






 本文详细介绍了如何在HBase shell中进行模糊查询和数据操作,包括创建、删除表,插入、获取和删除数据,以及使用-scan命令进行全表扫描和应用过滤器。特别是对于-f选项的模糊匹配在shell中的应用,提供了实用的例子。
本文详细介绍了如何在HBase shell中进行模糊查询和数据操作,包括创建、删除表,插入、获取和删除数据,以及使用-scan命令进行全表扫描和应用过滤器。特别是对于-f选项的模糊匹配在shell中的应用,提供了实用的例子。
0.进入hbase shell./hbase shell help help “get” #查看单独的某个命令的帮助
1. 一般命令status 查看状态
version 查看版本
2.DDL(数据定义语言Data Definition Language)命令
1. 创建表
create ‘表名称’,’列名称1’,’列名称2’,’列名称3’ 如:create 'member','member_id','address','info'1
2.列出所有的表
list
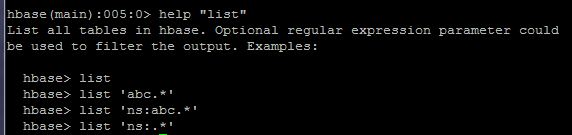 list ‘abc.*’ #显示abc开头的表
list ‘abc.*’ #显示abc开头的表
3.获得表的描述describe ‘table_name’
 Table play_error_file is ENABLED
Table play_error_file is ENABLED
play_error_file
column families description
{
NAME=> 'cf',
BLOOMFILTER=> 'ROW',#根据应用来定,看需要精确到rowkey还是column。bloom filter的作用是对一个region下查找记录所在的hfile有用。一个region下hfile数量越多,bloom filter的作用越明显。适合那种compaction(压缩)赶不上flush速度的应用。
VERSIONS=> '1',# 通常是3,对于更新比较频繁的应用可以设置为1
IN_MEMORY=> 'false',
KEEP_DELETED_CELLS=> 'FALSE',
DATA_BLOCK_ENCODING=> 'NONE',
TTL=> 'FOREVER',
COMPRESSION=> 'NONE',
MIN_VERSIONS=> '0',
BLOCKCACHE=>'true',
BLOCKSIZE=> '65536',
REPLICATION_SCOPE=> '0'
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
4.删除一个列族 alter,disable, enabledisable 'member' #删除列族时必须先将表给disable
alter 'member',{NAME=>'member_id',METHOD=>'delete'}
#删除后继续enable 'member'
enable 'member'1
2
3
4
5.删除表disable 'table_name'drop 'table_name'1
2
6.查询表是否存在exists 'table_name'1
7.判断表是否enabledis_enabled 'table_name'1
8.更改表名//快照 这样试试,先建立个表自己测试下,可以的话在执行。
需要开启快照功能,在hbase-site.xml文件中添加如下配置项:
hbase.snapshot.enabled
true
//命令
hbase shell> disable 'tableName'
hbase shell> snapshot 'tableName', 'tableSnapshot'
hbase shell> clone_snapshot 'tableSnapshot', 'newTableName'
hbase shell> delete_snapshot 'tableSnapshot'
hbase shell> drop 'tableName'1
2
3
4
5
6
7
8
9
10
11
12
13
14
3.DML(data manipulation language)操作
1.插入
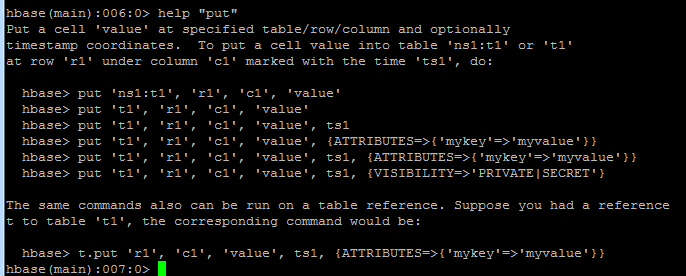 在ns1:t1或者t1表里的r1行,c1列中插入值,ts1是时间put 'ns1:t1', 'r1','c1','value'or
在ns1:t1或者t1表里的r1行,c1列中插入值,ts1是时间put 'ns1:t1', 'r1','c1','value'or
put 't1','r1','c1','value'or
put 't1','r1','c1','value',ts1
or
put 't1','r1','c1','value',{ATTRIBUTES=>{'mykey'=>'myvalue'}}
put 't1','r1','c1','value',ts1,{ATTRIBUTES=>{'mykey'=>'myvalue'}}
put 't1','r1','c1','value',ts1,{VISIBILITY=>'PRIVATE|SECRET}
# t是table 't1'表的引用
t.put 'r1','c1','value',ts1,{ATTRIBUTES=>{'mykey'=>'myvalue'}}
put 'table_name','row_index','info:age','24'
put 'table_name','row_index','info:birthday','1987-06-17'
put 'table_name','row_index','info:company','tencent'
put 'table_name','row_index','address:contry','china'
put 'table_name','row_index','address:province','china'
put 'table_name','row_index','address:city','shenzhen'1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2.获取一条数据
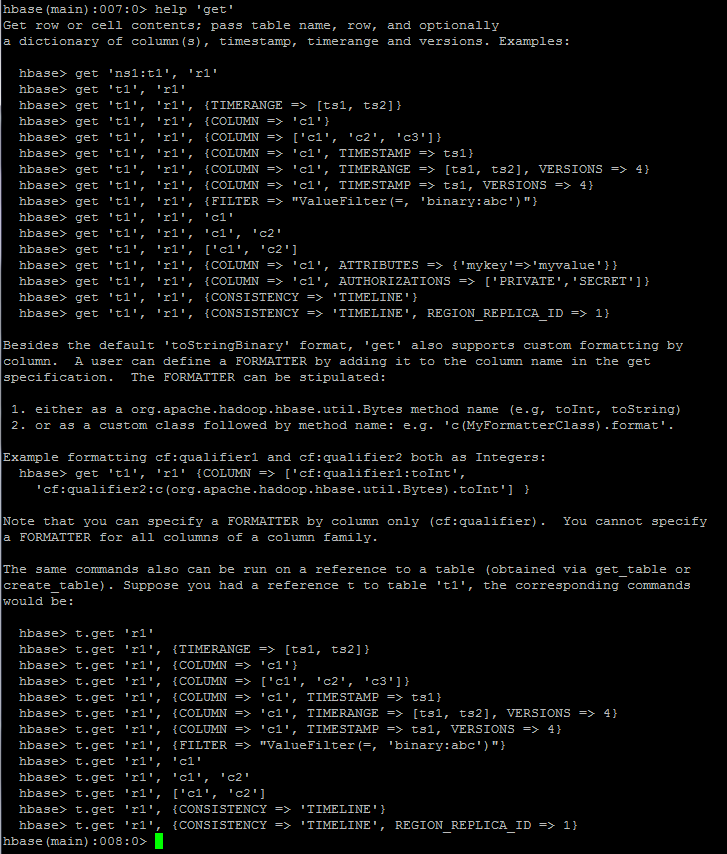 # 获取一个id的所有数据get 'table_name','row_index'# 获取一个id,一个列族的所有数据get 'table_name','row_index','info'# 获取一个id,一个列族中一个列的所有数据get 'table_name','row_index','info:age'1
# 获取一个id的所有数据get 'table_name','row_index'# 获取一个id,一个列族的所有数据get 'table_name','row_index','info'# 获取一个id,一个列族中一个列的所有数据get 'table_name','row_index','info:age'1
2
3
4
5
6
7
8
3.更新一条记录
将qy的单位改为qq put ‘table_name’,’qy’,’info:company’,’qq’
4.通过timestrap来获取两个版本的数据# 得到company为tencent的记录
get 'table_name','qy',{COLUMN=>'info:company',TIMESTRAP=>1321586238965}
# 得到company为qq的数据
get 'table_name','qy',{COLUMN=>'info:company',TIMESTRAP=>1321586271843}1
2
3
4
5.全表扫描
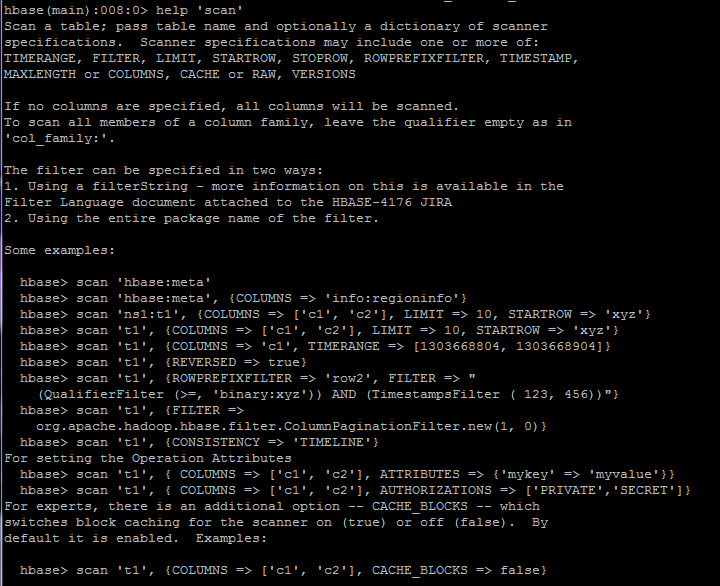
 scanner规范: TIMERANGE, FILTER, LIMIT, STARTROW(start row), STOPROW(stop row), ROWPREFIXFILTER(row prefix filter,行前缀) TIMESTAMP, MAXLENGTH, or COLUMNS, CACHE, or RAW, VERSIONSscan 'hbase:meta'
scanner规范: TIMERANGE, FILTER, LIMIT, STARTROW(start row), STOPROW(stop row), ROWPREFIXFILTER(row prefix filter,行前缀) TIMESTAMP, MAXLENGTH, or COLUMNS, CACHE, or RAW, VERSIONSscan 'hbase:meta'
scan 'hbase:meta',{COLUMNS => 'info:regioninfo'}
scan 'ns1:t1',{COLUMNS=>['c1','c2'],LIMIT=>10,STARTROW=>'xyz'}
scan 't1',{COLUMNS=>'c1',TIMERANGE=>[1303668804,1303668904]}
scan 't1',{REVERSED=>true}
scan 't1',{
ROWPREFIXFILTER=>'row2',
FILTER=>"(QualifierFilter(>=,'binary:xyz'))
AND (TimestampsFilter(123,456))"}
scan 't1',{FILTER => org.apache.hadoop.hbase.filter.ColumnPaginationFilter.new(1,0)}
scan 't1',{CONSISTENCY=>'TIMELINE'}
设置操作属性:
scan 't1',{COLUMNS => ['c1','c2'],ATTRIBUTES=>{'mykey'=>'myvalue'}}
scan 't1',{COLUMNS=>['c1','c2'],AUTHORIZATIONS=>['PRIVATE','SECRET']}
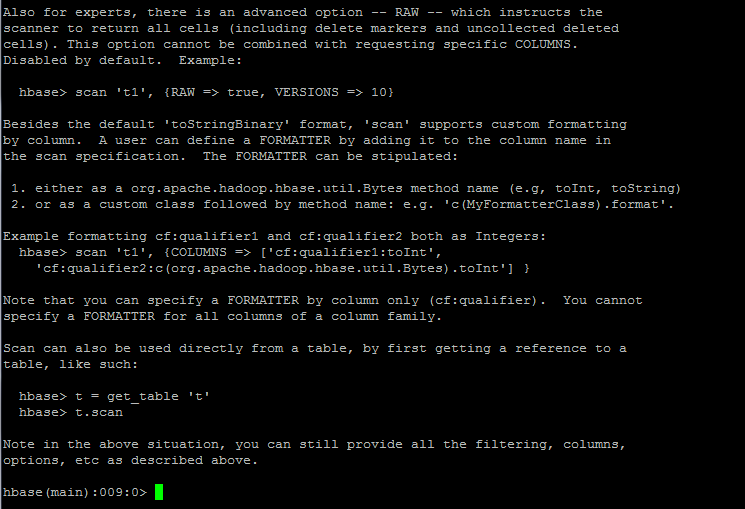
有个额外的选项:CACHE_BLOCKS,默认为true
还有个选项:RAW,返回所有cells(包括删除的markers和uncollected deleted cells,不能用来选择特定的columns,默认为default)
如:scan 't1',{RAW=>true,VERSIONS=>10}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
全表扫描一般不会用,数据量大的时候会死人的。。
6.删除记录
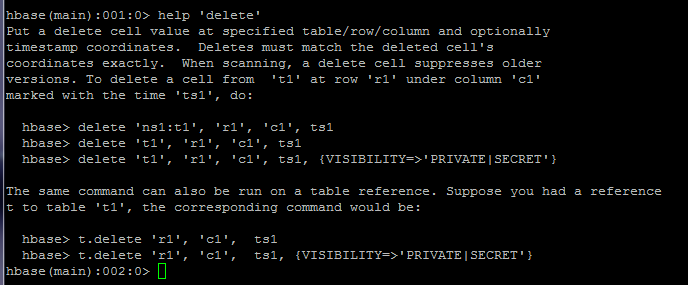 # 删除id为temp的记录的'info:age'字段
# 删除id为temp的记录的'info:age'字段
delete 'member','temp','info:age'# 删除整行
deleteall 'member','temp'1
2
3
4
5
7.查询表中有多少行count 'table_name',INTERVAL=>1000,CACHE => 1000or
有对表t1的引用t
t.count
INTERVAL: 每隔多少行显示一次count,默认是1000
CACHE:每次去取的缓存区大小,默认是10,调整该参数可提高查询速度1
2
3
4
5
6
8.清空表truncate 'table_name'
HBase是先将表disable,再drop the table,最后creating table。1
2
5.scan查询
1.限制条件scan ‘qy’,{COLUMNS=>’name’}
 scan ‘qy’,{COLUMNS=>’name:gender’}
scan ‘qy’,{COLUMNS=>’name:gender’}
 scan ‘qy’,{COLUMNS=>[‘name’,’foo’]}
scan ‘qy’,{COLUMNS=>[‘name’,’foo’]}
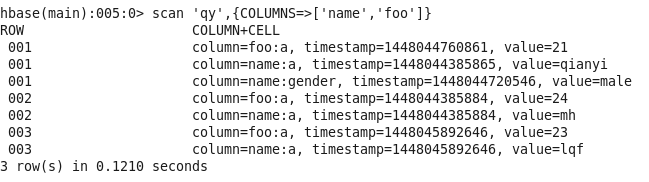
限制查找条数:scan ‘qy’,{COLUMNS=>[‘name’,’foo’],LIMIT=>1} scan ‘qy’,{COLUMNS=>[‘name’,’foo’],LIMIT=>2}
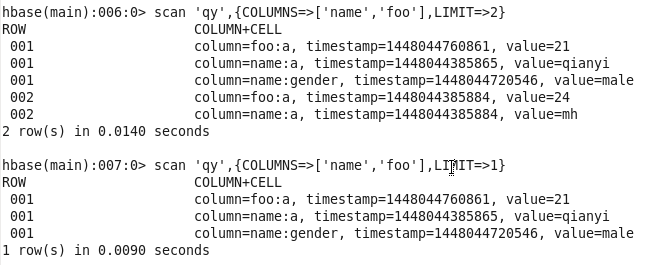
限制时间范围:scan ‘qy’,{TIMERANGE=>[1448045892646,1448045892647]}

2.filter 过滤部分
PrefixFilter:rowKey前缀过滤scan ‘qy’,{FILTER=>”PrefixFilter(‘001’)”}
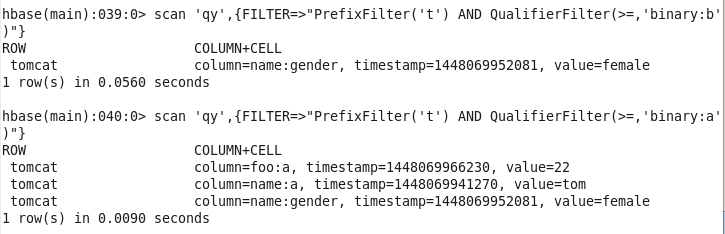
 scan ‘qy’,{FILTER=>PrefixFilter(‘t’)}
scan ‘qy’,{FILTER=>PrefixFilter(‘t’)}

QualifierFilter:列过滤器
QualifierFilter对列的名称进行过滤,而不是列的值。scan ‘qy’,{FILTER=>”PrefixFilter(‘t’) AND QualifierFilter(>=,’binary:b’)”}
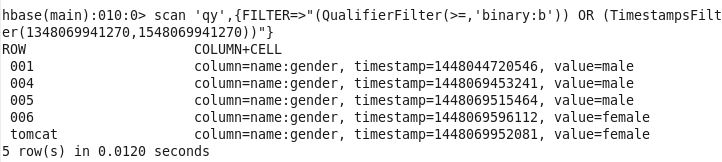
TimestampsFilter:时间戳过滤器scan ‘qy’,{FILTER=>”TimestampsFilter(1448069941270,1548069941230)” }
 scan ‘qy’,{FILTER=>”(QualifierFilter(>=,’binary:b’)) AND (TimestampsFilter(1348069941270,1548069941270))” }
scan ‘qy’,{FILTER=>”(QualifierFilter(>=,’binary:b’)) AND (TimestampsFilter(1348069941270,1548069941270))” }
ColumnPaginationFilterscan ‘qy’,{FILTER=>org.apache.hbase.filter.ColumnPaginationFilter.new(2,0)}
cannot load Java class org.apache.hbase.filter.ColumnPaginationFilterimport org.apache.hadoop.hbase.filter.CompareFilter
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter
import org.apache.hadoop.hbase.filter.SubstringComparator
import org.apache.hadoop.hbase.util.Bytes1
2
3
4
2.执行命令scan 'tablename',STARTROW=>'start',COLUMNS=>['family:qualifier'],FILTER=>SingleColumnValueFilter.new(Bytes.toBytes('family'),Bytes.toBytes('qualifier'))1

















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









