







简介:ELF格式是一种在类UNIX系统中广泛使用的可执行文件和链接格式,用于程序和共享库的表示。它为编译器、链接器、加载器和运行时系统提供统一接口。本文深入探讨了ELF文件的三个主要部分:头部、节区表和节区,以及符号表、重定位表和动态链接等关键特性。此外,还介绍了ELF版本控制和调试信息的重要性,帮助读者全面理解ELF文件的结构和工作原理。 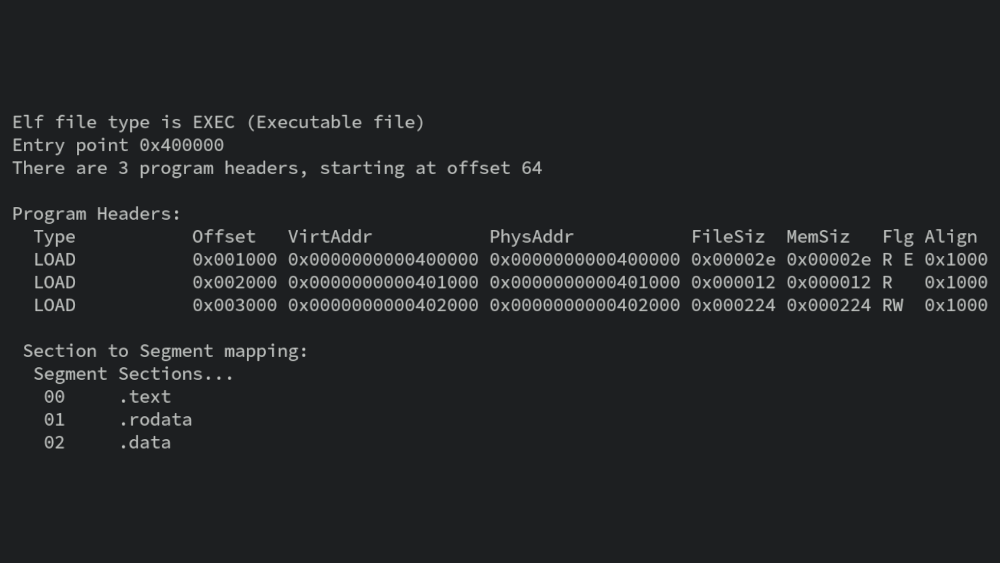
1. ELF格式概述
ELF(Executable and Linkable Format)是一种用于二进制文件、可执行文件、目标代码、共享库和核心转储的标准文件格式。它在Linux、Unix等操作系统中广泛使用,用于保存程序代码和数据,以及提供系统与程序之间的交互信息。
1.1 ELF格式的起源与应用
ELF格式的开发始于1980年代末,最初由Unix System V Release 4(SVR4)采用。随后,由于其结构上的优势,如清晰的分段和易于处理的特性,使其逐渐成为了Unix和Unix-like系统中的标准。ELF文件不仅可以包含可执行代码,还可以包含用于程序链接、重定位等操作的必要信息。
1.2 ELF文件的结构特性
ELF文件通常由三大部分组成:ELF头部(ELF Header)、节区(Section)和节区头部表(Section Header Table)。ELF头部存储了关于文件类型、目标架构和重要地址等元数据;节区则包含了编译后的代码和数据,而节区头部表则用于描述各个节区的属性。这种分层设计使得ELF格式能够支持广泛的平台和功能,包括程序的加载、链接、执行等。
接下来,我们将深入探讨ELF文件的每个部分,以及它们在程序运行和维护中的具体应用。
2. ELF文件三个主要部分解析
2.1 ELF头部解析
2.1.1 头部数据结构
ELF头部是程序中非常重要的部分,提供了识别和理解整个ELF文件所需的基本信息。它包含了文件的类型、架构、入口点地址、程序头部和节头部表的偏移量、大小等关键数据。ELF头部的数据结构由一系列预定义的字段组成,这些字段如下:
-
e_ident:一个字符数组,包含了用于识别ELF文件的一系列字节。 -
e_type:ELF文件类型,比如可重定位文件、可执行文件或共享对象等。 -
e_machine:指明了目标CPU的架构。 -
e_version:文件的版本信息。 -
e_entry:程序的入口点地址。 -
e_phoff:程序头部表的位置偏移量。 -
e_shoff:节头部表的位置偏移量。 -
e_flags:特定于架构的标志位,比如处理器特定的特性。 -
e_ehsize:ELF头部的大小。 -
e_phentsize:程序头部表中每个条目的大小。 -
e_phnum:程序头部表中条目的数量。 -
e_shentsize:节头部表中每个条目的大小。 -
e_shnum:节头部表中条目的数量。 -
e_shstrndx:节名字符串表的索引。
头部信息提供了操作系统和链接器加载和理解ELF文件所需的基础信息。理解这些信息对深入分析ELF文件的结构至关重要。
2.1.2 头部信息的应用场景
头部信息在程序加载和链接过程中起着关键作用。操作系统内核在加载可执行文件时,会首先读取ELF头部来确定如何解析文件其余部分。链接器在链接多个对象文件生成可执行文件时,也会依赖ELF头部中的信息来确定程序的入口点和其他关键设置。
例如,链接器需要知道程序的入口点( e_entry )来设置程序的起始执行地址。此外,链接器在执行符号解析时,会用到 e_phnum 和 e_shnum 来遍历节头部表,而这些表中包含了符号和其他重要信息。
2.2 节区表的组织和结构
2.2.1 节区表的定义与格式
节区表是ELF文件中用于组织各个节(section)的结构,每个节都保存了程序中的特定类型数据。节区表本质上是一个数组,每个元素都是一个节区头部(section header)。节区头部的格式定义了节区的名称、类型、大小、位置等关键信息。
一个节区头部通常包含以下字段:
-
sh_name:节区名称,以节名字符串表中的索引表示。 -
sh_type:节区类型,例如.text表示代码段,.data表示初始化数据段。 -
sh_flags:标志字段,表示节区的属性,比如是否可写、是否包含执行代码等。 -
sh_addr:如果节区需要映射到内存,该字段表示节区在内存中的地址。 -
sh_offset:节区在文件中的偏移量。 -
sh_size:节区的大小(以字节为单位)。 -
sh_link:该节区的关联节区的索引。 -
sh_info:额外信息,根据节区类型的不同含义也不同。 -
sh_addralign:地址对齐要求,用于确定节区在内存中的对齐方式。 -
sh_entsize:如果节区包含固定大小的表项,该字段表示每个表项的大小。
节区表为链接器和加载器提供了必要的数据,使得它们能够正确地处理文件中的各个部分。
2.2.2 节区表在链接过程中的作用
在链接过程中,链接器通过节区表来整合各个输入对象文件中的节区,并解决它们之间的引用。链接器会检查和比较节区头部中的 sh_type 、 sh_flags 和 sh_link 等字段,以确定如何处理每个节区。例如:
- 通过比较不同文件中的
.text节区(代码段)的大小和内容,链接器可以合并它们。 -
.bss节区通常用于存放未初始化数据,链接器会计算其大小,并在最终可执行文件中为其分配相应的空间。
节区表还允许链接器进行优化,比如合并重复的字符串常量到一个节区中,以减少最终文件的大小。节区表的组织对于生成高效、优化的可执行文件至关重要。
2.3 节区的实际内容和作用
2.3.1 常见节区类型及其功能
ELF文件中存在多种标准节区类型,每种类型都有其特定的功能和用途。下面是一些常见节区类型及其功能:
-
.text:程序的代码段,包含了可执行指令。 -
.data:已初始化的全局变量和静态变量。 -
.bss:未初始化的全局和静态变量。这些变量在文件中不占用空间,只在内存中被分配空间。 -
.rodata:只读数据段,例如字符串常量和跳转表。 -
.symtab:符号表,包含了程序中用到的所有符号(函数和变量)的信息。 -
.strtab:字符串表,用于保存符号的名字。 -
.rel.text或.rela.text:用于text节区的重定位信息,记录了需要在链接时修改的指令。
这些节区为程序的运行提供了必要的数据和代码结构。理解这些节区的内容有助于开发者对程序结构和行为有更深入的认识。
2.3.2 节区信息对程序理解的重要性
节区信息不仅是链接器和加载器操作的基础,也是开发者理解程序结构和功能的关键。通过分析节区中的数据,开发者可以确定程序中关键变量的存储位置、代码组织以及程序的内存布局等。
例如, .symtab 节区记录了程序中定义的所有符号。开发者可以利用这些信息,通过符号名来定位代码中特定函数或变量的定义。同样, .strtab 节区中的字符串提供了符号名的文本表示,这在调试过程中尤其有用。
通过分析 .bss 节区的大小,开发者可以了解程序在运行时可能需要多大的堆空间。此外,节区内容还可能包含调试符号信息,这对于开发者定位程序中潜在的错误和优化程序性能非常重要。
以上内容仅是ELF文件三个主要部分解析的概览。要完全掌握ELF格式,还需进一步深入学习每个部分的具体细节,并结合实际的例子来理解它们在程序开发和系统维护中的应用。
3. 符号表和重定位表的作用
3.1 符号表的构成和解读
3.1.1 符号表条目的结构
符号表是ELF文件中记录符号信息的核心结构,其中包含了程序和链接器需要的所有符号定义和引用。符号表条目(Symbol Table Entry)是符号表的基本单元,其结构通常由以下几个部分组成:
- 名称索引(st_name) :一个字节索引,指向字符串表中的符号名称。字符串表是ELF文件中的另一个表,包含了符号和节区的名称等字符串信息。
- 值(st_value) :符号在内存中的地址。对于可重定位对象文件,这个值表示的是符号相对于其所在节区的偏移量。对于可执行文件和共享对象文件,这个值直接表示符号的绝对地址。
- 大小(st_size) :符号的大小,以字节为单位。这可以是数据对象的大小,或者函数代码的长度。
- 绑定(st_info) :符号的绑定类型,指示符号是局部的(非全局可见)还是全局可见的。此外,还指示了符号类型,如函数、对象等。
- 类型(st_other) :符号类型的具体分类,如未初始化数据、已初始化数据等。
- 节区索引(st_shndx) :符号在哪个节区。这个字段为0表示符号未定义或特殊符号,如ABS或COMMON。
3.1.2 符号表在链接中的作用
符号表在链接过程中扮演了至关重要的角色。其主要作用体现在以下几个方面:
- 符号解析 :链接器通过符号表解析不同对象文件间的符号引用。例如,当一个对象文件引用了另一个文件定义的全局符号时,链接器查找符号表来确定符号的定义位置。
- 地址分配 :链接器将符号的相对地址或未定义的引用转换成绝对地址。这包括为程序和库中定义的数据和函数分配运行时地址。
- 符号去重 :链接器需要识别并处理多重定义的符号,将它们合并为一个,或者在发现重复定义时报告错误。
- 动态符号共享 :在创建共享对象时,符号表还会用于确定哪些符号需要被导出,以便其他动态链接的程序可以访问它们。
3.1.3 符号表代码解读示例
下面是一段解析ELF文件符号表条目的伪代码示例:
typedef struct elf32_sym {
uint32_t st_name; // 字符串表中的符号名称索引
uint8_t st_info; // 符号类型和绑定信息
uint8_t st_other; // 保留字节,当前总是0
uint16_t st_shndx; // 符号所在的节区索引
uint32_t st_value; // 符号值(地址或偏移)
uint32_t st_size; // 符号大小(字节)
} Elf32_Sym;
// 读取并处理ELF文件的符号表
void process_symbol_table(Elf32_Ehdr *header) {
Elf32_Sym *symbol_table = (Elf32_Sym *)(header->e_shoff + header->e_shentsize * header->e_shstrndx);
size_t num_symbols = header->e_shnum;
for (size_t i = 0; i < num_symbols; ++i) {
char *symbol_name = (char *)(header->e_shoff + header->e_shstrsize * symbol_table[i].st_name);
// 分析符号的名称、类型、绑定和地址等信息
// ...
}
}
此伪代码展示了如何从ELF文件头获取符号表的位置和大小,并遍历符号表。在真实的应用场景中,链接器会对此进行更为详尽的处理,例如错误检查、符号类型识别和地址解析等。
3.2 重定位表的机制和应用
3.2.1 重定位表的作用和原理
重定位是链接过程中调整程序地址空间的重要步骤。当编译器生成的代码在链接时需要被放置到内存中不同的位置时,就必须要对代码或数据引用进行调整,以确保正确的寻址。
重定位表是ELF文件中专门用于描述重定位信息的表。它包含了需要重定位的符号引用的列表,以及相关的重定位指令和参数。对于每一个需要重定位的符号引用,重定位表都包含了足够的信息以供链接器进行相应的地址调整。
在ELF文件中,重定位表通常位于节区表中,通常有两种类型:
- .rel节区 :包含需要修改的引用的节区的相对重定位信息。
- .rela节区 :比.rel节区更全面,提供了额外的加数字段,用于某些类型的重定位。
重定位类型通常会根据目标架构的不同而有所差异,常见的重定位类型包括:
- R_386_32 :32位绝对地址重定位。
- R_386_PC32 :32位相对偏移重定位。
- R_386_GOT32 :全局偏移表(GOT)的32位偏移重定位。
3.2.2 重定位过程中的常见问题及解决
在实际的编译和链接过程中,重定位可能因为各种原因出现问题。以下是一些常见的问题及其解决策略:
- 符号未定义 :如果链接器发现一个符号引用没有对应的定义,它会报告一个“未定义符号”错误。解决办法通常是检查源代码,确保所有需要的库都正确链接,或在链接器命令中添加相应的库文件。
- 多重定义 :如果一个符号被定义了多次,链接器会报告“多重定义”的错误。这可能是因为源文件中的全局变量或函数被重复定义,或者链接了包含重复定义的库文件。解决办法是检查源代码和库文件,移除重复定义。
- 地址冲突 :链接器在分配地址时可能会发现地址空间的冲突。这通常发生在静态变量或段重叠时。解决办法是重新组织代码或数据,或者使用更小的编译单元。
- 链接脚本问题 :在手动编写链接脚本时,可能会出现配置错误,导致重定位失败。这需要仔细检查链接脚本,确保节区的顺序和布局是正确的。
3.2.3 重定位代码示例和逻辑分析
下面是一段处理ELF文件重定位表的伪代码示例:
typedef struct elf32_rel {
uint32_t r_offset; // 需要重定位的引用的内存位置
uint32_t r_info; // 重定位类型和符号表索引
} Elf32_Rel;
typedef struct elf32_rela {
uint32_t r_offset;
uint32_t r_info;
uint32_t r_addend; // 用于计算最终地址的加数
} Elf32_Rela;
void perform_relocation(Elf32_Ehdr *header) {
// 假设有一个符号表符号和重定位表
Elf32_Sym *symbols = (Elf32_Sym *)(header->e_shoff + header->e_shentsize * header->e_shstrndx);
Elf32_Rel *rel_table = (Elf32_Rel *)(header->e_shoff + header->e_shentsize * header->e_rel);
size_t num_relocations = header->e_relsize / sizeof(Elf32_Rel);
for (size_t i = 0; i < num_relocations; ++i) {
uint32_t sym_index = ELF32_R_INFO_SYMTAB_INDEX(header->e_rel[i].r_info);
uint32_t type = ELF32_R_INFO_TYPE(header->e_rel[i].r_info);
// 根据重定位类型进行不同的处理
switch(type) {
case R_386_32:
// 处理32位绝对地址重定位
// ...
break;
case R_386_PC32:
// 处理32位相对偏移重定位
// ...
break;
// 其他重定位类型
}
}
}
上述代码中,我们定义了两种重定位表条目的结构体,并实现了一个处理ELF重定位表的函数。在实际的链接器实现中,这个函数会更加复杂,并且会涉及地址计算、符号解析等操作。
通过这个示例,我们可以看到重定位过程涉及了对ELF文件中重定位表和符号表的深入解析。链接器会根据这些表中的信息来调整代码和数据,以确保程序的正确执行。
4. 动态链接特性深度解析
4.1 动态链接与静态链接的区别
4.1.1 动态链接的实现机制
动态链接是一种链接方式,在程序运行时,链接被延迟到程序执行期间。与之对应的静态链接则是在程序运行之前就完成了所有的链接工作。动态链接的实现依赖于动态链接库(Dynamic Link Library,DLL),在Linux系统中通常被称为共享对象(Shared Objects,.so文件)。
在动态链接中,程序执行时操作系统负责加载动态库到进程的地址空间中,通过共享内存的方式实现多个进程间的库共享,大大节省了内存资源。动态链接库通过一系列的重定位和符号解析过程完成与可执行文件的链接。
以下是动态链接的几个核心步骤: - 加载动态库 :操作系统负责将动态库加载到进程的地址空间中。 - 符号解析 :动态链接器(Dynamic Linker)根据符号名找到相应符号的地址。 - 地址重定位 :动态链接器对程序中的绝对地址引用进行修改,使其指向动态库中相应的位置。 - 运行时库初始化 :动态库在被加载后,通常会执行初始化代码。
4.1.2 动态链接的优势分析
动态链接相对于静态链接具有如下优势: - 内存使用效率更高 :多个进程可以共享同一个动态库的内存镜像,避免了代码的重复加载。 - 易于维护和升级 :更新动态库时无需重新编译链接整个程序,可以独立升级。 - 灵活的版本控制 :可以根据需要选择使用不同版本的动态库。 - 较小的可执行文件大小 :因为不需要包含库代码,所以可执行文件体积较小。
在特定场景下,静态链接可能更为适合,例如嵌入式系统或某些关键的安全敏感型应用中,因为静态链接可以提供完全自包含的可执行文件,无需依赖外部库。
4.2 动态符号解析过程详解
4.2.1 动态库加载机制
动态库的加载机制涉及到操作系统的加载器。在Linux系统中,动态库的加载通常由动态链接器 ld-linux.so (或 ld-linux-x86-64.so 对于64位系统)完成。这个链接器负责解析可执行文件中的动态链接相关指令,加载必要的动态库,并执行符号解析和重定位操作。
动态库加载过程大致可以分为以下几个步骤: - 解析DT_NEEDED标记 :解析 ELF 文件的动态段中 DT_NEEDED 标记,获取程序所需的动态库信息。 - 加载动态库文件 :根据 DT_NEEDED 提供的信息找到并加载动态库文件。 - 符号解析 :对动态库中的符号进行解析,确定符号地址。 - 地址重定位 :修改程序中的地址引用,使其指向正确的内存位置。 - 执行动态库初始化函数 :在动态库加载完成后,执行其初始化代码。
4.2.2 动态符号解析流程
动态符号解析是动态链接过程中极其重要的一环。解析过程保证了程序能够正确地找到动态库中函数或变量的地址。动态链接器按照一定的顺序来解析符号,这个顺序通常由动态库的依赖关系确定。解析流程大体如下:
- 读取动态段 :动态链接器首先检查可执行文件的动态段(DT_SYMTAB 和 DT_STRTAB),获取符号表和字符串表。
- 解析依赖库 :检查 DT_NEEDED 条目,了解程序所依赖的动态库,按依赖顺序逐一解析。
- 查找符号 :对于符号表中的每个符号,根据符号的类型和名称在对应的动态库的符号表中查找匹配项。
- 符号地址分配 :一旦找到符号的地址,将其分配给程序中的引用。
- 重定位 :根据符号的实际地址修正程序中对该符号的所有引用。
动态符号解析的一个关键挑战是处理符号冲突,这需要链接器有相应的策略来决定如何解决潜在的重复符号问题。不同的系统和链接器可能有不同的解决方案,例如使用“最近优先”的规则来决定使用哪个版本的符号。
通过本章节的介绍,我们对动态链接有了一个全面的理解,从基本的动态链接与静态链接的对比,到动态链接的实现机制,再到动态符号解析流程,每一个环节都是紧密相连、相互支持的。下一章我们将深入探讨ELF版本的演化历程及其对兼容性的影响。
5. ELF版本控制和兼容性管理
5.1 ELF版本的演化历程
5.1.1 主要版本间的差异
ELF(Executable and Linkable Format)标准自1990年代初被首次定义以来,经历了多个版本的演进。从最初的 ELF32 到后来的 ELF64,每个版本的更新都是为了适应硬件发展、提供更多的功能以及改善性能。在早期的 ELF32 版本中,规范主要关注32位系统架构,随着时间的推移,64位处理器变得流行,ELF64 版本应运而生,以支持更大的地址空间。
各个 ELF 版本之间还有一些细微的差异,例如:
- 文件头结构变化 :随着版本更新,ELF 文件头的某些字段可能被修改或扩展,以支持更多的功能或者更复杂的程序结构。
- 节区(Section)和段(Segment)的增强 :每个新版本的 ELF 标准都可能引入新的节区类型或对现有段的属性进行扩展,如增加了用于线程局部存储(Thread-Local Storage,TLS)的节区类型。
- 扩展数据类型 :为了支持更大范围的寻址能力,数据类型,如指针和地址,会从 32 位扩展到 64 位。
5.1.2 版本演化对兼容性的影响
尽管 ELF 标准的演化提供了新的特性和改进,但同时也给软件维护和向后兼容性带来了挑战。编译器和链接器需要支持多个版本的 ELF 格式,以便正确处理不同时期创建的目标文件和可执行文件。操作系统和硬件平台必须适配新的 ELF 版本,以确保新功能能够被正确利用。
在实际应用中,开发者通常需要确保他们的编译器、链接器和库能够处理不同版本的 ELF 文件。这可能涉及到升级工具链,或者编写特殊的处理逻辑来处理不同版本的差异。同时,保持向后兼容性对于确保旧软件能在新系统上运行是至关重要的。
5.2 兼容性管理的策略与实践
5.2.1 兼容性问题的常见原因
在软件开发中,兼容性问题可能源自多种原因。随着操作系统的更新,它们可能会改变系统调用的接口或者改变某些行为,这可能会影响依赖这些调用的程序。此外,编译器版本的变化也可能导致生成的代码在行为上有所差异。库文件的版本变更,尤其是那些提供核心功能的库,它们的接口或内部实现的改变,都有可能导致依赖于旧版本库的应用程序出现问题。
兼容性问题的发生还有可能是由于硬件平台的变化,比如从 32 位迁移到 64 位平台时,地址空间的扩展可能导致一些指针错误。这些问题需要通过明确的版本控制策略和兼容性测试来解决。
5.2.2 兼容性管理的工程实践
为确保软件在不同的环境和平台上保持良好的兼容性,可以采取以下实践策略:
- 版本控制 :为应用程序、库和工具链维护明确的版本号,并记录每个版本的变更点,以便追踪可能影响兼容性的更新。
- 兼容性层 :在系统调用、API 或第三方库接口变化时,可以编写兼容性层来封装变化,以提供与旧版本相同的接口给应用程序。
- 测试和验证 :持续运行自动化测试,特别是兼容性测试套件,来验证新代码或更新是否与旧版本软件兼容。
- 文档和沟通 :在升级关键组件时,确保提供详细的更新日志,并与用户沟通可能影响他们的变更。
为了直观地理解 ELF 版本控制和兼容性管理,可以考虑以下流程图表示软件开发中的兼容性管理流程:
graph LR
A[软件开发开始] --> B[版本控制]
B --> C[变更管理]
C --> D[兼容性测试]
D --> E[发布新版本]
E --> F[用户反馈与沟通]
F --> G[问题修复]
G --> H[更新兼容性层]
H --> I[回归测试]
I --> J[兼容性确认]
J --> K{兼容性是否满足要求?}
K -- 是 --> L[软件维护与更新]
K -- 否 --> M[返回到版本控制]
以上流程图清晰地展示了一个软件项目从开始到发布,并在发布后根据用户反馈进行维护的整个过程。这样的流程有助于确保在软件生命周期中的每个阶段都考虑了兼容性问题,并采取适当的措施来管理和解决它们。
通过上述内容,读者应该对 ELF 版本的演化历程及兼容性管理策略有了深入的理解。在下一章节中,我们将深入探讨 ELF 文件中调试信息的结构及其在软件开发中的重要应用。
6. 调试信息的重要性和应用
在软件开发过程中,调试信息扮演着至关重要的角色。它不仅帮助开发者理解程序的执行流和内存状态,还能在程序出错时快速定位问题。本章将深入探讨调试信息的作用、内容、生成以及应用。
6.1 调试信息的作用和内容
调试信息包含用于理解程序结构和状态所需的所有数据。它不是最终用户执行的二进制文件的一部分,而是由编译器或汇编器生成,并在调试过程中使用。
6.1.1 调试信息的种类与结构
调试信息可以分为以下几类:
- 源代码调试信息 :提供源代码与编译后代码之间的映射,用于断点设置和源代码级调试。
- 符号调试信息 :包含变量、函数等符号的名称和位置,方便开发者了解程序的符号表。
- 行号信息 :记录了源代码中的行号与编译后代码中指令的对应关系。
- 类型信息 :描述了复杂类型结构,如结构体、联合体、类等。
- 优化信息 :如果程序进行了编译优化,优化信息能够帮助调试器理解代码的优化结果,从而更准确地映射回源代码。
调试信息的结构通常采用专门的数据格式,如DWARF(Debugging With Arbitrary Record Formats)是Linux系统中广泛使用的一种调试信息格式。
6.1.2 调试信息在开发中的应用
在开发阶段,调试信息可以帮助开发者:
- 设置断点 :确定源代码中特定行或函数的执行位置。
- 跟踪执行流 :逐步执行程序,查看变量的实时值。
- 分析内存 :检查程序在运行时分配的内存区域。
- 性能分析 :识别程序的瓶颈,优化代码。
- 错误定位 :快速定位程序崩溃或逻辑错误的原因。
6.2 调试信息的生成和使用
调试信息的生成通常与编译器配置有关,而使用调试信息则依赖于调试器工具。
6.2.1 调试信息的生成工具与方法
在生成ELF文件时,编译器选项决定了调试信息的生成与否及其详细程度。GCC编译器使用 -g 选项来启用调试信息的生成。增加 -ggdb 、 -gstabs 、 -gxcoff 等选项可以生成更详细的调试信息,但会增加二进制文件的大小。
生成的调试信息存储在ELF文件的 .debug_* 节中,这些节包括:
-
.debug_info:描述了程序的符号和类型信息。 -
.debug_line:提供了源代码行号与指令的对应关系。 -
.debug_frame:定义了调用栈框架信息。 -
.debug_str:包含调试信息中使用的字符串。
6.2.2 调试信息在问题定位中的实例分析
考虑一个实际例子:在使用GDB调试一个C语言程序时,开发者可能需要查看一个数组的值,这可以通过GDB命令来实现。
首先,编译程序时带上 -g 选项:
gcc -g -o my_program my_program.c
然后,启动GDB并加载程序:
gdb ./my_program
在GDB中设置断点,并运行程序至断点:
(gdb) break main
(gdb) run
当程序执行至 main 函数时,可以查看数组内容:
(gdb) print *my_array@10
上述命令展示了如何打印名为 my_array 的数组的前10个元素的值。在这个过程中,调试信息允许GDB将内存地址映射回 my_array 符号,且 @10 指定了查看数组的前10个元素。
以上步骤不仅展示了调试信息如何在程序运行时被利用,还显示了调试信息在复杂情况(如数组或复杂数据结构)下进行错误追踪和性能分析的实用性。
简介:ELF格式是一种在类UNIX系统中广泛使用的可执行文件和链接格式,用于程序和共享库的表示。它为编译器、链接器、加载器和运行时系统提供统一接口。本文深入探讨了ELF文件的三个主要部分:头部、节区表和节区,以及符号表、重定位表和动态链接等关键特性。此外,还介绍了ELF版本控制和调试信息的重要性,帮助读者全面理解ELF文件的结构和工作原理。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









