




简介:学生管理系统是一种用于管理学生基本信息、成绩、出勤和课程安排的应用软件,广泛应用于教育机构。本系统代码实现学生信息管理的核心功能:增删改查。通过数据库操作(如SQL语句),系统可添加学生记录、删除无效数据、更新信息以及多条件查询。系统采用面向对象设计和MVC架构,使用MySQL或SQLite等关系型数据库,注重代码可维护性、扩展性与安全性。本项目适合软件开发初学者实践数据库操作、前后端交互及权限控制等内容,是掌握基础管理系统开发的理想入门项目。
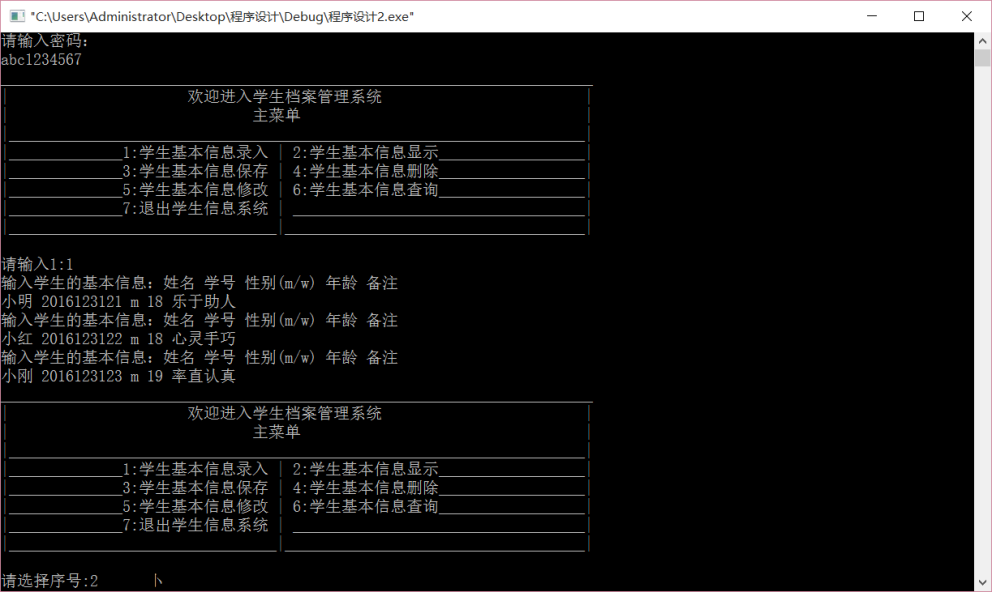
1. 学生管理系统功能概述
学生管理系统是教育信息化建设中的核心组成部分,广泛应用于学校、培训机构等教育单位,用于高效、规范地管理学生的基本信息。系统的核心功能包括学生信息的增删改查,通过数字化手段替代传统纸质记录,提高数据处理效率和准确性。
从功能结构来看,系统通常由多个模块组成,包括用户权限管理、信息录入、数据维护、查询统计等,各模块之间相互协作,实现数据的统一管理与安全控制。开发目标不仅在于满足基本业务需求,还包括提升系统的稳定性、可扩展性与用户体验。
本章将围绕系统整体功能需求展开,帮助读者建立对系统设计背景、业务流程和应用场景的全面认知,为后续模块的开发与实现奠定坚实基础。
2. 学生信息添加功能设计与实现
学生信息添加功能是学生管理系统中最基础也是最关键的功能之一,它为整个系统提供了数据来源的起点。在实际开发中,该模块不仅要完成数据的收集与存储,还需要考虑输入校验、用户交互、异常处理、性能优化等多个方面。本章将围绕学生信息添加功能的设计与实现展开详细探讨,内容涵盖需求分析、代码实现、异常处理、测试验证等多个维度,帮助读者全面掌握该功能的开发流程与技术要点。
2.1 学生信息添加模块的需求分析
学生信息添加模块的设计需要从功能需求与用户体验两个层面出发,确保数据输入的准确性与系统的可用性。
2.1.1 输入字段的定义与校验规则
在添加学生信息时,通常需要收集以下核心字段:
| 字段名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
| 学号 | VARCHAR | 唯一标识学生 | 是 |
| 姓名 | VARCHAR | 学生姓名 | 是 |
| 性别 | CHAR | 男/女 | 是 |
| 出生日期 | DATE | 学生出生年月日 | 否 |
| 所属班级 | VARCHAR | 所在班级名称 | 是 |
| 联系电话 | VARCHAR | 学生联系电话 | 否 |
| 家庭住址 | TEXT | 学生家庭住址 | 否 |
这些字段在前端界面中通常以表单形式呈现,后端则需对输入内容进行严格的校验。例如,学号必须唯一且格式正确,性别只能是“男”或“女”,电话号码必须符合手机号格式等。
// 示例:Java后端对输入字段进行基本校验
public boolean validateStudentInput(String studentId, String name, String gender) {
if (studentId == null || studentId.isEmpty()) {
System.out.println("学号不能为空");
return false;
}
if (name == null || name.isEmpty()) {
System.out.println("姓名不能为空");
return false;
}
if (!gender.equals("男") && !gender.equals("女")) {
System.out.println("性别必须为男或女");
return false;
}
return true;
}
代码逻辑分析:
-
studentId、name、gender分别对应学号、姓名和性别字段。 - 使用
if判断语句检查字段是否为空或不符合格式要求。 - 若任一字段不符合要求,则输出提示信息并返回
false,表示校验失败。 - 所有校验通过则返回
true。
参数说明:
-
studentId:学生唯一标识符,用于数据库唯一性约束。 -
name:学生姓名,用于展示和检索。 -
gender:性别字段,控制值域范围。
2.1.2 用户交互界面设计
用户交互界面是学生信息添加模块的前端部分,通常使用HTML+CSS+JavaScript构建。设计上应注重简洁、易用和友好性,提升用户体验。
<!-- 示例:学生信息添加表单 -->
<form id="studentForm">
<label>学号:<input type="text" id="studentId" required></label><br>
<label>姓名:<input type="text" id="name" required></label><br>
<label>性别:
<select id="gender">
<option value="男">男</option>
<option value="女">女</option>
</select>
</label><br>
<label>出生日期:<input type="date" id="birthDate"></label><br>
<label>所属班级:<input type="text" id="className" required></label><br>
<label>联系电话:<input type="tel" id="phone"></label><br>
<label>家庭住址:<input type="text" id="address"></label><br>
<button type="submit">提交</button>
</form>
代码逻辑分析:
- 使用
<form>标签构建表单结构。 -
required属性用于浏览器端的基本输入校验。 -
<select>控件限制性别字段只能选择“男”或“女”。 - 提交按钮触发表单提交事件,将数据传递至后端接口。
参数说明:
-
id属性用于JavaScript获取DOM元素,进行数据收集与验证。 -
type="tel"和type="date"用于移动端优化输入体验。
graph TD
A[用户打开添加页面] --> B[填写学生信息]
B --> C[点击提交按钮]
C --> D{前端校验是否通过}
D -- 是 --> E[发送请求至后端]
D -- 否 --> F[提示错误信息并返回]
E --> G{后端是否成功处理}
G -- 是 --> H[提示添加成功]
G -- 否 --> I[提示系统错误]
2.2 添加功能的代码实现
学生信息添加功能的核心在于表单数据的获取与处理,以及将数据写入数据库。这一过程需要前后端协作,确保数据完整性和一致性。
2.2.1 表单数据的获取与处理
前端获取用户输入后,通常通过AJAX将数据发送至后端API接口。以下是一个使用JavaScript的示例:
// 示例:前端获取表单数据并发送至后端
document.getElementById('studentForm').addEventListener('submit', function(e) {
e.preventDefault(); // 阻止表单默认提交行为
const formData = new FormData(this);
const data = {};
formData.forEach((value, key) => data[key] = value);
fetch('/api/student/add', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(data)
})
.then(response => response.json())
.then(result => {
if (result.success) {
alert('学生信息添加成功');
} else {
alert('添加失败:' + result.message);
}
})
.catch(error => console.error('Error:', error));
});
代码逻辑分析:
- 使用
FormData对象收集表单数据。 - 通过
fetch方法向后端/api/student/add接口发送POST请求。 - 使用
JSON.stringify将对象转换为JSON格式,便于后端解析。 - 接收响应后判断是否成功,并弹出提示信息。
参数说明:
-
method: 'POST'表示使用POST方式提交数据。 -
headers设置请求头,指定数据类型为JSON。 -
body为请求体,即发送的学生信息数据。
2.2.2 数据写入数据库的流程
后端接收到请求后,需将数据写入数据库。以下是一个使用Node.js和MySQL的示例:
// 示例:Node.js写入学生信息到MySQL数据库
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'root',
password: 'password',
database: 'student_db'
});
app.post('/api/student/add', (req, res) => {
const student = req.body;
const query = `INSERT INTO students (student_id, name, gender, birth_date, class_name, phone, address)
VALUES (?, ?, ?, ?, ?, ?, ?)`;
connection.query(query, [
student.studentId,
student.name,
student.gender,
student.birthDate,
student.className,
student.phone,
student.address
], (error, results) => {
if (error) {
return res.status(500).json({ success: false, message: error.message });
}
res.json({ success: true, message: '学生信息已添加' });
});
});
代码逻辑分析:
- 使用
mysql模块连接数据库。 - 接收前端POST请求后,从
req.body获取学生信息。 - 构造SQL语句,使用预编译方式插入数据,防止SQL注入。
- 执行插入操作,成功则返回成功提示,否则返回错误信息。
参数说明:
-
student.studentId等字段为从前端传来的数据。 -
query为插入语句,使用占位符?提高安全性。 -
connection.query执行SQL语句,传入参数数组。
graph TD
A[前端发送POST请求] --> B[后端接收请求]
B --> C[解析JSON数据]
C --> D[构建SQL语句]
D --> E[执行数据库插入]
E --> F{插入是否成功}
F -- 是 --> G[返回成功响应]
F -- 否 --> H[返回错误信息]
2.3 添加功能的异常处理与优化
学生信息添加功能在实际运行中可能会遇到各种异常情况,如网络中断、数据库连接失败、数据重复等。因此,良好的异常处理机制和优化策略至关重要。
2.3.1 常见错误类型与日志记录
常见的错误类型包括:
| 错误类型 | 描述 |
|---|---|
| 数据库连接失败 | 数据库服务未启动或配置错误 |
| 字段校验失败 | 学号重复、电话格式错误等 |
| 网络超时 | 请求响应时间过长或中断 |
| SQL语法错误 | SQL语句拼接错误或字段名错误 |
为了便于排查问题,系统应记录详细的日志信息:
// 示例:Node.js中使用Winston记录日志
const winston = require('winston');
const logger = winston.createLogger({
level: 'debug',
format: winston.format.json(),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'error.log', level: 'error' }),
new winston.transports.File({ filename: 'combined.log' })
]
});
app.post('/api/student/add', (req, res) => {
try {
// ... 插入数据库的代码
} catch (err) {
logger.error(`添加学生信息失败:${err.message}`, { stack: err.stack });
res.status(500).json({ success: false, message: '系统内部错误' });
}
});
代码逻辑分析:
- 使用
winston库记录日志,支持控制台与文件输出。 - 在
try...catch块中捕获异常并记录日志。 - 记录异常信息及堆栈跟踪,便于后续排查。
参数说明:
-
level表示日志级别,如error、info、debug。 -
transports指定日志输出方式,如控制台、文件等。
2.3.2 数据重复性校验机制
为了避免重复添加学生信息,特别是学号冲突问题,系统应在添加前进行唯一性校验:
// 示例:添加前检查学号是否存在
function checkStudentIdExists(studentId, callback) {
const query = 'SELECT COUNT(*) AS count FROM students WHERE student_id = ?';
connection.query(query, [studentId], (error, results) => {
if (error) return callback(error);
callback(null, results[0].count > 0);
});
}
app.post('/api/student/add', (req, res) => {
const student = req.body;
checkStudentIdExists(student.studentId, (error, exists) => {
if (error) {
return res.status(500).json({ success: false, message: '学号校验失败' });
}
if (exists) {
return res.status(400).json({ success: false, message: '学号已存在' });
}
// 继续插入数据
});
});
代码逻辑分析:
- 定义
checkStudentIdExists函数,查询学号是否存在。 - 若存在,则返回提示“学号已存在”。
- 若不存在,则继续执行插入操作。
参数说明:
-
studentId:用于查询的学号字段。 -
callback:异步回调函数,用于返回校验结果。
graph TD
A[提交学生信息] --> B[校验学号是否存在]
B --> C{学号是否存在}
C -- 是 --> D[返回学号重复错误]
C -- 否 --> E[执行数据库插入]
2.4 添加功能的测试与验证
为了确保学生信息添加功能的稳定性和可靠性,必须进行充分的测试。测试主要包括单元测试和集成测试,涵盖正常流程和异常场景。
2.4.1 单元测试与集成测试方法
使用Jest进行单元测试示例:
// 示例:使用Jest进行学生添加接口的单元测试
const request = require('supertest');
const app = require('../app');
test('添加学生信息成功', async () => {
const response = await request(app)
.post('/api/student/add')
.send({
studentId: '2023001',
name: '张三',
gender: '男',
className: '三年级一班'
});
expect(response.body.success).toBe(true);
});
test('学号重复添加失败', async () => {
const response = await request(app)
.post('/api/student/add')
.send({
studentId: '2023001',
name: '李四',
gender: '女',
className: '三年级二班'
});
expect(response.body.success).toBe(false);
});
代码逻辑分析:
- 使用
supertest模拟HTTP请求。 - 测试添加成功和失败两种情况。
- 通过
expect断言返回结果是否符合预期。
参数说明:
-
request(app):模拟向app发送请求。 -
.send():发送POST请求体。 -
expect():断言返回结果。
2.4.2 测试用例设计与执行
测试用例设计应覆盖以下场景:
| 测试用例编号 | 描述 | 预期结果 |
|---|---|---|
| TC001 | 正常添加学生信息 | 添加成功 |
| TC002 | 学号为空 | 返回错误提示 |
| TC003 | 学号重复 | 返回重复提示 |
| TC004 | 性别字段非法 | 返回校验失败 |
| TC005 | 数据库连接失败 | 返回系统错误 |
graph TD
A[测试用例准备] --> B[执行测试]
B --> C{测试是否通过}
C -- 是 --> D[记录通过结果]
C -- 否 --> E[记录失败原因]
3. 学生信息删除功能设计与实现
在学生管理系统中,删除功能作为核心操作之一,承担着清理冗余数据、维护系统整洁性的重要职责。与添加和查询操作不同,删除操作具有不可逆性,因此在设计和实现过程中需要格外谨慎,尤其是在权限控制、确认机制、事务管理以及异常处理等方面。本章将围绕删除功能的业务需求、实现逻辑、安全性保障及测试验证四个方面,深入剖析其设计与实现过程。
3.1 删除功能的需求与业务逻辑
删除功能不仅仅是从数据库中移除一条记录那么简单,它涉及权限控制、用户确认、数据安全、日志记录等多个维度。良好的删除机制不仅能够防止误操作,还能提升系统的健壮性和用户体验。
3.1.1 删除操作的权限与条件限制
在多用户系统中,删除操作通常需要严格的权限控制。例如,普通用户可能只能删除自己的信息,而管理员可以删除任意学生记录。此外,系统还需要根据业务规则设定删除条件,例如:
- 软删除限制 :某些系统采用逻辑删除,即在数据表中增加一个状态字段(如
is_deleted),而不是真正删除记录。 - 关联数据限制 :如果某学生有相关的成绩、选课等记录,直接删除可能导致数据不一致。
| 权限等级 | 可执行操作 | 删除限制条件 |
|---|---|---|
| 普通用户 | 删除自己的信息 | 仅限本人,且无关联数据 |
| 教师 | 删除所教班级的学生信息 | 仅限当前班级,且无成绩记录 |
| 管理员 | 删除任意学生信息 | 需二次确认,支持软删除或硬删除 |
3.1.2 确认机制与数据备份策略
为了避免误删操作,系统通常采用以下策略:
- 前端确认弹窗 :在用户点击“删除”按钮后,弹出二次确认框,要求用户再次确认。
- 后台日志记录 :所有删除操作应记录操作人、时间、删除内容,便于审计和恢复。
- 数据备份机制 :可采用定期备份、删除前快照等方式,确保删除数据可恢复。
graph TD
A[用户点击删除按钮] --> B{是否启用软删除?}
B -->|是| C[更新is_deleted字段]
B -->|否| D[物理删除记录]
D --> E[记录删除日志]
C --> F[记录状态变更日志]
E --> G[备份删除数据]
3.2 删除功能的编码实现
在实现删除功能时,从前端到后端再到数据库,每一步都需要严谨的逻辑处理。下面将从删除请求的接收与解析、数据库记录的删除方式两个方面展开。
3.2.1 删除请求的接收与解析
在 Web 系统中,删除请求通常由前端通过 HTTP DELETE 方法发送。以 Spring Boot 框架为例,控制器接收请求如下:
@RestController
@RequestMapping("/students")
public class StudentController {
@Autowired
private StudentService studentService;
@DeleteMapping("/{id}")
public ResponseEntity<String> deleteStudent(@PathVariable Long id) {
try {
studentService.deleteStudentById(id);
return ResponseEntity.ok("删除成功");
} catch (Exception e) {
return ResponseEntity.status(500).body("删除失败:" + e.getMessage());
}
}
}
逐行分析:
-
@RestController:表示该类为控制器,返回值直接作为响应体。 -
@RequestMapping("/students"):统一前缀为/students。 -
@DeleteMapping("/{id}"):映射 DELETE 请求,路径参数为学生 ID。 -
@PathVariable Long id:接收路径参数并转换为 Long 类型。 -
studentService.deleteStudentById(id):调用业务层删除方法。 -
try-catch:捕获异常,返回友好的错误信息。
3.2.2 数据库记录的物理与逻辑删除实现
根据系统需求,可以选择物理删除或逻辑删除。以下是两种方式的实现代码:
物理删除(硬删除)
public void deleteStudentById(Long id) {
String sql = "DELETE FROM students WHERE id = ?";
try (PreparedStatement stmt = connection.prepareStatement(sql)) {
stmt.setLong(1, id);
stmt.executeUpdate();
} catch (SQLException e) {
logger.error("物理删除失败:", e);
throw new RuntimeException("删除失败");
}
}
逻辑删除(软删除)
public void softDeleteStudentById(Long id) {
String sql = "UPDATE students SET is_deleted = 1 WHERE id = ?";
try (PreparedStatement stmt = connection.prepareStatement(sql)) {
stmt.setLong(1, id);
stmt.executeUpdate();
} catch (SQLException e) {
logger.error("逻辑删除失败:", e);
throw new RuntimeException("软删除失败");
}
}
参数说明:
-
connection:数据库连接对象。 -
is_deleted:表示删除状态,1 为已删除,0 为正常。 -
PreparedStatement:用于防止 SQL 注入,提高执行效率。
3.3 删除操作的安全性保障
删除操作具有破坏性,因此必须从多个层面保障其安全性,包括用户确认机制、事务控制、权限校验等。
3.3.1 删除前的确认机制实现
前端实现删除确认机制通常使用 JavaScript 弹窗:
<button onclick="confirmDelete(123)">删除</button>
<script>
function confirmDelete(studentId) {
if (confirm("确定要删除该学生信息吗?")) {
fetch(`/students/${studentId}`, {
method: 'DELETE',
headers: { 'Content-Type': 'application/json' }
})
.then(response => response.text())
.then(data => alert(data))
.catch(error => console.error('Error:', error));
}
}
</script>
逻辑说明:
-
confirm():弹出确认对话框。 -
fetch():发送 DELETE 请求。 -
headers:设置请求头为 JSON 格式。
3.3.2 删除操作的事务控制
在涉及多表操作或级联删除时,事务控制是必不可少的。以下是一个使用事务控制的逻辑删除示例:
public void deleteStudentWithTransaction(Long id) throws SQLException {
Connection conn = null;
PreparedStatement stmt = null;
try {
conn = dataSource.getConnection();
conn.setAutoCommit(false); // 关闭自动提交
String updateSql = "UPDATE students SET is_deleted = 1 WHERE id = ?";
stmt = conn.prepareStatement(updateSql);
stmt.setLong(1, id);
stmt.executeUpdate();
// 可选:删除关联数据
String deleteRelated = "DELETE FROM scores WHERE student_id = ?";
stmt = conn.prepareStatement(deleteRelated);
stmt.setLong(1, id);
stmt.executeUpdate();
conn.commit(); // 提交事务
} catch (SQLException e) {
if (conn != null) {
conn.rollback(); // 回滚事务
}
logger.error("事务删除失败:", e);
throw e;
} finally {
if (stmt != null) stmt.close();
if (conn != null) conn.close();
}
}
参数说明:
-
setAutoCommit(false):手动控制事务。 -
commit():提交事务。 -
rollback():回滚事务,防止数据不一致。
3.4 删除功能的测试与验证
测试是删除功能开发流程中不可或缺的一环,主要涵盖边界测试与性能评估两个方面。
3.4.1 删除功能的边界测试
边界测试用于验证删除操作在极端情况下的表现,包括:
- 删除不存在的学生 ID(如负数、超大数字)
- 删除已删除的学生(逻辑删除后再次删除)
- 删除存在关联记录的学生(如已存在成绩记录)
- 多用户并发删除同一记录
@Test
public void testDeleteNonExistentStudent() {
Long id = 999999L;
assertThrows(RuntimeException.class, () -> studentService.deleteStudentById(id));
}
测试说明:
- 使用 JUnit 框架进行单元测试。
-
assertThrows:验证是否抛出预期异常。 -
id = 999999L:模拟不存在的学生 ID。
3.4.2 删除操作的性能评估
在大规模数据量下,删除操作的性能尤为重要。可以通过以下方式评估:
| 测试项 | 工具/方法 | 评估指标 |
|---|---|---|
| 单条删除耗时 | JMeter、Spring AOP日志 | 平均响应时间、吞吐量 |
| 批量删除性能 | 批量 SQL 或存储过程 | 每秒处理条数 |
| 并发删除稳定性 | 多线程模拟、JMeter压力测试 | 错误率、系统资源占用 |
| 事务提交效率 | 数据库事务日志分析 | 提交时间、锁等待时间 |
graph LR
A[开始性能测试] --> B[单条删除测试]
A --> C[批量删除测试]
A --> D[并发删除测试]
B --> E[记录响应时间]
C --> F[记录吞吐量]
D --> G[记录错误率]
E --> H[生成性能报告]
F --> H
G --> H
通过本章的学习,我们深入理解了学生信息删除功能的业务逻辑、实现细节、安全性保障机制以及测试策略。在实际开发中,删除操作虽看似简单,但其背后涉及的技术点却非常丰富,尤其是在权限控制、事务管理、数据一致性等方面。下一章我们将继续探讨学生信息的修改功能,进一步提升系统交互的完整性与灵活性。
4. 学生信息修改功能设计与实现
学生信息修改功能是学生管理系统中的核心操作之一,用于更新已有的学生信息。与添加和删除功能相比,修改功能不仅需要读取和展示已有数据,还需要在用户提交后完成数据的更新操作。因此,该功能的设计与实现对系统的稳定性、安全性、用户体验提出了更高的要求。本章将从修改功能的业务需求出发,深入分析其前后端交互流程,并通过代码实现、异常处理机制以及测试与优化策略,完整呈现修改功能的开发全过程。
4.1 修改功能的业务需求与流程分析
修改功能的实现必须基于明确的业务需求和合理的流程设计。在教育系统中,学生信息的修改通常受到权限限制,不同角色(如教师、管理员)可修改的字段范围不同,同时修改流程必须保证数据的完整性和一致性。
4.1.1 修改字段的权限控制
在实际业务中,不同用户角色对信息的修改权限不同。例如,普通教师可能只能修改学生的成绩信息,而管理员可以修改学生的基本信息、联系方式等。
| 角色类型 | 可修改字段 |
|---|---|
| 教师 | 成绩、评价 |
| 管理员 | 姓名、学号、性别、出生日期、联系方式、成绩、评价 |
| 学生本人 | 联系方式、密码 |
这种权限控制机制通常在系统中通过角色权限配置来实现,前端界面根据用户角色动态渲染可编辑字段,后端接口在接收到请求时再次校验用户的操作权限。
4.1.2 修改流程的前后端交互设计
修改流程包括以下几个关键步骤:
graph TD
A[用户点击“编辑”按钮] --> B[前端发送GET请求加载学生信息]
B --> C[后端返回学生信息JSON数据]
C --> D[前端渲染表单并允许用户编辑]
D --> E[用户提交修改数据]
E --> F[前端发送PUT请求更新数据]
F --> G[后端验证数据并执行数据库更新]
G --> H{更新是否成功}
H -- 是 --> I[返回成功响应]
H -- 否 --> J[返回错误信息]
该流程图展示了修改功能从用户操作到后端处理的完整交互逻辑,为后续编码实现提供了清晰的蓝图。
4.2 修改功能的编码实现
为了实现修改功能,我们需要从前端表单的加载开始,到后端数据的更新完成,整个过程都需要精确的数据处理与交互。
4.2.1 表单回显与数据加载
前端在用户点击“编辑”按钮后,需发送GET请求获取学生信息,用于表单回显。以下是一个使用Vue.js框架实现的前端代码示例:
// StudentEdit.vue
export default {
data() {
return {
student: {
id: '',
name: '',
gender: '',
birthday: '',
phone: '',
grade: '',
remark: ''
}
}
},
mounted() {
this.loadStudentInfo();
},
methods: {
async loadStudentInfo() {
const id = this.$route.params.id;
const response = await axios.get(`/api/students/${id}`);
this.student = response.data;
}
}
}
代码逻辑分析:
-
data中定义了学生信息对象student,用于绑定表单字段。 -
mounted钩子函数在组件挂载时调用loadStudentInfo方法。 -
loadStudentInfo方法通过axios发送GET请求,根据路由参数id获取学生信息。 - 获取到数据后,将返回的JSON数据赋值给
student对象,用于表单回显。
4.2.2 修改后的数据提交与更新
当用户完成修改并提交数据时,前端需将数据发送到后端进行更新。以下是Node.js + Express后端接口的实现示例:
// studentController.js
const Student = require('../models/Student');
exports.updateStudent = async (req, res) => {
const { id } = req.params;
const updateData = req.body;
try {
const updatedStudent = await Student.findByIdAndUpdate(id, updateData, {
new: true,
runValidators: true
});
if (!updatedStudent) {
return res.status(404).json({ message: '学生信息未找到' });
}
res.status(200).json({ message: '修改成功', data: updatedStudent });
} catch (error) {
res.status(500).json({ message: '修改失败', error });
}
};
代码逻辑分析:
-
updateStudent函数接收请求参数id和请求体updateData。 - 使用Mongoose的
findByIdAndUpdate方法更新数据库记录。
-new: true表示返回更新后的文档。
-runValidators: true确保更新时执行模型定义的验证规则。 - 若未找到对应学生记录,返回404状态码。
- 成功更新后返回200状态码和更新后的数据。
- 捕获异常并返回500错误信息。
4.3 修改功能的异常处理
在修改功能中,异常处理是确保系统健壮性和数据一致性的重要环节。常见的异常包括数据库连接失败、字段冲突、权限不足等。
4.3.1 修改失败的回滚机制
在多字段更新或涉及多个表的修改操作中,若某一步骤失败,应进行事务回滚以保持数据一致性。以下是一个使用MongoDB事务管理的示例:
const session = await mongoose.startSession();
session.startTransaction();
try {
await Student.findByIdAndUpdate(id, updateData, { session });
// 可添加其他操作如日志记录等
await session.commitTransaction();
} catch (error) {
await session.abortTransaction();
res.status(500).json({ message: '修改失败,已回滚', error });
} finally {
session.endSession();
}
代码逻辑分析:
- 创建Mongoose事务会话并开启事务。
- 在事务中执行更新操作。
- 若操作成功,提交事务。
- 若出现异常,执行事务回滚。
- 最后关闭事务会话。
4.3.2 字段冲突检测与提示
字段冲突通常出现在并发修改场景中,例如两个用户同时修改同一学生信息。为避免数据覆盖,可在更新前添加版本号或时间戳校验:
const originalStudent = await Student.findById(id);
if (originalStudent.updatedAt.getTime() !== updateData.lastModifiedTime) {
return res.status(409).json({ message: '检测到数据已被其他用户修改,请刷新后重试' });
}
参数说明:
-
updatedAt:数据库中记录的最后更新时间。 -
lastModifiedTime:前端传来的上一次加载时间戳。 - 若两者不一致,说明数据已被修改,返回409冲突错误。
4.4 修改功能的测试与优化
为了确保修改功能的稳定性和高效性,需要进行充分的测试和性能优化。
4.4.1 修改操作的边界测试
边界测试用于验证系统在极端情况下的表现,包括:
| 测试用例 | 描述 | 预期结果 |
|---|---|---|
| 修改空字段 | 提交空数据 | 返回字段校验错误 |
| 修改不存在的学生ID | 提供无效ID | 返回404未找到错误 |
| 并发修改同一学生 | 多用户同时修改 | 返回冲突提示 |
| 修改超长字段 | 输入超过字段长度限制 | 返回字段校验错误 |
| 修改非本人数据 | 学生尝试修改他人信息 | 返回权限不足错误 |
4.4.2 修改流程的性能优化策略
为提升修改功能的响应速度和并发处理能力,可采取以下优化策略:
1. 缓存学生信息
在频繁修改的场景中,可使用Redis缓存学生信息,减少数据库查询次数:
const cachedStudent = await redis.get(`student:${id}`);
if (cachedStudent) {
return JSON.parse(cachedStudent);
}
const student = await Student.findById(id);
await redis.setex(`student:${id}`, 300, JSON.stringify(student)); // 缓存5分钟
2. 字段级更新优化
在某些情况下,用户仅修改部分字段。为提高效率,可采用字段级更新策略,仅更新实际修改的字段:
const updateData = {};
if (req.body.name) updateData.name = req.body.name;
if (req.body.phone) updateData.phone = req.body.phone;
await Student.findByIdAndUpdate(id, { $set: updateData }, { new: true });
3. 异步日志记录
在修改操作中,日志记录可异步执行,避免阻塞主流程:
const logUpdate = async () => {
await Log.create({
userId: req.user.id,
action: 'update_student',
details: updateData
});
};
logUpdate(); // 异步执行日志写入
这些优化手段不仅提升了系统的响应速度,也增强了系统的可扩展性和并发处理能力,为后续的高并发场景提供了保障。
5. 学生信息多条件查询设计与实现
学生信息管理系统中,查询功能是使用频率最高的核心模块之一。在实际业务中,用户往往需要根据多个条件(如姓名、学号、班级、性别、年龄区间等)组合查询学生信息。如何高效、准确地实现多条件查询,并在高并发场景下保持良好的性能,是系统开发中必须解决的关键问题。本章将围绕查询功能的需求分析、代码实现、性能优化与测试验证四个方面,深入探讨多条件查询的设计与实现。
5.1 查询功能的需求分析与设计
多条件查询的核心目标是根据用户输入的多个筛选条件,从学生信息表中筛选出符合条件的数据并返回结果。该功能的实现不仅需要考虑查询条件的灵活组合,还需设计良好的结果展示与分页机制。
5.1.1 查询条件的组合方式
为了支持灵活的查询方式,系统需支持以下组合逻辑:
- 单条件查询 :仅输入一个字段进行查询(如姓名、学号等)。
- 多条件并列查询 :多个字段同时输入,如“姓名=张三 AND 年龄>20”。
- 区间查询 :支持数值型字段的范围查询,如“年龄 BETWEEN 18 AND 25”。
- 模糊查询 :支持模糊匹配,如“姓名 LIKE %李%”。
在设计时,前端界面应提供多个输入框,后端则通过动态 SQL 构建查询语句,以适应不同组合的查询需求。
5.1.2 查询结果的展示与分页机制
查询结果应具备良好的可读性和交互性,常见设计包括:
- 字段展示 :显示学生的基本信息字段,如姓名、学号、性别、班级、出生日期等。
- 排序功能 :支持按学号、姓名、年龄等字段升序或降序排列。
- 分页机制 :每页展示固定数量的结果,避免一次性加载过多数据影响性能。
分页逻辑通常由后端控制,使用 LIMIT 和 OFFSET 实现数据分页,前端通过分页控件控制页码跳转。
5.2 查询功能的编码实现
本节将通过 Java + MySQL 的实现方式,展示多条件查询的后端逻辑处理流程,并结合动态 SQL 实现查询语句的拼接。
5.2.1 查询语句的动态拼接
在 Java 后端中,使用 MyBatis 框架可以很好地支持动态 SQL。以下是一个典型的动态查询 SQL 示例:
<!-- StudentMapper.xml -->
<select id="selectStudentsByConditions" parameterType="map" resultType="Student">
SELECT * FROM students
<where>
<if test="name != null and name != ''">
AND name LIKE CONCAT('%', #{name}, '%')
</if>
<if test="studentId != null and studentId != ''">
AND student_id = #{studentId}
</if>
<if test="gender != null">
AND gender = #{gender}
</if>
<if test="className != null and className != ''">
AND class_name = #{className}
</if>
<if test="minAge != null">
AND age >= #{minAge}
</if>
<if test="maxAge != null">
AND age <= #{maxAge}
</if>
</where>
ORDER BY student_id
LIMIT #{pageSize} OFFSET #{offset}
</select>
代码逻辑分析:
-
<where>标签会自动去除开头的AND或OR,避免 SQL 语法错误。 - 每个
<if>标签根据传入的参数是否为空来决定是否拼接对应的查询条件。 -
LIMIT #{pageSize} OFFSET #{offset}实现分页查询,其中pageSize表示每页数据条数,offset表示偏移量(从第几条开始取)。
参数说明:
| 参数名 | 类型 | 说明 |
|---|---|---|
| name | String | 姓名模糊匹配 |
| studentId | String | 学号精确匹配 |
| gender | String | 性别筛选(男/女) |
| className | String | 班级名称 |
| minAge | Integer | 年龄下限 |
| maxAge | Integer | 年龄上限 |
| pageSize | Integer | 每页显示记录数 |
| offset | Integer | 分页偏移量,计算公式为 (当前页码-1)*pageSize |
5.2.2 多条件筛选的后端逻辑处理
在 Java 服务层中,调用上述 SQL 的方法如下:
public List<Student> searchStudents(String name, String studentId, String gender, String className, Integer minAge, Integer maxAge, int pageNum, int pageSize) {
int offset = (pageNum - 1) * pageSize;
Map<String, Object> params = new HashMap<>();
params.put("name", name);
params.put("studentId", studentId);
params.put("gender", gender);
params.put("className", className);
params.put("minAge", minAge);
params.put("maxAge", maxAge);
params.put("pageSize", pageSize);
params.put("offset", offset);
return studentMapper.selectStudentsByConditions(params);
}
逻辑分析:
- 方法接收多个查询参数,允许部分参数为空。
- 通过
pageNum和pageSize计算offset,用于分页查询。 - 构建参数 Map 并调用 MyBatis 映射器方法,执行动态查询。
- 返回类型为
List<Student>,表示符合条件的学生信息集合。
5.3 查询性能优化与缓存机制
随着系统数据量的增长,频繁的数据库查询将导致性能下降。为此,需要引入缓存机制和优化策略,以提升查询效率。
5.3.1 查询结果的缓存策略
缓存可以显著减少数据库访问频率,提升响应速度。常见的缓存方案包括:
- 本地缓存 :使用 Guava Cache、Caffeine 等库实现本地缓存。
- 分布式缓存 :使用 Redis、Memcached 等分布式缓存系统,适用于多节点部署场景。
以下是一个基于 Redis 的缓存实现示例:
public List<Student> searchStudentsWithCache(String name, String studentId, String gender, String className, Integer minAge, Integer maxAge, int pageNum, int pageSize) {
String cacheKey = generateCacheKey(name, studentId, gender, className, minAge, maxAge, pageNum, pageSize);
List<Student> result = redisTemplate.opsForValue().get(cacheKey);
if (result == null) {
result = searchStudents(name, studentId, gender, className, minAge, maxAge, pageNum, pageSize);
redisTemplate.opsForValue().set(cacheKey, result, 5, TimeUnit.MINUTES); // 缓存5分钟
}
return result;
}
private String generateCacheKey(String name, String studentId, String gender, String className, Integer minAge, Integer maxAge, int pageNum, int pageSize) {
return String.format("student_search:%s:%s:%s:%s:%d:%d:%d:%d",
name, studentId, gender, className, minAge, maxAge, pageNum, pageSize);
}
逻辑分析:
-
generateCacheKey方法用于生成唯一的缓存键,确保不同查询条件的缓存相互隔离。 - 如果缓存命中(即缓存中存在结果),则直接返回缓存数据。
- 如果缓存未命中,则调用原始查询方法获取数据,并写入缓存,设置过期时间为 5 分钟。
5.3.2 高并发场景下的查询优化
在高并发场景中,查询请求频繁,可能造成数据库压力过大。为此,可以采取以下优化措施:
| 优化策略 | 实现方式 | 优势描述 |
|---|---|---|
| 数据库索引优化 | 在常用查询字段(如学号、姓名、班级)上建立索引 | 提升查询效率,减少全表扫描 |
| 查询缓存 | 使用 Redis 缓存热点查询结果 | 减少数据库访问,提升响应速度 |
| 异步查询 | 使用线程池或消息队列异步处理查询请求 | 避免阻塞主线程,提高系统吞吐量 |
| 查询限流 | 设置每秒最大查询请求数,超出则排队或拒绝 | 防止系统崩溃,保证服务稳定性 |
| 分库分表 | 对数据进行水平拆分,按学号或班级划分多个数据库/表 | 支持大规模数据处理,提高并发查询能力 |
Mermaid 流程图展示查询优化策略:
graph TD
A[用户发起查询] --> B{是否命中缓存?}
B -->|是| C[返回缓存结果]
B -->|否| D[进入数据库查询]
D --> E[检查索引命中情况]
E --> F{是否命中索引?}
F -->|是| G[快速返回结果]
F -->|否| H[全表扫描,性能下降]
H --> I[记录日志并触发优化机制]
I --> J[异步更新缓存]
J --> K[限流控制]
5.4 查询功能的测试与验证
为了确保查询功能的正确性与稳定性,必须进行充分的测试,包括功能测试与性能测试。
5.4.1 多条件查询的组合测试
我们设计多组测试用例,覆盖不同条件组合情况:
| 测试编号 | 查询条件组合 | 预期结果 |
|---|---|---|
| TC01 | 姓名=李四 | 返回所有姓名为“李四”的学生 |
| TC02 | 年龄>=20 AND 年龄<=25 | 返回年龄在20~25之间的学生 |
| TC03 | 姓名=张三 AND 班级=计算机科学与技术班 | 返回符合条件的学生列表 |
| TC04 | 班级=数学班 AND 性别=男 | 返回数学班中男生的学生列表 |
| TC05 | 班级=数学班 AND 性别=男 AND 年龄>=22 | 返回符合条件的学生列表 |
代码测试示例:
@Test
public void testSearchStudents() {
List<Student> result = studentService.searchStudents("张三", null, null, "计算机科学与技术班", 20, 25, 1, 10);
assertNotNull(result);
assertFalse(result.isEmpty());
for (Student student : result) {
assertEquals("张三", student.getName());
assertTrue(student.getClassName().contains("计算机科学与技术班"));
assertTrue(student.getAge() >= 20 && student.getAge() <= 25);
}
}
逻辑分析:
- 使用 JUnit 编写单元测试,模拟多条件查询场景。
- 断言结果不为空,且每条记录均满足查询条件。
- 可通过测试覆盖率工具(如 JaCoCo)评估测试覆盖率。
5.4.2 查询结果的准确性与性能评估
在实际部署环境中,应定期评估查询性能,确保系统在高负载下依然稳定。
| 指标名称 | 目标值 | 评估方式 |
|---|---|---|
| 查询响应时间 | ≤200ms | 使用 APM 工具(如 SkyWalking)监控 |
| 查询成功率 | ≥99.9% | 监控日志统计错误率 |
| 缓存命中率 | ≥80% | Redis 缓存命中率统计 |
| 并发查询能力 | ≥500QPS | 使用 JMeter 压力测试 |
| 数据一致性验证 | 实时性误差 ≤1分钟 | 与数据库实时查询对比 |
性能测试代码示例(使用 JMeter):
- 创建线程组,设置线程数为 100,循环次数为 10。
- 添加 HTTP 请求,模拟多条件查询接口请求。
- 添加监听器,查看响应时间、吞吐量、错误率等指标。
通过本章的系统性讲解与代码示例,我们深入分析了学生信息多条件查询功能的业务需求、实现方式、性能优化策略以及测试验证流程。下一章将继续深入数据库设计与 SQL 操作实战,进一步提升系统开发的专业能力。
6. 数据库设计与SQL操作实战
在学生管理系统的开发过程中,数据库作为数据存储与访问的核心模块,其设计质量和SQL操作的规范性直接决定了系统的性能、可维护性与扩展性。本章将从数据库设计规范入手,深入讲解数据库表结构的构建原则、字段定义方法与表间关系设计;接着分析系统中核心SQL语句的编写技巧,包括增删改查操作、多表联查与子查询的应用;随后探讨DAO层设计与SQL封装、事务控制等数据库操作的优化手段;最后深入讲解数据库性能调优与索引优化策略,帮助开发者构建高效、稳定、可扩展的数据库体系。
6.1 系统数据库设计规范
数据库设计是整个系统开发的基础,良好的数据库结构可以提升系统的稳定性、可读性与可维护性。本节将从表结构设计原则与字段定义、表之间的关联关系设计两个方面展开讲解。
6.1.1 表结构设计原则与字段定义
在设计学生管理系统数据库时,需遵循以下设计原则:
| 原则 | 说明 |
|---|---|
| 原子性 | 每个字段应具有单一含义,避免字段中存储多个值 |
| 唯一性 | 主键字段用于唯一标识每条记录,通常使用自增ID |
| 规范化 | 尽量遵循数据库第三范式,减少数据冗余 |
| 可扩展性 | 字段设计应预留扩展空间,如使用VARCHAR而非CHAR |
| 可读性 | 表名与字段名应具有业务含义,命名统一规范 |
以学生信息表为例,其字段设计如下:
CREATE TABLE student (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '学生ID',
name VARCHAR(50) NOT NULL COMMENT '姓名',
gender ENUM('男', '女') NOT NULL COMMENT '性别',
birth_date DATE NOT NULL COMMENT '出生日期',
class_id INT NOT NULL COMMENT '班级ID',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='学生信息表';
代码逻辑分析:
-
id是主键字段,采用自增方式,确保每条记录的唯一性。 -
name存储学生姓名,设置为VARCHAR(50),避免浪费存储空间。 -
gender使用ENUM类型限制性别取值范围,提高数据一致性。 -
birth_date存储出生日期,采用DATE类型。 -
class_id作为外键字段,用于关联班级信息表。 -
create_time和update_time自动记录记录的创建和更新时间。
6.1.2 表之间的关联关系设计
学生管理系统中,常见的实体包括学生、班级、教师、课程等,这些实体之间存在多种关联关系:
- 学生与班级 :多对一(多个学生属于一个班级)
- 学生与课程 :多对多(学生可以选修多门课程,课程可以被多个学生选修)
- 教师与课程 :一对多(一位教师可以教授多门课程)
以下为班级信息表的结构设计:
CREATE TABLE class_info (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '班级ID',
class_name VARCHAR(50) NOT NULL UNIQUE COMMENT '班级名称',
grade VARCHAR(20) NOT NULL COMMENT '年级',
teacher_id INT NOT NULL COMMENT '班主任ID',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='班级信息表';
代码逻辑分析:
-
class_name字段使用UNIQUE约束,确保班级名称唯一。 -
teacher_id用于关联教师表,实现班主任信息的管理。 -
grade表示班级所属年级,便于年级分类管理。
学生与班级之间的关系通过外键实现,如下所示:
ALTER TABLE student
ADD CONSTRAINT fk_class_id
FOREIGN KEY (class_id)
REFERENCES class_info(id)
ON DELETE CASCADE
ON UPDATE CASCADE;
代码逻辑分析:
- 添加外键约束
fk_class_id,将student表的class_id字段关联到class_info表的id字段。 - 设置级联删除和更新,确保主表数据变更时从表数据同步变更,避免数据不一致。
mermaid流程图:学生管理系统核心表结构关系图
erDiagram
student ||--o{ class_info : "属于"
student ||--o{ course_selection : "选修"
course_selection }|--|| course : "课程"
course ||--o{ teacher : "由教师教授"
6.2 数据库操作的核心SQL语句
掌握SQL语句是数据库操作的核心能力,本节将讲解系统中常用的增删改查操作,并介绍多表联查与子查询的实际应用场景。
6.2.1 增删改查的基础SQL实现
学生信息的增删改查是最基础的操作,以下为常见SQL语句示例:
插入学生信息:
INSERT INTO student (name, gender, birth_date, class_id)
VALUES ('张三', '男', '2005-08-15', 1);
查询学生信息:
SELECT id, name, gender, birth_date, class_id
FROM student
WHERE id = 1;
更新学生信息:
UPDATE student
SET name = '张三丰', birth_date = '2005-09-10'
WHERE id = 1;
删除学生信息:
DELETE FROM student
WHERE id = 1;
代码逻辑分析:
- 插入操作使用
INSERT INTO语句完成,字段值按顺序传入。 - 查询操作使用
SELECT指定字段,避免使用SELECT *,提高性能。 - 更新操作使用
UPDATE修改指定字段,注意使用WHERE条件避免全表更新。 - 删除操作同样需谨慎使用
WHERE条件,避免误删数据。
6.2.2 多表联查与子查询的使用
在学生管理系统中,常需跨表查询,如查询某个学生所选修的课程列表。
示例:查询学生张三的所有课程:
SELECT c.course_name
FROM student s
JOIN course_selection cs ON s.id = cs.student_id
JOIN course c ON cs.course_id = c.id
WHERE s.name = '张三';
代码逻辑分析:
- 使用
JOIN连接student、course_selection和course三张表。 -
student表的id与course_selection的student_id关联。 -
course_selection的course_id与course表的id关联。 - 通过
WHERE条件筛选出“张三”的选课记录。
子查询示例:查询选修了“数学”课程的所有学生:
SELECT s.name
FROM student s
WHERE s.id IN (
SELECT cs.student_id
FROM course_selection cs
JOIN course c ON cs.course_id = c.id
WHERE c.course_name = '数学'
);
代码逻辑分析:
- 子查询部分查找所有选修“数学”课程的学生ID。
- 外层查询根据这些ID查询学生姓名。
- 使用
IN操作符实现多值匹配,避免逐条判断。
6.3 数据库操作的封装与优化
在系统开发中,直接编写SQL语句不利于代码维护和复用,因此需要进行封装与优化。本节将讲解DAO层设计、SQL语句封装、批量操作与事务控制等优化策略。
6.3.1 DAO层设计与SQL语句封装
DAO(Data Access Object)层负责与数据库交互,实现数据的持久化与读取。以下是学生信息DAO的Java示例:
public class StudentDAO {
private Connection connection;
public StudentDAO(Connection connection) {
this.connection = connection;
}
public void addStudent(Student student) throws SQLException {
String sql = "INSERT INTO student (name, gender, birth_date, class_id) VALUES (?, ?, ?, ?)";
try (PreparedStatement stmt = connection.prepareStatement(sql)) {
stmt.setString(1, student.getName());
stmt.setString(2, student.getGender());
stmt.setDate(3, new java.sql.Date(student.getBirthDate().getTime()));
stmt.setInt(4, student.getClassId());
stmt.executeUpdate();
}
}
public Student getStudentById(int id) throws SQLException {
String sql = "SELECT * FROM student WHERE id = ?";
try (PreparedStatement stmt = connection.prepareStatement(sql)) {
stmt.setInt(1, id);
ResultSet rs = stmt.executeQuery();
if (rs.next()) {
return new Student(
rs.getInt("id"),
rs.getString("name"),
rs.getString("gender"),
rs.getDate("birth_date"),
rs.getInt("class_id")
);
}
}
return null;
}
}
代码逻辑分析:
-
addStudent方法使用PreparedStatement插入学生数据,防止SQL注入。 -
getStudentById方法通过PreparedStatement查询学生信息。 - 使用
try-with-resources自动关闭资源,避免内存泄漏。 - DAO层将SQL操作封装,提高代码复用性与可维护性。
6.3.2 批量操作与事务控制
在处理大量数据时,使用批量操作和事务控制可以显著提升性能与数据一致性。
批量插入学生信息示例:
public void batchAddStudents(List<Student> students) throws SQLException {
String sql = "INSERT INTO student (name, gender, birth_date, class_id) VALUES (?, ?, ?, ?)";
try (PreparedStatement stmt = connection.prepareStatement(sql)) {
for (Student student : students) {
stmt.setString(1, student.getName());
stmt.setString(2, student.getGender());
stmt.setDate(3, new java.sql.Date(student.getBirthDate().getTime()));
stmt.setInt(4, student.getClassId());
stmt.addBatch();
}
stmt.executeBatch();
}
}
代码逻辑分析:
- 使用
addBatch()添加多个插入操作。 - 调用
executeBatch()一次性提交所有插入操作,减少数据库交互次数。 - 提升插入效率,适用于批量导入学生数据。
事务控制示例:修改学生信息并记录日志:
public void updateStudentWithLog(Student student, String logMessage) throws SQLException {
connection.setAutoCommit(false); // 关闭自动提交
try {
String updateSql = "UPDATE student SET name = ?, birth_date = ? WHERE id = ?";
try (PreparedStatement stmt = connection.prepareStatement(updateSql)) {
stmt.setString(1, student.getName());
stmt.setDate(2, new java.sql.Date(student.getBirthDate().getTime()));
stmt.setInt(3, student.getId());
stmt.executeUpdate();
}
String logSql = "INSERT INTO operation_log (student_id, action) VALUES (?, ?)";
try (PreparedStatement stmt = connection.prepareStatement(logSql)) {
stmt.setInt(1, student.getId());
stmt.setString(2, logMessage);
stmt.executeUpdate();
}
connection.commit(); // 提交事务
} catch (SQLException e) {
connection.rollback(); // 出错回滚
throw e;
} finally {
connection.setAutoCommit(true); // 恢复自动提交
}
}
代码逻辑分析:
- 使用事务确保更新操作与日志写入的原子性。
- 若更新失败,整个事务回滚,保证数据一致性。
- 适用于关键业务操作,如成绩修改、权限变更等场景。
6.4 数据库性能调优与索引优化
数据库性能直接影响系统的响应速度与并发能力,本节将分析常见的性能瓶颈,并讲解索引优化策略。
6.4.1 查询性能瓶颈分析
常见的性能瓶颈包括:
| 问题类型 | 表现 | 原因 |
|---|---|---|
| 慢查询 | 查询响应时间长 | 未使用索引、SQL语句复杂 |
| 高并发 | 系统响应迟缓 | 连接数过多、锁竞争 |
| 磁盘IO高 | 数据库读写频繁 | 缓存命中率低、频繁查询 |
示例:慢查询分析工具
使用 EXPLAIN 分析SQL执行计划:
EXPLAIN SELECT * FROM student WHERE name = '张三';
结果分析:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | student | ALL | NULL | NULL | NULL | NULL | 1000 | Using where |
分析结论:
-
type=ALL表示进行了全表扫描,效率低。 -
rows=1000表示需要扫描1000条记录,性能问题严重。
6.4.2 索引的合理使用与维护
索引是提升查询性能的重要手段,但使用不当可能导致写入性能下降或占用过多存储空间。
为学生姓名字段添加索引:
CREATE INDEX idx_student_name ON student(name);
再次执行EXPLAIN分析:
EXPLAIN SELECT * FROM student WHERE name = '张三';
结果分析:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | student | ref | idx_student_name | idx_student_name | 202 | const | 1 | Using where |
分析结论:
-
type=ref表示使用了索引查询。 -
rows=1表示仅扫描1条记录,性能大幅提升。
索引维护建议:
| 操作 | 建议 |
|---|---|
| 创建索引 | 在频繁查询字段上建立索引,如姓名、学号等 |
| 避免过多索引 | 不应在更新频繁的字段上建立索引,如日志表 |
| 定期分析表 | 使用 ANALYZE TABLE 更新索引统计信息 |
| 删除无用索引 | 使用 SHOW INDEX FROM table_name 查看索引使用情况 |
小贴士: 使用
SHOW STATUS LIKE 'Handler_read%';查看索引使用情况,确保Handler_read_key比Handler_read_rnd_next高,表示索引命中率高。
通过本章的学习,读者可以掌握学生管理系统中数据库设计规范、核心SQL操作、DAO层封装技巧以及性能调优方法,为构建高效、稳定的系统打下坚实基础。
7. 面向对象编程在系统开发中的应用
7.1 面向对象编程思想在系统中的体现
面向对象编程(Object-Oriented Programming,简称 OOP)是现代软件开发中广泛应用的一种编程范式,其核心思想是将数据和操作数据的方法封装在对象中。在学生管理系统中,OOP 的设计思想主要体现在实体类的设计与数据访问的映射上。
7.1.1 学生实体类的设计与封装
在系统中,学生信息是最核心的数据模型。我们可以使用一个 Student 类来封装学生的属性和行为。例如:
public class Student {
private String id;
private String name;
private int age;
private String gender;
private String className;
// 构造方法
public Student(String id, String name, int age, String gender, String className) {
this.id = id;
this.name = name;
this.age = age;
this.gender = gender;
this.className = className;
}
// Getter 和 Setter 方法
public String getId() { return id; }
public void setId(String id) { this.id = id; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
public String getGender() { return gender; }
public void setGender(String gender) { this.gender = gender; }
public String getClassName() { return className; }
public void setClassName(String className) { this.className = className; }
@Override
public String toString() {
return "Student{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", age=" + age +
", gender='" + gender + '\'' +
", className='" + className + '\'' +
'}';
}
}
上述 Student 类封装了学生的属性和行为,提高了数据的封装性和可维护性。通过构造方法和 Getter/Setter 方法,可以确保数据的安全访问。
7.1.2 对象与数据库记录的映射
在实际开发中,数据库表通常与实体类一一对应。例如,数据库中的 students 表结构如下:
| 字段名 | 类型 | 描述 |
|---|---|---|
| id | VARCHAR(20) | 学号 |
| name | VARCHAR(50) | 姓名 |
| age | INT | 年龄 |
| gender | VARCHAR(10) | 性别 |
| class_name | VARCHAR(50) | 班级名称 |
通过使用面向对象的方式,我们可以将数据库查询的结果映射为 Student 对象。例如,使用 JDBC 查询数据并封装为对象的代码如下:
public List<Student> getAllStudents() throws SQLException {
List<Student> students = new ArrayList<>();
String sql = "SELECT * FROM students";
try (Connection conn = DBUtil.getConnection();
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql)) {
while (rs.next()) {
Student student = new Student(
rs.getString("id"),
rs.getString("name"),
rs.getInt("age"),
rs.getString("gender"),
rs.getString("class_name")
);
students.add(student);
}
}
return students;
}
上述代码中, ResultSet 查询结果通过 Student 类进行封装,实现了对象与数据库记录的映射,提升了系统的可读性和可维护性。
7.2 类与对象之间的协作关系
在系统开发中,为了提高代码的可读性和可维护性,通常采用分层架构设计。常见的分层结构包括控制层(Controller)、业务逻辑层(Service)和数据访问层(DAO)。
7.2.1 控制层、业务层、数据访问层的职责划分
| 层级 | 职责描述 |
|---|---|
| 控制层 | 接收用户请求,调用业务逻辑层处理请求 |
| 业务逻辑层 | 执行具体的业务逻辑,调用数据访问层获取数据 |
| 数据访问层 | 直接操作数据库,完成增删改查等操作 |
例如,一个添加学生的流程如下:
graph TD
A[用户界面] --> B[控制层]
B --> C[业务逻辑层]
C --> D[数据访问层]
D --> E[数据库]
E --> D
D --> C
C --> B
B --> A
这种分层设计使得代码职责清晰,便于团队协作和后期维护。
7.2.2 类之间的调用与依赖管理
以学生信息的查询为例,类之间的调用流程如下:
- 控制层类 (StudentController.java):
public class StudentController {
private StudentService studentService = new StudentService();
public void showAllStudents() {
List<Student> students = studentService.getAllStudents();
for (Student student : students) {
System.out.println(student);
}
}
}
- 业务层类 (StudentService.java):
public class StudentService {
private StudentDAO studentDAO = new StudentDAO();
public List<Student> getAllStudents() {
return studentDAO.getAllStudents();
}
}
- 数据访问层类 (StudentDAO.java):
public class StudentDAO {
public List<Student> getAllStudents() {
// 调用 JDBC 查询数据库
return new ArrayList<>();
}
}
通过这种类之间的调用关系,系统实现了低耦合、高内聚的设计原则,便于后期的扩展与维护。
简介:学生管理系统是一种用于管理学生基本信息、成绩、出勤和课程安排的应用软件,广泛应用于教育机构。本系统代码实现学生信息管理的核心功能:增删改查。通过数据库操作(如SQL语句),系统可添加学生记录、删除无效数据、更新信息以及多条件查询。系统采用面向对象设计和MVC架构,使用MySQL或SQLite等关系型数据库,注重代码可维护性、扩展性与安全性。本项目适合软件开发初学者实践数据库操作、前后端交互及权限控制等内容,是掌握基础管理系统开发的理想入门项目。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









