







 本文详细探讨了HashMap在并发环境下的问题,如元素丢失和死循环,并介绍了单线程resize过程。JDK8对HashMap进行了优化,包括链表转红黑树、优化插入方式以及改进扩容机制。此外,文章还解答了HashMap扩容条件和计算索引的方法等常见问题。
本文详细探讨了HashMap在并发环境下的问题,如元素丢失和死循环,并介绍了单线程resize过程。JDK8对HashMap进行了优化,包括链表转红黑树、优化插入方式以及改进扩容机制。此外,文章还解答了HashMap扩容条件和计算索引的方法等常见问题。
本文经授权转载自微信公众号:全菜工程师小辉
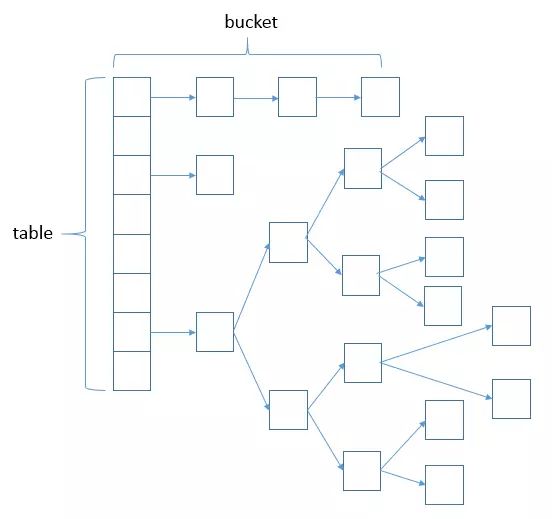
HashMap使用链表法避免哈希冲突(相同hash值),当链表长度大于TREEIFY_THRESHOLD(默认为8)时,将链表转换为红黑树。当小于等于UNTREEIFY_THRESHOLD(默认为6)时,又会退化回链表以达到性能均衡。 下图为HashMap的数据结构(数组+链表+红黑树 )
HashMap在并发时出现的问题
1.多线程put的时候可能导致元素丢失
主要问题出在addEntry方法的new Entry (hash, key, value, e),如果两个线程都同时取得了e,则他们下一个元素都是e,然后赋值给table元素的时候有一个成功有一个丢失。
2.多线程put后可能导致get死循环
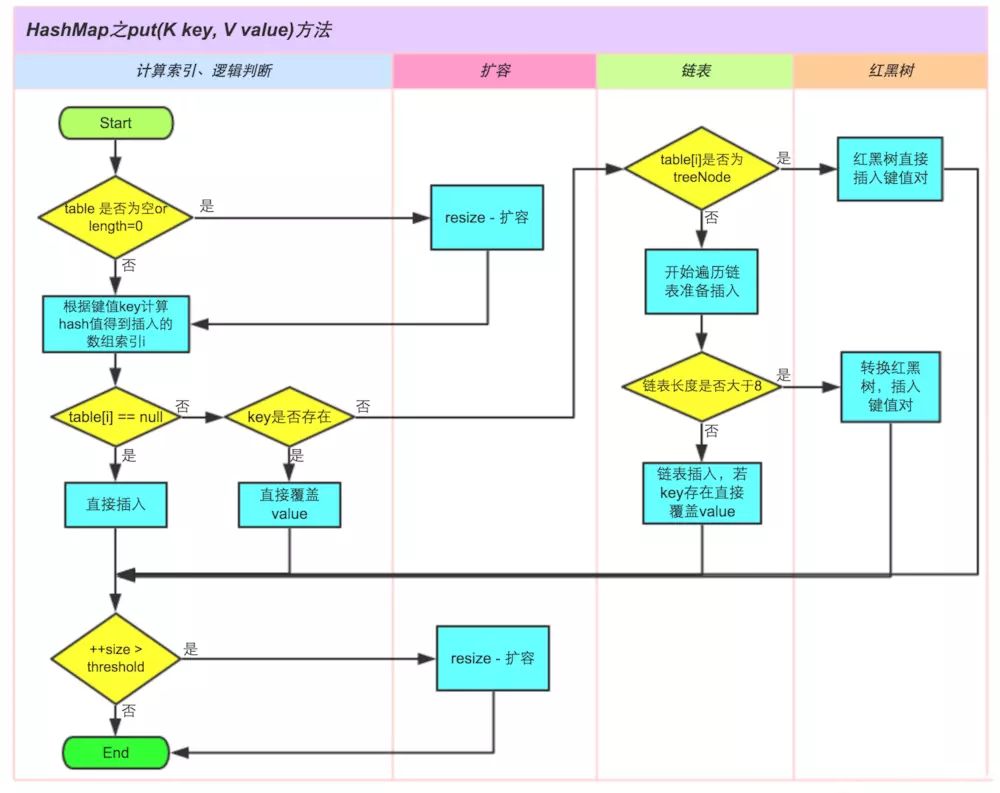
造成死循环的原因是多线程进行put操作时,触发了HashMap的扩容(resize函数),出现链表的两个结点形成闭环,导致死循环。下图为JDK8中的put操作流程,详情请自行查看源码。
单线程resize过程
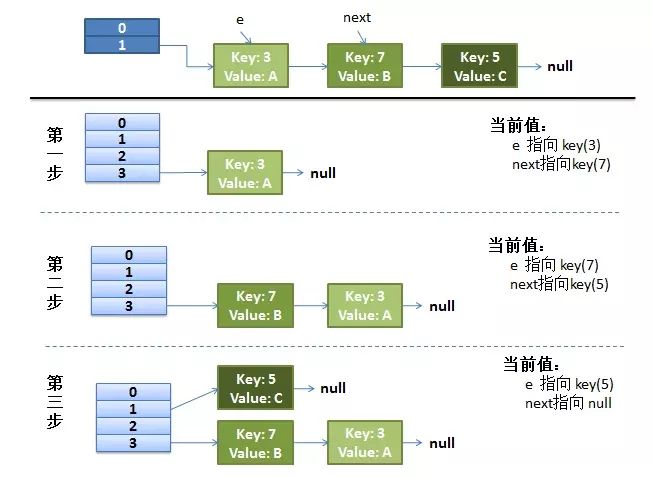
首先我们把resize函数中的transfer()的关键代码贴出来:
while(null != e) {
Entrynext = e.next; if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next;}我们可以再简化一下,因为中间的i就是判断新表的位置,我们可以跳过。简化后代码
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3348
3348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









