







简介:《TCP/IP详解卷一:协议》是网络通信领域的经典著作,详细介绍了TCP/IP协议族的基础知识,包括互联网发展、网络层次模型、IP协议、ICMP、ARP、TCP、UDP、DNS等协议,以及数据封装、路由与路由器操作。本书为IT从业者、网络工程师等提供了全面的网络通信核心原理,通过实例和实验加深理解,对网络架构设计、性能优化和问题排查具有重要指导意义。 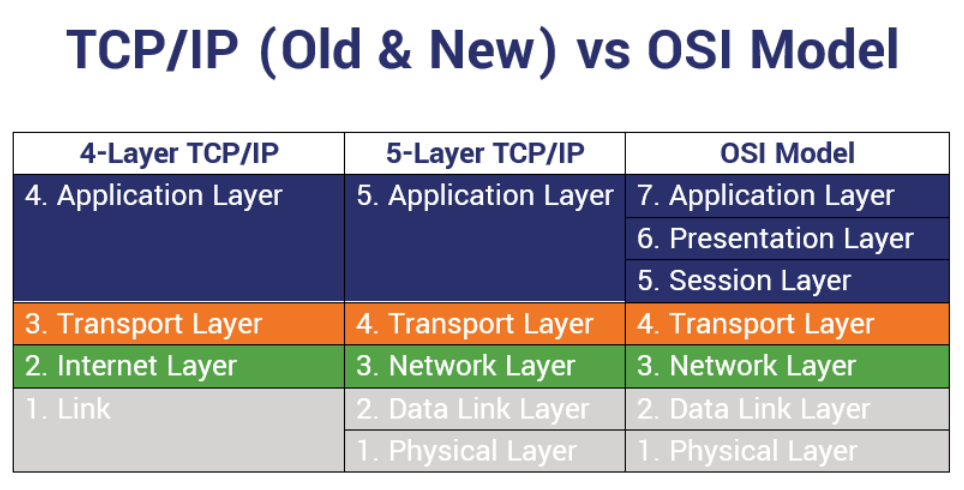
1. 网络概念与历史背景
网络技术作为现代通信的基石,其发展历程和基本概念对IT专业人员来说至关重要。在本章中,我们将探讨网络的基本定义,以及它如何从早期的简单连接演变为现代复杂的全球互联网。
1.1 网络的基本概念
计算机网络是由多个设备(计算机、服务器、打印机等)组成的集合,这些设备通过传输介质(如电缆、光纤)和网络硬件(如交换机、路由器)连接起来,以实现数据的共享和通信。网络技术允许我们跨越物理界限,实现信息的即时交换,极大地方便了人们的生活和工作。
1.2 网络的历史发展
最早的计算机网络起源于20世纪60年代的ARPANET,它是美国国防部高级研究计划局(ARPA)的产物。随着技术的进步,特别是TCP/IP协议的普及,网络经历了从局域网(LAN)到广域网(WAN),再到因特网(Internet)的演变。今天,网络已经成为了现代社会不可或缺的一部分。
1.3 网络的分类和应用
网络可根据覆盖范围分为个人区域网络(PAN)、局域网(LAN)、城域网(MAN)和广域网(WAN)。不同的网络类型有不同的设计目的和应用场景,如家庭网络、企业内部网络和全球互联网连接。理解这些分类有助于我们更好地管理和优化网络资源。
计算机网络在人类社会中扮演着越来越重要的角色,从家庭娱乐到国际商务交流,无处不在的网络连接着世界各地的计算机和设备。随着技术的不断进步,网络技术将如何继续发展和革新,是值得每个IT专业人士关注和思考的问题。
2. 网络层次模型及OSI和TCP/IP
2.1 网络模型的理论基础
2.1.1 OSI模型的七层架构
开放系统互连(OSI)模型由国际标准化组织(ISO)提出,旨在促进不同厂商和不同技术的设备之间的互操作性。OSI模型将网络通信过程划分为七层,每一层都有其特定的功能和协议。
- 物理层(Layer 1) :负责网络中设备之间的比特流传输,包括电气特性、接口标准、物理连接以及比特同步等。
- 数据链路层(Layer 2) :负责相邻节点之间的可靠数据传输,实现帧的寻址、错误检测、流控制等。
- 网络层(Layer 3) :负责逻辑地址的分配和数据包的路由选择,确保数据包能够跨越多个网络到达目的地。
- 传输层(Layer 4) :提供端到端的数据传输服务,确保数据包的顺序、可靠性和错误校正。
- 会话层(Layer 5) :负责建立、管理和终止会话,控制数据交换的顺序和同步。
- 表示层(Layer 6) :处理数据的格式转换、加密解密、压缩解压缩等。
- 应用层(Layer 7) :直接为应用程序提供服务,负责应用软件的接口和数据表示。
OSI模型是一个理论模型,它为理解和开发网络协议提供了一个清晰的框架,尽管它并没有得到广泛的实际应用,但它在教育和理解网络通信原理方面依然非常重要。
2.1.2 TCP/IP模型的四层架构
与OSI模型不同,TCP/IP模型是实际应用中广泛使用的网络通信模型。它最初由美国国防部高级研究计划局(DARPA)开发,因特网的TCP/IP协议族就是基于此模型的。TCP/IP模型将OSI的七层模型简化为四层:
- 链接层(Link Layer) :类似于OSI的物理层和数据链路层,处理网络接口硬件相关的细节。
- 网络层(Internet Layer) :负责数据包的路由选择,IP协议是这一层的核心。
- 传输层(Transport Layer) :提供端到端的通信,其中TCP和UDP是主要的传输层协议。
- 应用层(Application Layer) :结合了OSI模型的会话层、表示层和应用层,直接为应用程序和用户提供服务。
TCP/IP模型以其简洁性和实用性成为目前因特网的基础框架。实际的网络通信过程都遵循这一模型,因此理解其层次结构对于网络开发者和维护者来说至关重要。
2.1.3 网络模型的比较和优势分析
OSI模型和TCP/IP模型之间存在着明显的差异,但它们也有共同之处。OSI模型的设计更为复杂,每一层都有明确的职责,这使得学习和理论分析更为容易。然而,TCP/IP模型因其实际应用广泛和简洁高效,成为了业界标准。
OSI模型的优势在于其分层明确,有利于教学和学习网络通信的基础。TCP/IP模型则因其高度集成化和优化,减少了开销,使得网络通信更为高效。在实际应用中,TCP/IP模型由于其灵活性和扩展性而得到更广泛的使用。尽管如此,OSI模型在理论上依然具有指导意义,特别是在网络协议设计的初期阶段。
3. IP协议与地址分类、子网掩码、CIDR、IP分片重组
3.1 IP地址的构成与分类
IP地址是互联网协议(Internet Protocol)的核心,用于标识网络中的设备。IPv4和IPv6是目前最常见的两个版本,各自有着不同的特点和应用。
3.1.1 IPv4地址与IPv6地址的特点
IPv4地址由32位二进制数字组成,通常被分为四组,每组8位,并用点分隔成十进制数表示,范围从0.0.0.0至255.255.255.255。由于数量限制,IPv4面临着地址耗尽的问题。
IPv6地址则由128位二进制数字组成,表示为8组,每组16位,用冒号分隔的十六进制数表示,例如2001:0db8:85a3:0000:0000:8a2e:0370:7334。IPv6拥有更大的地址空间,并提供了额外的特性,如地址自动配置和更高效的路由。
3.1.2 公有地址与私有地址的区别
公有地址是互联网上唯一可识别的地址,它们被分配给全球的组织和个人,用于在互联网上进行通信。
私有地址(或内部地址)是在组织内部网络中使用的地址,不允许在互联网上直接路由。常见的私有地址范围有以下三个: - 10.0.0.0 - 10.255.255.255(10.0.0.0/8) - 172.16.0.0 - 172.31.255.255(172.16.0.0/12) - 192.168.0.0 - 192.168.255.255(192.168.0.0/16)
路由器会阻止私有地址进入互联网,但通过网络地址转换(NAT)技术,私有网络可以共享一个公有地址与外界通信。
3.2 子网划分与子网掩码
3.2.1 子网划分的原理
子网划分是将一个较大的网络划分成多个较小的网络的过程,以优化路由和提高安全性。通过在IP地址中借用若干位作为子网标识,可以创建多个子网。每个子网可以拥有自己的广播域,减少广播风暴的影响,改善网络性能。
3.2.2 子网掩码的作用与设置方法
子网掩码是一个32位的数字,与IP地址一起使用,用于指示IP地址中的哪一部分是网络地址,哪一部分是主机地址。在子网掩码中,网络部分由连续的1表示,主机部分由0表示。
例如,一个常用的子网掩码255.255.255.0可以表示为11111111.11111111.11111111.00000000。在配置网络时,必须将IP地址和子网掩码一起设置,以确保设备能够正确地识别网络和主机地址。
3.3 CIDR和无类别域间路由
3.3.1 CIDR的概念与优势
CIDR(无类别域间路由)是一种灵活的IP地址分配方法,它允许网络管理员将IP地址划分为任意大小的子网,而不是受限于传统A、B、C类地址划分。CIDR能够更有效地利用IP地址空间,并减少路由表的大小。
CIDR表示法中,IP地址后面跟着一个斜杠和一个数字,表示网络前缀的长度。例如,192.168.2.0/24表示子网掩码为255.255.255.0的网络。
3.3.2 CIDR的应用实例
假设一个公司拥有一个192.168.2.0/24的网络地址,但只需要划分几个较小的子网。管理员可以使用192.168.2.0/26来创建四个较小的子网,每个子网可以有62个主机地址。
如果需要更多的子网,可以进一步采用更长的前缀,如192.168.2.0/27来划分为8个子网,每个子网有30个可用主机地址。
3.4 IP分片与重组机制
3.4.1 IP分片的原因与方法
由于IP数据包需要在网络中传输,不同的网络技术对数据包的大小有不同的限制。例如,以太网的标准最大传输单元(MTU)是1500字节,如果IP数据包超过这个大小,就需要进行分片(Fragmentation)。
IP分片在发送端进行,路由器不会重新组装分片,只会转发或丢弃。如果分片到达目的地,接收端的系统负责将这些分片重新组合成原始数据包。
3.4.2 分片与重组的网络影响
分片虽然解决了不同网络MTU兼容性的问题,但也引入了一些问题。例如,如果一个分片丢失,整个数据包都会无法使用,需要重新传输,这增加了网络的复杂性和开销。
重组过程在目标主机上完成,需要消耗大量的CPU资源。特别是在主机收到大量分片数据包时,重组会成为性能瓶颈,并可能导致拒绝服务攻击(DoS)。
示例代码
以下是一个简单的Python脚本,用于计算不同子网掩码下的子网数和每个子网的主机数。
import ipaddress
def calculate_subnets(network, mask_bits):
network = ipaddress.IPv4Network(network, strict=False)
subnet_count = 2 ** (mask_bits - network.prefixlen)
hosts_per_subnet = 2 ** (32 - mask_bits) - 2 # Subtract 2 for network and broadcast addresses
return subnet_count, hosts_per_subnet
network_address = '192.168.2.0'
mask_bits = 26
subnets, hosts = calculate_subnets(network_address, mask_bits)
print(f"Subnet count: {subnets}")
print(f"Hosts per subnet: {hosts}")
在这个例子中,我们为192.168.2.0/26计算了子网数量和每个子网的主机数。输出结果将显示出我们可以得到4个子网,每个子网有62个可用的主机地址。
通过这段代码,我们可以快速地进行各种子网划分的计算,帮助网络管理员在规划网络时做出更明智的决策。
4. ICMP协议在网络诊断中的应用
4.1 ICMP协议基础
4.1.1 ICMP协议的功能与重要性
ICMP(Internet Control Message Protocol,因特网控制消息协议)是TCP/IP协议族中的重要组成部分,主要用于在IP主机、路由器之间传递控制消息。控制消息包括数据报无法传递时的错误信息,以及网络拥塞的通知等。ICMP不传输数据报本身,只报告控制消息,因此它对于网络的维护和诊断是非常重要的。网络管理员和用户都可以利用ICMP消息进行网络故障的诊断和解决,例如使用ping命令检测主机可达性,或者使用traceroute命令跟踪数据包的路径。
4.1.2 ICMP报文的类型与格式
ICMP报文由两部分组成:ICMP报文头和数据。报文头包含类型(type)、代码(code)、校验和(checksum)等字段。类型字段标识了报文的类型,例如请求回显应答的类型是0,目的网络不可达是3等。代码字段提供了特定于类型的信息。校验和用于错误检测。
ICMP报文格式:
+---------------------------------------+
| Type (1 Octet) | Code (1 Octet) |
+---------------------------------------+
| Checksum (2 Octets) |
+---------------------------------------+
| Message Body (Variable) |
+---------------------------------------+
4.2 ICMP在网络诊断工具中的应用
4.2.1 Ping命令与ICMP回显请求
Ping(Packet Internet Groper)命令是一种使用ICMP回显请求和回显应答消息的网络诊断工具。它的主要目的是测试目标主机的可达性,同时也可以用来测量数据包往返时间(RTT)以及数据包丢失率。
在Linux或Unix系统中,执行ping命令的格式如下:
ping [options] destination
例如,使用ping命令测试主机的可达性:
ping -c 4 www.example.com
这里 -c 4 参数表示发送四个回显请求数据包。执行后,我们可以看到RTT和数据包丢失的统计信息,如:
PING www.example.com (192.0.2.1): 56 data bytes
64 bytes from 192.0.2.1: icmp_seq=0 ttl=56 time=20.830 ms
64 bytes from 192.0.2.1: icmp_seq=1 ttl=56 time=13.314 ms
64 bytes from 192.0.2.1: icmp_seq=2 ttl=56 time=12.281 ms
64 bytes from 192.0.2.1: icmp_seq=3 ttl=56 time=12.669 ms
--- www.example.com ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max/stddev = 12.281/14.774/20.830/3.302 ms
4.2.2 Traceroute命令与路径追踪
Traceroute(Windows系统中称为tracert)是一个用来追踪IP数据包在网络中到达目的地所经过的路由的网络诊断工具。它通过设置IP数据包的生存时间(TTL)字段为逐渐增大的值,迫使沿途的每个路由器(或跃点)发送ICMP超时消息回源地址。
在大多数Unix和Linux系统中,Traceroute命令的执行方式如下:
traceroute [options] destination
例如,跟踪到目的地 www.example.com 的路由:
traceroute www.example.com
输出结果将展示到达目的地之前的数据包所经过的每个路由器的IP地址和往返时间,例如:
traceroute to www.example.com (192.0.2.1), 30 hops max, 60 byte packets
1 router1.example.net (192.168.1.1) 1.089 ms 1.008 ms 1.116 ms
2 router2.example.net (192.168.100.1) 8.123 ms 7.987 ms 8.033 ms
3 192.0.2.1 (192.0.2.1) 9.054 ms 8.987 ms 8.876 ms
通过这些ICMP消息,我们可以详细了解数据包在网络中的路径,以及潜在的问题所在,如某个路由器响应超时可能表明网络拥塞或设备故障。
5. ARP协议和IP地址到MAC地址的转换
5.1 ARP协议的作用与工作原理
地址解析协议(ARP)是互联网协议套件的一部分,它负责将网络层的逻辑地址(即IP地址)转换为链路层的物理地址(即MAC地址)。ARP在局域网通信中扮演着至关重要的角色,因为它解决了如何找到同一局域网内其他主机和路由器接口的MAC地址问题。
5.1.1 ARP表的构建与查询过程
为了理解ARP的工作原理,先来看ARP表的构建与查询过程。ARP表存储在局域网内的每台设备中,表中记录了IP地址和对应的MAC地址的映射关系。每台设备都会定期或在需要时查询ARP表,以获取目的地的MAC地址。
当一台设备需要发送数据给局域网内的另一台设备,它首先查看ARP表,以确定目的IP地址是否对应到一个MAC地址。如果找到了,就会使用这个MAC地址封装数据帧并发送。如果ARP表中没有找到,设备将发送一个ARP请求广播包,询问局域网内谁拥有该IP地址,拥有这个IP地址的设备会回应一个ARP响应,从而建立起映射关系。
5.1.2 ARP请求与响应机制
ARP请求是一个广播消息,它被发送到局域网中的所有设备。请求中包含了询问设备的MAC地址和IP地址。当目标设备接收到这个请求后,它会通过ARP响应向请求者发送自己的MAC地址。响应消息是单播的,直接发送给请求者,而不是广播。
这一过程可以使用以下代码示例来模拟ARP请求和响应的过程。注意,这里仅为了演示ARP协议的工作机制,并非实际网络通信中使用的代码。
import scapy.all as scapy
def send_arp_request(target_ip):
# 创建ARP请求包
arp_request = scapy.ARP(pdst=target_ip)
broadcast = scapy.Ether(dst="ff:ff:ff:ff:ff:ff")
arp_request_broadcast = broadcast / arp_request
# 发送ARP请求并获取响应
answered_list = scapy.srp(arp_request_broadcast, timeout=1, verbose=False)[0]
return answered_list
def main():
target_ip = input("请输入目标IP地址:")
answers = send_arp_request(target_ip)
if len(answers) > 0:
for sent, received in answers:
print(f"从{received[scapy.ARP].psrc}收到了ARP响应,MAC地址是{received[scapy.Ether].src}")
else:
print("没有收到ARP响应")
if __name__ == "__main__":
main()
执行上述代码,可以模拟一个设备发送ARP请求,并打印出响应的MAC地址。在真实的网络环境中,ARP的响应是由网络设备自动完成的。
5.2 ARP欺骗与网络安全
ARP协议虽然在网络通信中起着关键作用,但也存在安全风险。ARP欺骗攻击是一种常见的网络攻击手段,攻击者通过发送伪造的ARP响应包,试图使其他设备相信攻击者的MAC地址与局域网中某个特定IP地址相对应。
5.2.1 ARP欺骗的原理与影响
ARP欺骗利用了局域网内设备对ARP响应的盲目信任,攻击者可以将自己伪装成网关,从而截获经过该网关的所有数据流,进行监听或篡改。这种攻击可以用来实施中间人攻击(MITM),对网络通讯安全构成严重威胁。
5.2.2 防止ARP欺骗的策略
为了减轻ARP欺骗的风险,可以采取多种措施。首先是静态ARP表项的维护,即在设备中预先设置好IP地址和MAC地址的静态映射,这样设备就不会对ARP响应做出反应。此外,使用动态ARP检查(DAI)技术,网络设备可以验证ARP响应包的有效性。还有使用加密技术,比如IPsec,以确保数据传输的安全。
网络管理员可以通过网络设备或防火墙设置来实现这些策略。例如,在Cisco路由器中,可以使用 arp access-list 命令来定义一个访问控制列表(ACL),仅允许特定的ARP响应通过。
通过这一系列的措施,可以有效减少ARP欺骗攻击的风险,提高网络安全。接下来的章节将继续探索如何通过其他协议和工具来维护网络安全,例如ICMP协议在网络诊断中的应用,以及如何有效利用DNS协议来提高网络的健壮性和可用性。
6. TCP协议的连接建立与关闭机制
6.1 TCP三次握手过程详解
在讲述TCP三次握手之前,首先需要明确TCP是一种面向连接的、可靠的传输层通信协议。它通过提供一种数据传递服务,确保数据包能够准确无误地送达目标。TCP连接的建立过程,即三次握手,是保证双方可靠通信的必要步骤。
6.1.1 连接建立的步骤与原理
三次握手过程涉及三个步骤,以下是一个简化的描述:
- 第一次握手 :客户端向服务器发送一个同步序列编号(SYN)包,进入
SYN_SEND状态。 - 第二次握手 :服务器收到客户端的SYN包后,回复一个确认应答(ACK)和一个同步序列编号(SYN)包,表明服务器同意建立连接,此时服务器进入
SYN_RECV状态。 - 第三次握手 :客户端收到服务器的ACK和SYN包后,向服务器发送一个确认应答(ACK),进入
ESTABLISHED状态。服务器收到这个ACK后,同样进入ESTABLISHED状态。
通过这三个步骤,客户端和服务器之间建立起了连接。三次握手确保了双方都准备就绪,并且确认了彼此的初始序列号,为后续的数据传输奠定了基础。
6.1.2 状态转换与异常处理
在TCP的三次握手过程中,涉及到的状态转换和异常处理对于网络的稳定性至关重要。每个握手步骤都可能遇到不同的异常情况,例如超时、收到非法数据包等。TCP通过重传机制和定时器来处理这些异常,确保连接的稳定建立。
例如,如果客户端在等待服务器的第二次握手时超时,则会重发第一次握手的SYN包。如果服务器收到非法的SYN包,则会发送一个重置(RST)包,并关闭连接。
sequenceDiagram
participant C as 客户端
participant S as 服务器
C ->> S: SYN [seq=x]
Note right of S: SYN_SENT
S ->> C: SYN [seq=y], ACK [ack=x+1]
Note right of S: SYN_RECV
C ->> S: ACK [ack=y+1]
Note right of S: ESTABLISHED
如上图所示,Mermaid格式流程图形象地展示了TCP三次握手的步骤。
6.2 TCP连接的终止与四次挥手
连接终止过程,即四次挥手,是TCP协议用来结束一个已经建立的连接的过程。这个过程允许双方平滑地关闭连接,并且确保所有数据都能够被正确发送和接收。
6.2.1 连接终止的过程与原因
连接终止通常由任一方发起,它包括以下四个步骤:
- 第一次挥手 :主动关闭方发送一个FIN包,表示没有数据要发送了,进入
FIN_WAIT_1状态。 - 第二次挥手 :被动关闭方回复一个ACK包,确认收到了FIN包,并进入
CLOSE_WAIT状态。 - 第三次挥手 :被动关闭方在完成所有数据传输后,发送自己的FIN包,进入
LAST_ACK状态。 - 第四次挥手 :主动关闭方收到FIN包后,发送ACK包确认,并进入
TIME_WAIT状态。等待足够的时间(2倍的MSL,Maximum Segment Lifetime)后,关闭连接。
6.2.2 状态转换与半关闭连接
在TCP连接关闭的过程中,每个状态的转换都是为了确保数据传输的完整性。半关闭连接状态(如 FIN_WAIT_1 和 CLOSE_WAIT )允许一方停止发送数据,但继续接收数据,直到所有数据都被成功接收和处理。
当主动关闭方收到被动关闭方的ACK后,如果之前没有设置SO_LINGER选项,TCP会直接进入 TIME_WAIT 状态,等待一段时间以确保所有的数据包都已过期,防止重复的数据包被错误地传送至下一个连接中。
在某些情况下,TCP连接会直接进入 CLOSING 状态,这发生在主动关闭方发送FIN后立即收到对方的FIN,表明双方几乎同时发起关闭连接的操作。
通过以上解释,我们可以看到TCP协议通过三次握手和四次挥手确保了数据传输的可靠性和稳定性。这为复杂的网络通信提供了一个坚实的基础,支持了互联网上各种应用的正常运行。
简介:《TCP/IP详解卷一:协议》是网络通信领域的经典著作,详细介绍了TCP/IP协议族的基础知识,包括互联网发展、网络层次模型、IP协议、ICMP、ARP、TCP、UDP、DNS等协议,以及数据封装、路由与路由器操作。本书为IT从业者、网络工程师等提供了全面的网络通信核心原理,通过实例和实验加深理解,对网络架构设计、性能优化和问题排查具有重要指导意义。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









