
当然 大家如果想类的某个成员变量不被序列化,可在其前添加transient关键字,这样这个属性所对应的对象状态不会被序列化,更不可能被恢复.
讲的很浅,以后深入后会慢慢补充。。。。

















 1869
1869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









