



 本文解析了 Python 中 '==' 和 'is' 的区别,详细介绍了基于对象值与内存地址的比较原理,并探讨了 Python 的内部机制如何影响变量间的比较。此外,还讲解了字符编码转换的基本概念,包括不同编码之间的识别问题及其应用场景。
本文解析了 Python 中 '==' 和 'is' 的区别,详细介绍了基于对象值与内存地址的比较原理,并探讨了 Python 的内部机制如何影响变量间的比较。此外,还讲解了字符编码转换的基本概念,包括不同编码之间的识别问题及其应用场景。
一、== 和 is
== 比较的是值
is 比较的是地址
id() -- 返回对象的内存地址
例:
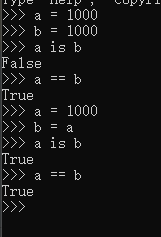
赋值操作是将地址赋给变量
Python 中会实现创建一个小型的整形池,范围为 [-5,256],为这些整形开辟好内存空间,当代码中定义该范围内的整形时,不会再重新分配内存地址。如下:

其实,此处测试是在控制台使用交互式命令测试,上述结论只针对此种交互式命令方式,在pycharm或其他解释器中得到的结果则会不同,原因如下:
事实上:
Python出于对性能的考虑,但凡是不可变对象,在同一个代码块中的对象,只要是值相同的对象,就不会重复创建,而是直接引用已经存在的对象。
这是因为python中有个intern机制。intern机制就是不管你创建了多少个相同的字符串,在python中都是会指向同一个对象的。这是为了防止你不小心创建了多个相同对象而浪费大量内存甚至会发生挤爆内存的后果。
在控制台想得到同样测试结果的测试办法:
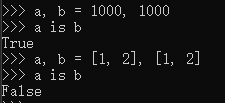
由此,可看出,这是python的机制,并非pycharm或其他解释器进行了优化。
控制台与pycharm执行方式(以下这段话摘抄):
对于Python而言,存储好的脚本文件(Script file)和在Console中的交互式(interactive)命令,执行方式不同。对于脚本文件,解释器将其当作整个代码块执行,而对于交互性命令行中的每一条命令,解释器将其当作单独的代码块执行。而Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用(这句话不够严谨,后面会详谈)。所以在你给出的例子中,文件执行时(同一个代码块)会把a、b两个变量指向同一个对象;而在命令行执行时,a、b赋值语句分别被当作两个代码块执行,所以会得到两个不同的对象,因而is判断返回False。
可用id()测试:
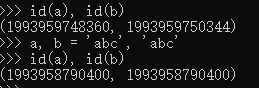
从上也可看出,两个变量确实指向同一个地址。
二、字符编码转换
| 编码 | 英文(字节) | 中文(字节) | 备注 |
| ASCII | 1 | 无法表示 | |
| unicode | 4 | 4 | 16位表示的已经不再使用 |
| utf-8 | 1 | 3 | 还有utf-16、utf-32 |
| gbk | 1 | 2 |
1、各编码之间不能互相识别,强行识别会产生乱码
2、文件的存储、传输不能使用unicode(应该是不推荐使用,也可以用的吧,这里没找到讲一定不能用的资料)
3、str在内存中的使用unicode编码(这个是历史原因,可百度)
bytes类型
在Python3以后,字符串和bytes类型彻底分开了。字符串是以字符为单位进行处理的,bytes类型是以字节为单位处理的。
bytes数据类型在所有的操作和使用甚至内置方法上和字符串数据类型基本一样,也是不可变的序列对象。
其实就是二进制表示的字符串,只是在表示形式上:
- 英文:
- str:表现形式:s = ‘tangtang’ 编码方式:unicode
- bytes:表现形式:s = b‘tangtang’ 编码方式:utf-9、gbk。。。
- 中文
- str:表现形式:s = ‘糖糖’ 编码方式:unicode
- bytes:表现形式:s = b'\xe7\xb3\x96\xe7\xb3\x96' 编码方式:utf-8、gbk。。。
ps:中文根据字节数可以判断是哪种编码方式,这里‘\xXX’表示一个字节
encode编码
encode() -- 将str转为bytes,例:
s1 = 'tangtang'.encode() s2 = '糖糖'.encode() print(s1) print(s2)
结果:


















 1760
1760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









