






 本文测试了CUDA在ANSYS FLUENT中的加速效果,发现GPU加速对耦合求解器计算效率提升显著,3060ti可达3倍,1080ti约为2倍。然而,对于分离式求解器,加速效果不明显,可能因网格数少,GPU加速优势被CPU-GPU交互时间抵消。FLUENT支持CUDA加速并能提高计算速度,但最佳线程数和GPU选择对效率有影响。
本文测试了CUDA在ANSYS FLUENT中的加速效果,发现GPU加速对耦合求解器计算效率提升显著,3060ti可达3倍,1080ti约为2倍。然而,对于分离式求解器,加速效果不明显,可能因网格数少,GPU加速优势被CPU-GPU交互时间抵消。FLUENT支持CUDA加速并能提高计算速度,但最佳线程数和GPU选择对效率有影响。
太长不看版本,结论如下:
1. FLUENT中,GPU加速对于耦合求解器计算十分明显,3060ti能够提高计算效率约3倍,1080ti能够提高计算效率约2倍;
2. FLUENT中,GPU加速对于分离式求解器效果不明显,这可能是由于网格数太少,GPU对线性系统加速节约的时间,和CPU与GPU之间信息交互额外耗时差不多相抵消,求解系统越庞大,GPU加速才会明显;
3. 分离式求解器是默认关闭GPU加速,需要通TUI命令开启,同时仅建议只对压力方程求解开启GPU加速;
4. FLUENT中,不同线程数对计算影响较大,对CPU主频反而敏感。
针对科学计算的GPU加速技术在过去十多年里得到巨大发展,其主要依赖于GPU性能的提升。过去,如果要搞深度学习,或者数值计算系统求解的GPU加速,通常只能使用专用计算卡,包括Quadro系列、Tesla系列等。然而,随着皮衣刀客黄仁勋发布30系显卡,旗舰卡3090有着比TITAN更高的性价比,过去“四路泰坦抱回家”的梗总算能改成“3090抱回家”了。GPU加速不在依赖于高端计算卡,即便是30系的甜品卡3060ti也有着4864个cuda核心,昔日卡皇2080ti仅有4352个cuda核心,而上上代老卡皇1080ti只有3584个cuda核心。几年前,仅1080ti显卡就要近一万元,今天,花1/3的价钱就能买一张性能超过1080ti的3060ti显卡,兼顾市面上大多数游戏和部分科学计算的使用。对数值计算来说,特别是线性系统的求解,GPU有着天生优势,通常能够节约几倍计算时间。可以说,硬件的进步也让科研和工程吃上了红利。以下,测试3060ti显卡在ANSYS FLUENT中GPU加速效果。
ANSYS FLUENT中的GPU加速
FLUENT很早的版本就支持GPU加速了,不过,用这个的人肯定不多。开启GPU加速也很简单,在启动界面选择即可。此外,针对耦合求解器,GPU加速默认是针对耦合系统进行求解,默认使用FGMRES算法(弹性广义最小残差求解器,一种克罗里克子空间迭代法的衍生)。对于分离式求解器,GPU加速默认不使用(启动界面开启也没用),需要单独通过GUI命令进行设置。ANSYS官方文档表示,FLUENT在GPU上运行的速度最高提升 3.7 倍,从而将求解时间从数周大幅缩短到数天。此外,官方也表示ANSYS FLUENT软件支持在NVIDIA GPU上进行求解器计算。这可帮助工程师减少探索许多设计变量所需的时间,以及按照最终设计期限优化产品性能。代数多重网格求解器和辐射传热模型(包括离散坐标 (DO) 辐射和S2S视角系数计算)现在由GPU加速处理。典型的工业应用包括外流空气动力学、内部流体流动和冷却模拟等。简单总结,FLUENT支持cuda加速,并且能提高几倍效率。
测试案例
之前在论坛找的一个250w网格的经典算例,前段时间大佬们就是用这个算例对比OpenFOAM和FLEUNT计算效率,如下图。本文进行两组实验测试,首先使用耦合求解器进行200时间步长的稳态计算,统计计算时间(total wall-clock time,FLUENT可直接输出)。第二组实验主要是针对分离式求解器的测试,采用SIMPLEC求解器进行200时间步长的稳态计算。

耦合求解器测试
第一次开启GPU加速的时候,计算直接终止了,才发现,原来是显存爆了。GPU加速针对耦合系统默认采用FGMRES算法,在耦合求解器加持下太耗显存,因此将耦合系统GPU求解修改为AMG求解器。可以看到,250万网格的算例,开启GPU加速,显存占用6GB,而3060ti的显存仅有8GB,看来,甜品卡玩加速只能小打小闹,尽管如此,GPU加速测试结果如下。
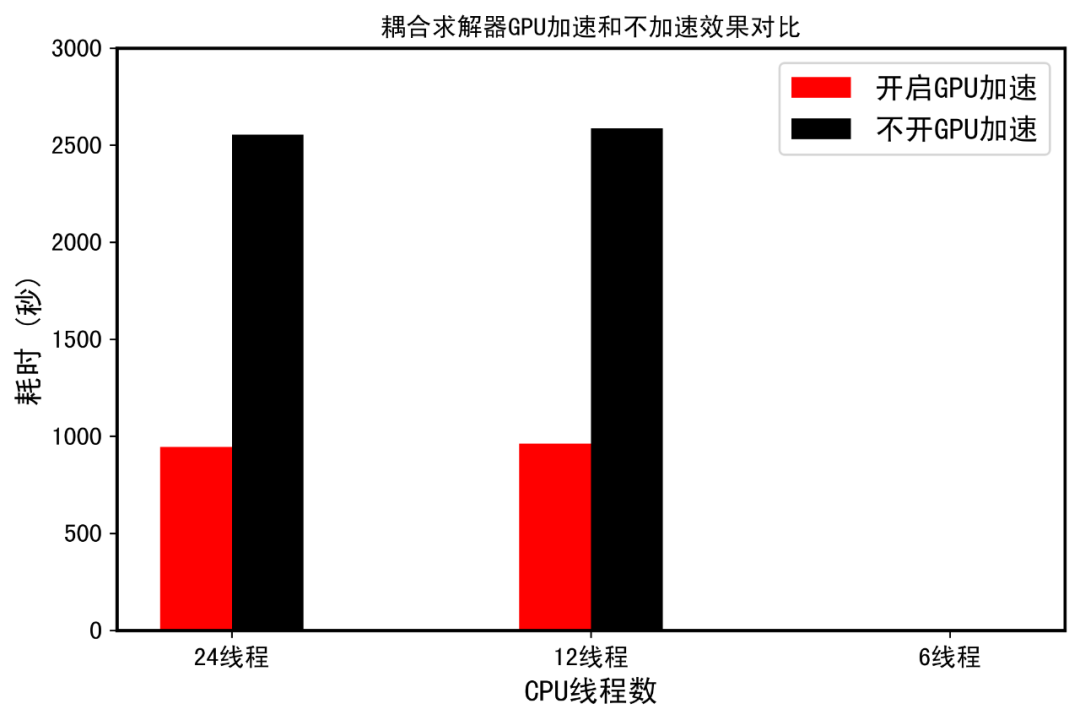
官方说的3倍提升,真的不是吹牛。12线程开启GPU加速,计算时间都低于24线程不开GPU加速。而12线程开启GPU加速,计算总用时居然和24线程开启GPU加速基本一样,仅相差20秒。原因可能是24线程时CPU多核心之间通信时间增加反而拉低了整体效率,最优计算线程数目应该在(20t左右,猜的,关于CPU线程数,并非越多越好,是存在最优线程的,这方面还有不少SCI论文研究,有兴趣自查,该案例的最优CPU线程本文就不研究了)。而12线程不开GPU加速和24线程不开GPU加速跑完200个时间步,都慢的要死,而且用时差不多。看来,对于耦合系统,GPU加速提升的效果有2.7倍左右。尽管没有官方宣传的3.7倍高,这应该和硬件有关,但是GPU加速后提升的效果十分明显的。
分离求解器测试
采用SIMPLEC求解器进行200个时间步长的稳态计算。分离式求解器计算速度比耦合求解器快,这是毋庸置疑的,相当于用稳定性换取了效率。ANSYS官方是不推荐分离式求解器使用GPU加速的。简单的说,耦合求解器大概有60%-70%的时间在进行线性系统计算,采用GPU加速,求解节约的时间相比于CPU和GPU通信的时间是可观的,因此整体效率能够提升。这也是为什么几十万网格的小案例采用GPU加速反而整体效率降低的原因,系统求解时间,多核心之间通信时间,CPU和GPU之间通信时间三者是需要权衡的。此时,如果要开启GPU加速,需要通过TUI进行设置,而且建议,仅对压力方程进行。因此,以下仅对压力方程求解开启GPU加速,采用FGMRES求解器,光顺器ILU,此时,尽管采用了子空间迭代法,但是显存使用仅为2GB,大大低于耦合求解器,但这也从另一个角度说明,此时GPU加速效果不会明显。结果如下图,可以看到加速结果真的不明显。
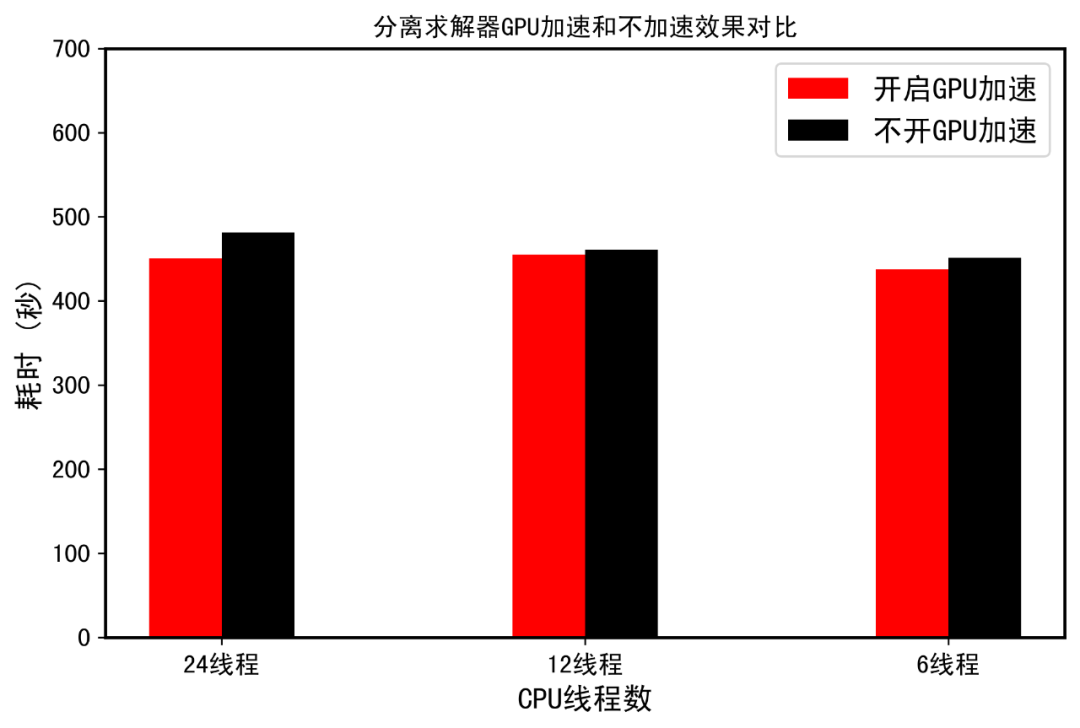
更正,上图横坐标,分别是24线程,18线程,12线程,懒得重做图了。
工作站测试
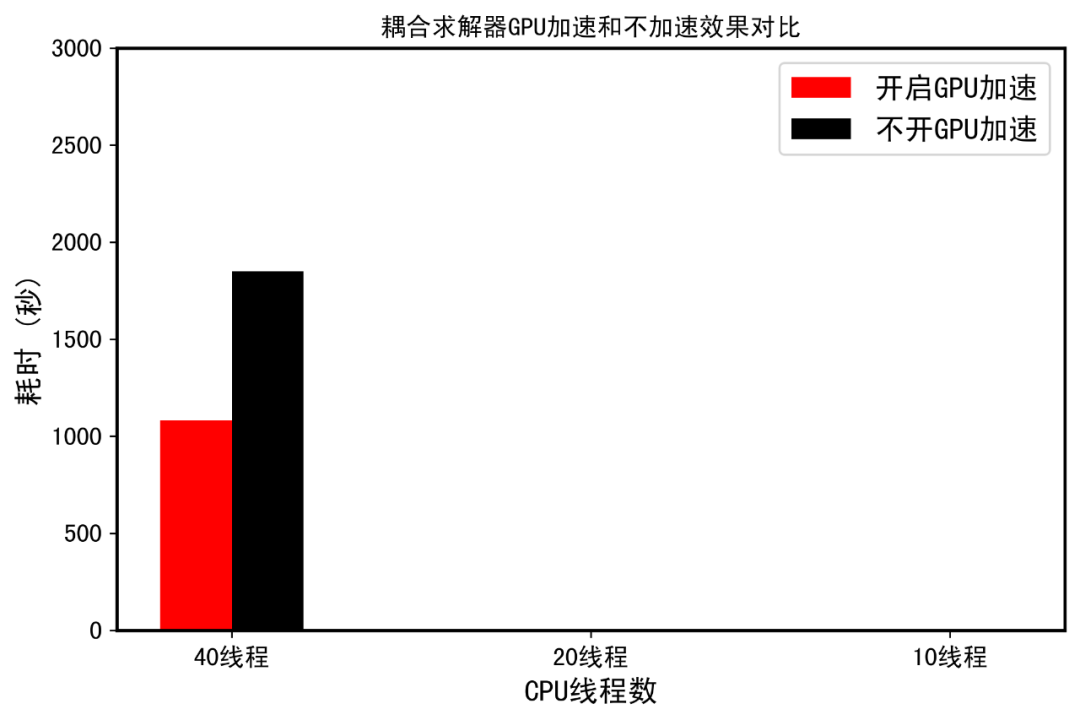
最后简单测试一下1080ti,教研室一台老工作站,配置,志强银4114(20c40t)+老卡皇1080ti。按照测试一中的设置,测试耦合求解器稳态计算下1080ti的加速效果。可以看到,GPU加速效果还是有的,大概有2倍提升,开启GPU加速后,计算效率也低于案例测试一中24线程的测试。但是不开GPU加速,40t的效率还是高于24t的效率,这说明GPU还是有不小差距。不过,上上代老卡皇,还是能打的。要怪就怪绿厂不讲武德,偷袭了上代卡皇同志和上上代老卡皇同志,耗子喂汁。同时,还有一点,24t是采用5900x计算的,全核心4.5Ghz。尽管志强系列主频都太低,但是CFD计算确实不怎么吃CPU主频.此外,我手里的39xt和59x,出现了计算效率一样的情况,尴尬,看来CFD计算真的不吃主频吃核心。还有一种可能,就是FLUENT R2版本是6、7月出来的,并未对新一代AMD进行优化,导致新u和老u计算无差距。
总结
这代GPU加速效果远超预期,这代30系显卡真的是太强了。对于耦合系统,GPU加速开与不开,计算速度完全是两个样子。分离式求解器,如果网格数更多,GPU加速效果肯定更好。GPU加速对于计算效率提升总体还算明显。3060ti都如此,3090具有其2倍cuda核心,20g显存,可以预想,完全能够胜任通常的CFD计算,对于深度学习之类计算也是极其好的,科研利器,唯一缺点就是贵。
平时太忙,导致公众号都成为季更了,下次更新预计明年了,提前祝我的121位粉丝新年快乐。

















 418
418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









