






 本文介绍了决策树中的ID3算法原理,包括信息熵、信息增益等概念,并通过一个购买电脑的案例详细展示了如何利用Python实现ID3算法。此外,还提供了完整的代码示例。
本文介绍了决策树中的ID3算法原理,包括信息熵、信息增益等概念,并通过一个购买电脑的案例详细展示了如何利用Python实现ID3算法。此外,还提供了完整的代码示例。
一、理论知识
1、基本流程
判定树/决策树 (decision tree) 是一类常见的机器学习方法。
每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的"分而治之" (divide-and-conquer)策略。
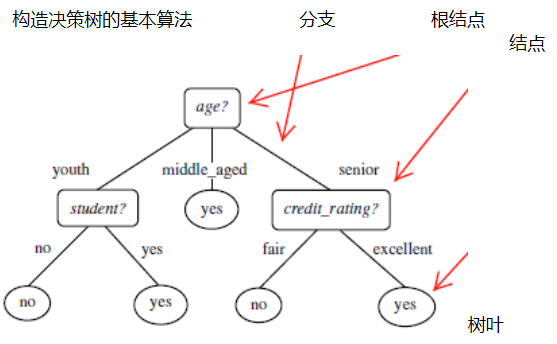
2、划分选择
在1948年,香农引入了信息熵,将其定义为离散随机事件出现的概率,一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它的信息熵就越高。所以信息熵可以被认为是系统有序化程度的一个度量。
假如一个随机变量X的取值为X={x1,x2,……,xn},每一变量的概率分别为{p1,p2,……,pn},那么X的信息熵定义为:

信息增益是针对一个特征而言的,就是看一个特征t,系统有它和没有它时的信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即信息增益。接下来,以一个属性不同的人购买电脑的例子来说明什么是信息增益。稍后,也会用Python代码实现此例的决策树算法。
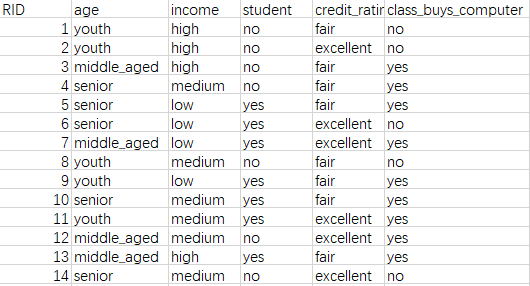
从上图可以看出,一共14组数据,在最后一列的数据中是购买电脑的与否,一共是9个购买,5个非购买。
由此可以得到结果的信息熵为 :

age分支有youth,middle_aged,senior,其信息熵为:
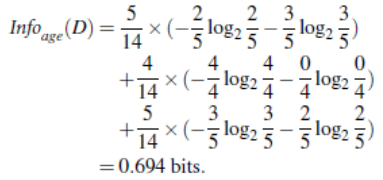
因此age属性的信息增益为:
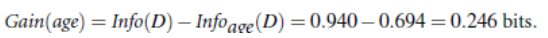
类似地,我们可以得出其它属性的信息增益:
Gain(income) = 0.029, Gain(student) = 0.151, Gain(credit_rating)=0.048
值得一提的是,我们应该忽略编号这一属性,因为其产生了14个分支,每个分支节点的纯度以达到最大,以其作为结点的决策树不具有泛化能力,无法进行有效预测。
相比较,我们就可以得出,age的信息增益最大,因此选择age为根结点,再选出其它的作为结点,可以画出一个决策树的图。

在决策树的每一个非叶子结点划分之前,先计算每一个属性所带来的信息增益,选择最大信息增益的属性来划分,因为信息增益越大,区分样本的能力就越强,越具有代表性,很显然这是一种自顶向下的贪心策略。以上就是ID3算法的核心思想。显然,ID3算法是以信息增益为准则来选择划分属性。
3、剪枝处理
4、连续与缺失值
5、多变量决策树
二、代码
1、Python实现ID3算法,以上文购买电脑为例。
# sklearn 是传统机器学习的包 # python自带处理csv文件的库 from sklearn.feature_extraction import DictVectorizer import csv from sklearn import tree from sklearn import preprocessing # 读取csv文件数据,CSV是以逗号间隔的文本文件,excel默认保存为XLSX格式,包含文本、数值、公式、格式等,当不需要公式格式时,可以保存为CSV文件 allElectronicsData = open(r'AllElectronics.csv', 'rt') reader = csv.reader(allElectronicsData) # 读出第一行的内容,并打印观察 headers = next(reader) print(headers) # sklearn 只允许输入的内容是数值,所以我们要把表格里的内容转换为数值,进而调用sklearn的包 # 建立两个列表以存储条件和结果 featureList = [] labelList = [] # labelList 里存放表格里的结果内容 # featureList 里存放表格里的条件属性,必须是以字典形式存储在列表中,这样才可以用DictVectorizer()函数,将列表中的字典转化成数值 for row in reader: labelList.append(row[len(row)-1]) rowDict = {} for i in range(1, len(row)-1): rowDict[headers[i]] = row[i] featureList.append(rowDict) print(featureList) print(labelList) # 类DictVectorizer可用于将表示为标准 Python dict对象列表的要素数组转换为scikit-learn估计量使用的NumPy/SciPy表示。 # 使用DictVectorizer里的fit_transform函数转换数值 vec = DictVectorizer() dummyX = vec.fit_transform(featureList).toarray() print("dummyX: " + str(dummyX)) print(vec.get_feature_names()) print("labelList: " + str(labelList)) lb = preprocessing.LabelBinarizer() dummyY = lb.fit_transform(labelList) print("dummyY: " + str(dummyY)) # 使用决策树 # criterion='entropy' 此变量输入则代表决策树的算法是选取信息熵(ID3算法) clf = tree.DecisionTreeClassifier(criterion='entropy') clf = clf.fit(dummyX, dummyY) print("clf: " + str(clf)) # 新建doc文件,在其中显示决策树 with open("allElectronicInformationGainOri.dot", 'w') as f: f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f) oneRowX = dummyX[0, :] print("oneRowX: " + str(oneRowX)) newRowX = oneRowX newRowX[0] = 1 newRowX[2] = 0 print("newRowX: " + str(newRowX))
三、参考资料
1、《机器学习》——周志华老师
2、http://www.cnblogs.com/starfire86/p/5749328.html 内含C++代码实现决策树
ps:待更新。
本人初学者,有错误欢迎指出。感谢。

















 1936
1936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









