







 本文深入探讨了深度学习中的优化器选择,包括批量梯度下降(BGD)、随机梯度下降(SGD)、小批量梯度下降(MBGD)及其优缺点。针对训练过程中的挑战,文章介绍了Momentum和Nesterov Accelerated Gradient优化器,以及Adagrad、RMSProp和Adam等自适应学习率方法,帮助提高模型训练效率和准确性。
本文深入探讨了深度学习中的优化器选择,包括批量梯度下降(BGD)、随机梯度下降(SGD)、小批量梯度下降(MBGD)及其优缺点。针对训练过程中的挑战,文章介绍了Momentum和Nesterov Accelerated Gradient优化器,以及Adagrad、RMSProp和Adam等自适应学习率方法,帮助提高模型训练效率和准确性。
最近在优化自己的循环神经网络时,用到了很多优化算法,所以在这里梳理一下,也算是总结。
关于优化器:
其实机器学习训练过程中的本质就是在最小化损失,而在我们定义了损失函数后,优化器就派上了用场,在深度学习中,我们通常就是对于梯度优化,优化的目标就是网络模型里的参数θ(是一个集合,θ1、θ2、θ3 ……)。
(我们设,一般的线形回归函数的假设函数是:
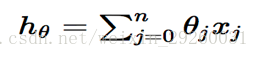
对应的损失函数是:
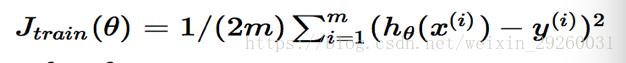 )
)
**
1. 常见的三个优化器(BGD,SGD,MBGD)
**
(1): Batch Gradient Descent (BGD)
批量梯度下降法,也是梯度下降法最基础的形式,算法的思想是在更新每个参数的时,都使用所有样本进行更新:
数学形式如下:
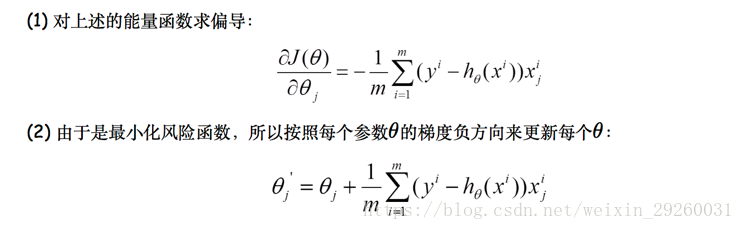
上述也说到了,批量梯度下降每迭代一步,是需要用到训练集的所有数据,如果样本数目很大,速度就会很慢,所有随机梯度下降(SGD)也就顺理成章的引入。
所以关于BGD的优缺点总结如下:
优点:全局最优解;易于并行实现;从跌代次数上来说,BGD
的迭代次数比较少。
缺点:当样本数目很多时,训练过程会很慢
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









